
TL;DR: Scaling nodes in a Kubernetes cluster could take several minutes with the default settings. Learn how to size your cluster nodes and proactively create nodes for quicker scaling.
When your Kubernetes cluster runs low on resources, the Cluster Autoscaler provision a new node and adds it to the cluster.
The cloud provider has to create a virtual machine from scratch, provision it and connect it to the cluster.
The process could easily take more than a few minutes from start to end.
During this time, your app is trying to scale and can easily be overwhelmed with traffic because it isn't able to replicate itself.
How can you fix this?
Let's first review how the Kubernetes Cluster Autoscaler (CA) works.
The autoscaler doesn't scale on memory or CPU.
Instead, it reacts to events and checks for any unschedulable Pods every 10 seconds.
A pod is unschedulable when the scheduler cannot find a node that can accommodate it.

However, under heavy load, if the pod is unschedulable, it's already too late.
You can't wait minutes for the node to be created — you need it now!
To work around this issue, you could always configure the cluster autoscaler to provision an extra node instead of being reactive.
Unfortunately, there is no "provision an extra spare node" setting in the cluster autoscaler.
But you can get close with a clever workaround: a big placeholder pod.
A pod that does nothing but triggers the autoscaler in advance.
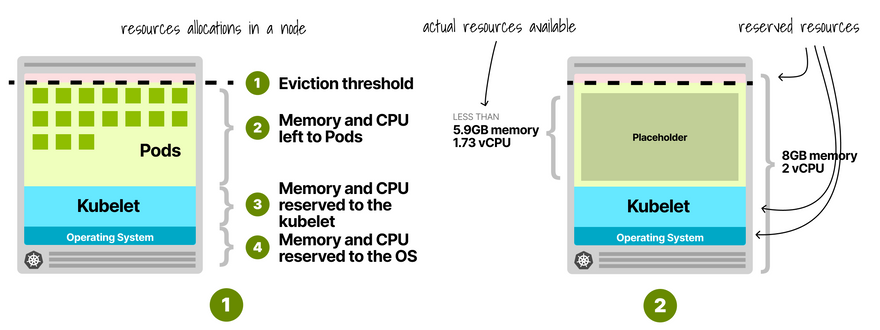
How big should this pod be, exactly?
Kubernetes nodes reserve memory and CPU for kubelet, OS, eviction threshold, etc.
If you exclude those from the total node capacity, you obtain the actual resources allocatable for pods.
You should make the placeholder pod use all of them.
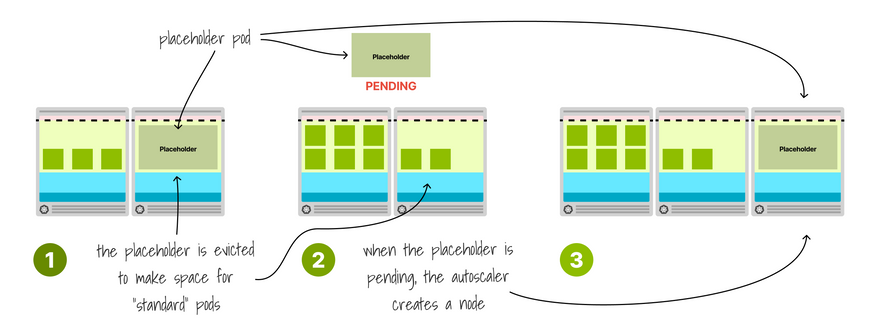
The placeholder pod competes for resources, but you could remove it as soon as you need more space with a Pod PriorityClass.
With a priority of -1, all other pods will have precedence, and the placeholder is evicted as soon as the cluster runs out of space.

What happens when the placeholder evicts because a pod needs to be deployed?
Since it needs a full node to run, it will stay pending and trigger the cluster autoscaler.
That's excellent news: you are making room for new pods and creating nodes proactively.
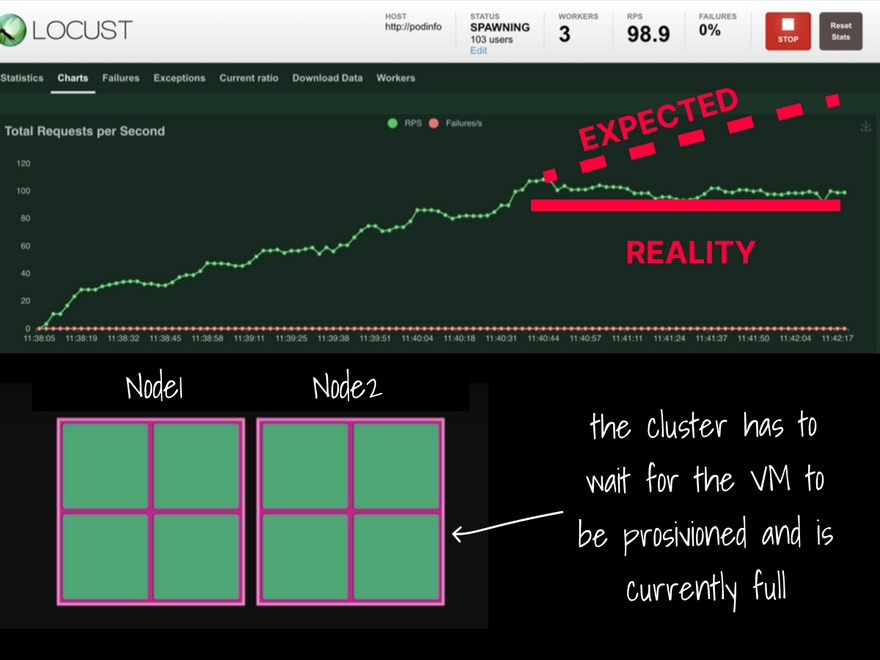
To understand the implication of this change, let's observe what happens when you combine the cluster autoscaler with the horizontal pod autoscaler but don't have the placeholder.
The app cannot keep up with the traffic, and the response flattens.

Compare the same traffic to a cluster with the placeholder pod.
The autoscaler takes half the time to scale to an equal number of replicas.
The requests per second don't flatten but grow with the concurrent users.

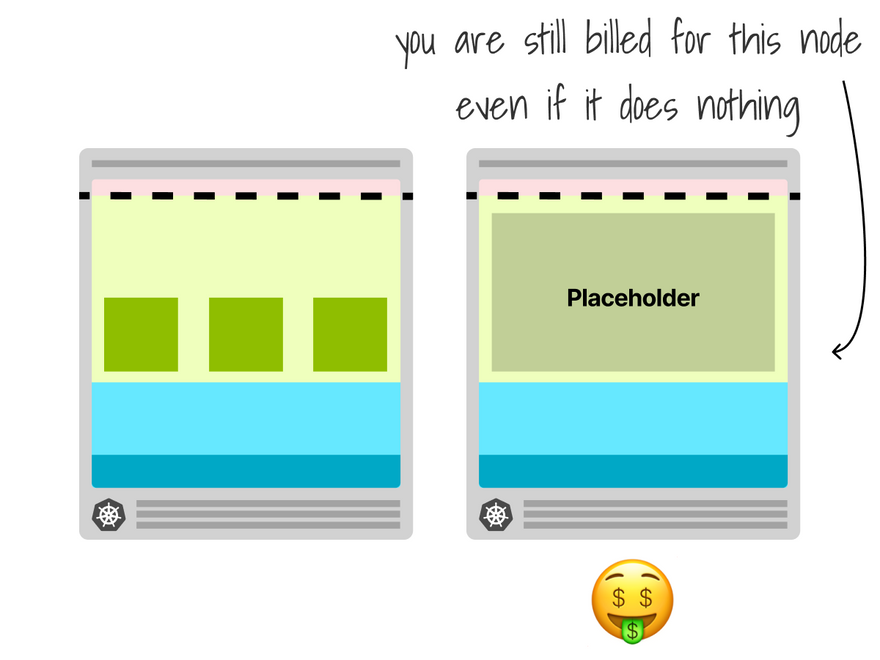
The placeholder makes for a great addition but comes with extra costs.
You need to keep a spare node idle most of the time.
You will still get billed for that compute unit.
And finally, you can make your cluster autoscaler more efficient if you don't use it!
The size of the node dictates how many pods can be deployed.
If the node is too small, a lot of resources are wasted.
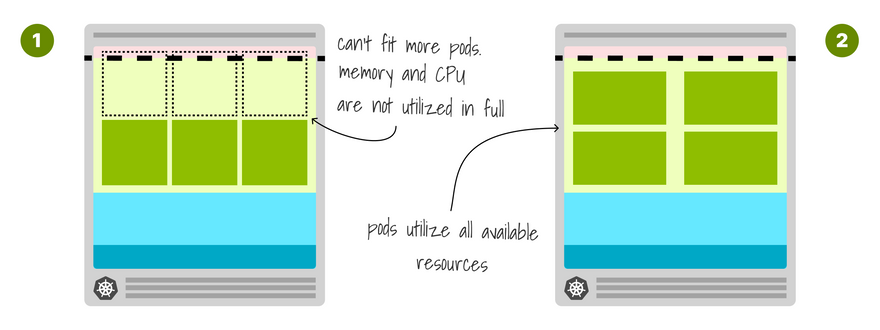
Instead, you could find just the right size for the pod you have so that you fill your instance in total, reducing wasted resources.
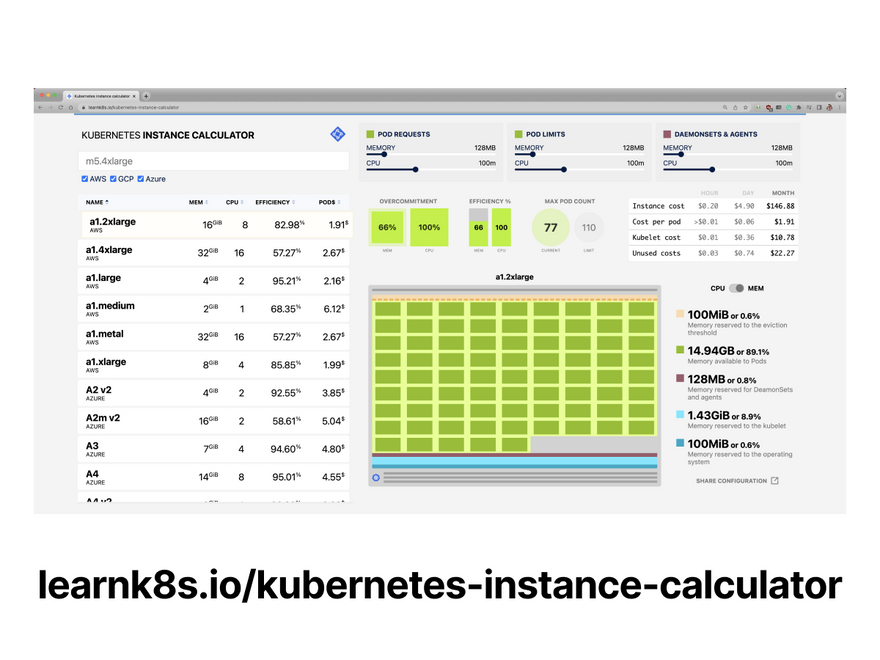
To help with that task, you can try this handy calculator!
https://learnk8s.io/kubernetes-instance-calculator
If you wish to see this in action, Chris Nesbitt-Smith demos the proactive scaling here https://event.on24.com/wcc/r/3919835/97132A990504B699E24A7F809694FC8E?partnerref=learnk8s
And finally, if you've enjoyed this thread, you might also like the Kubernetes workshops that we run at Learnk8s https://learnk8s.io/training or this collection of past Twitter threads https://twitter.com/danielepolencic/status/1298543151901155330
Until next time!

Top comments (24)
The delay in node provisioning is definitely a real bottleneck when traffic spikes suddenly, and the placeholder pod strategy is a smart way to trigger scaling earlier. I’ve seen similar situations where workloads become heavy due to inefficient resource handling, which makes autoscaling even slower. Optimizing how applications consume CPU and memory alongside proactive scaling can make a noticeable difference in performance. For those exploring performance tweaks and workload behavior, this website also be helpful.
Really insightful breakdown especially the placeholder pod workaround. I’ve seen similar latency issues where relying purely on reactive autoscaling caused noticeable traffic drops during sudden spikes. One thing that also helped in my case was planning node sizing more accurately in advance, because inefficient resource allocation makes the delay even worse. I recently came across a helpful approach tmsim that explains how better resource planning and simulation can reduce autoscaling lag alongside techniques like placeholder pods.
Need a qualified and reliable teacher for your child? Share your requirements, class details, subject, and location, and we will help you find the right match according to your educational needs. Our Home Tutor Faisalabad service is designed to provide quick support and a smooth process so students can begin learning without unnecessary delays. Contact Oxford Home Tuition Faisalabad.
Proactive cluster autoscaling in Kubernetes is a fascinating topic—especially as workloads become more dynamic and demand real-time resource optimization. It's impressive how predictive scaling based on historical trends or external metrics can drastically reduce latency and cost. On a lighter note, if you're working on Kubernetes dashboards or internal tooling and want to make labels or UI elements stand out, tools like stylish-names.net/ can help you generate stylish, bold, or fancy text to enhance visual clarity or aesthetics. Small UI tweaks can improve the user experience too!
@Phrazle Instead of asking players to guess a single five-letter word, Phrazle challenges you to solve entire phrases. That one change adds layers of complexity, creativity, and cultural knowledge that make it stand out in a crowded puzzle landscape.
Proactive (predictive) autoscaling means adding capacity before demand hits, instead of waiting for real-time metrics to smash karts unblocked cross thresholds. It reduces cold starts, request queuing, and failed schedules for workloads with predictable or bursty traffic. Below I’ll explain approaches, tools you can use, a simple architecture pattern, pitfalls, and a short example of how to get started.
ToothfairyAI is revolutionizing digital innovation with advanced AI agents in Australia. Our intelligent solutions empower businesses to automate workflows, enhance customer engagement, and boost productivity through cutting-edge artificial intelligence. At ToothfairyAI, we deliver smart, scalable AI technology designed to simplify complex tasks and drive growth for Australian enterprises.
Struggling with bad breath disease in Narre Warren? At Glowing Smiles Dental Clinic, we offer expert diagnosis and effective treatment to restore your fresh breath and confidence. Our friendly team identifies underlying causes like gum disease or poor oral hygiene, offering tailored solutions in a caring environment. Book your consultation today and enjoy lasting oral health. Visit us in Narre Warren for fresher, healthier smiles!
ToothfairyAI is revolutionizing digital innovation with advanced AI agents in Australia. Our intelligent solutions empower businesses to automate workflows, enhance customer engagement, and boost productivity through cutting-edge artificial intelligence. At ToothfairyAI, we deliver smart, scalable AI technology designed to simplify complex tasks and drive growth for Australian enterprises.
Proactive cluster autoscaling in Kubernetes is an exciting area, especially as workloads become more dynamic and require real-time resource optimization. Using predictive scaling based on historical patterns or external metrics can significantly reduce latency while also controlling infrastructure costs.
On a lighter note, when working with Kubernetes dashboards or internal tools, making labels or UI elements more visually distinct can improve usability. Stylish text generators are useful for creating bold or decorative labels that enhance clarity and overall aesthetics. Even small UI improvements can make a noticeable difference in the user experience.