
The scheduler is in charge of deciding where your pods are deployed in the cluster.
It might sound like an easy job, but it's rather complicated!
Let's start with the basic.
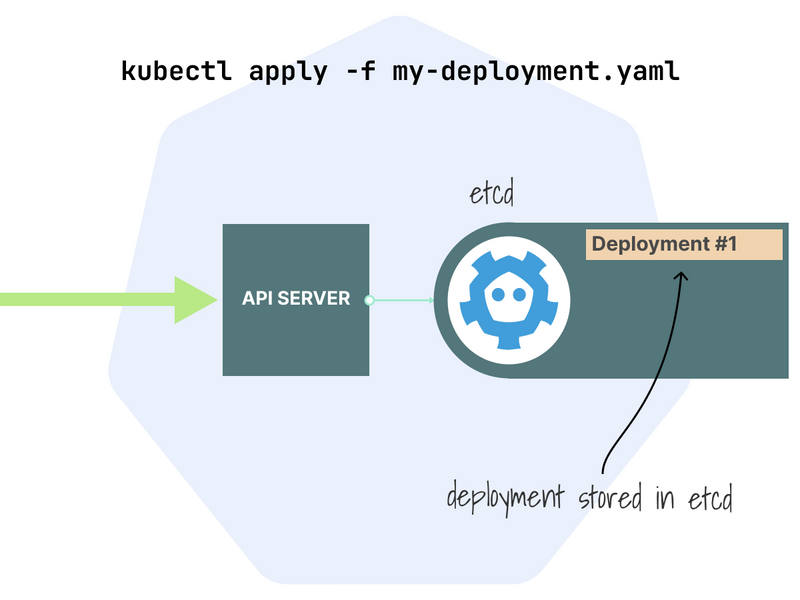
When you submit a deployment with kubectl, the API server receives the request, and the resource is stored in etcd.
Who creates the pods?
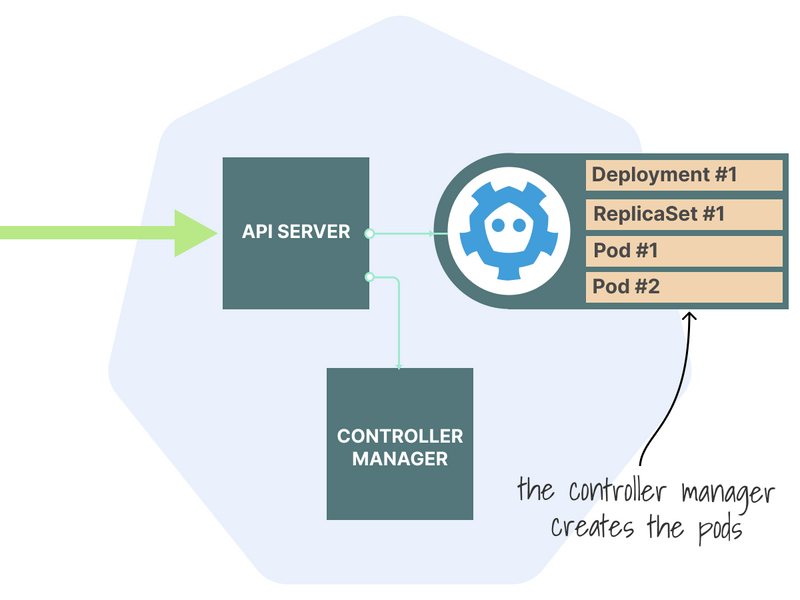
It's a common misconception that it's the scheduler's job to create the pods.
Instead, the controller manager creates them (and the associated ReplicaSet).
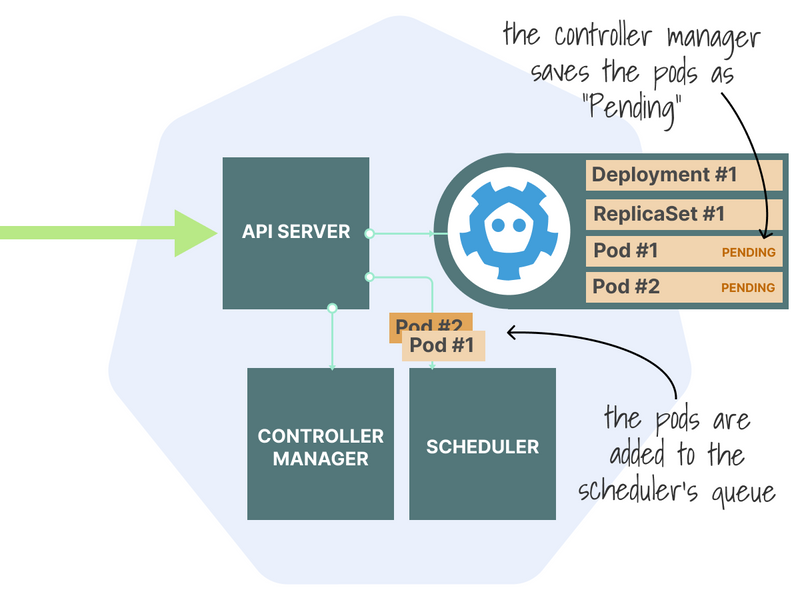
At this point, the pods are stored as "Pending" in the etcd and are not assigned to any node.
They are also added to the scheduler's queue, ready to be assigned.
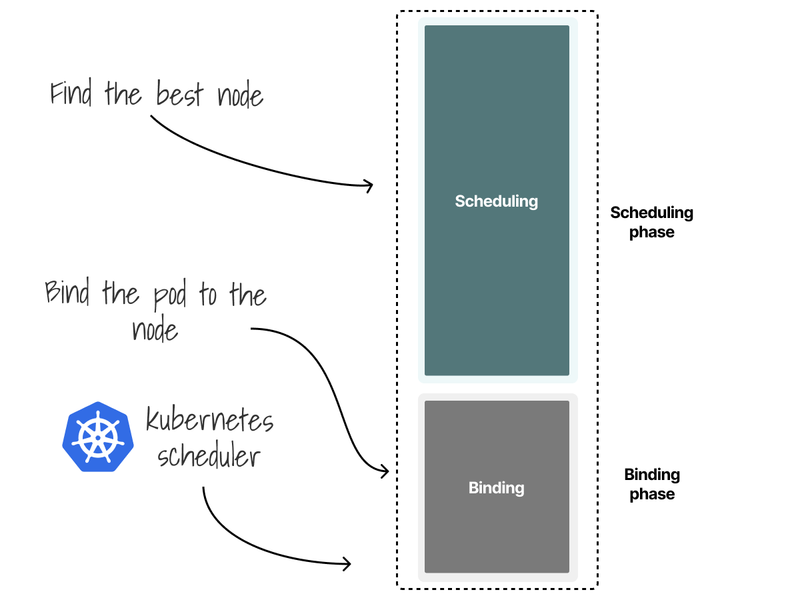
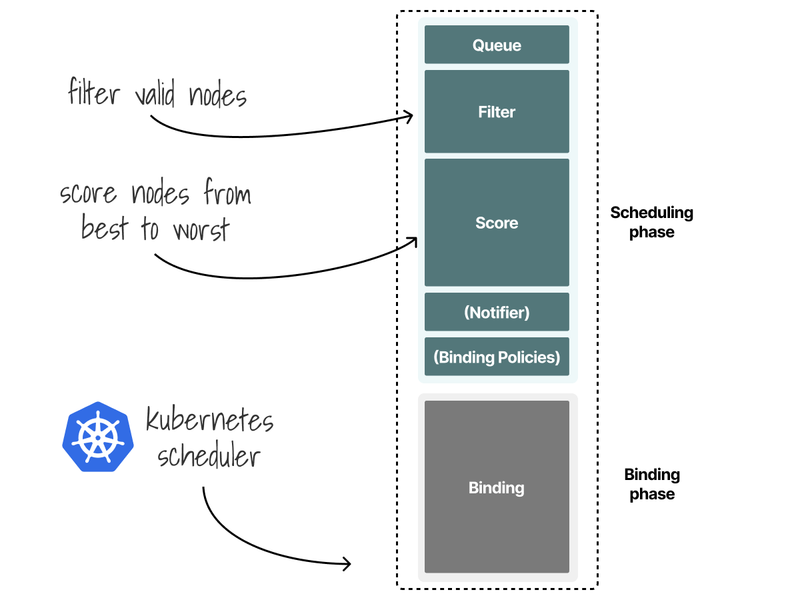
The scheduler process Pods 1 by 1 through two phases:
- Scheduling phase (what node should I choose?).
- Binding phase (let's write to the database that this pod belongs to that node).
The Scheduler phase is divided into two parts. The Scheduler:
- Filters relevant nodes (using a list of functions called predicates)
- Ranks the remaining nodes (using a list of functions called priorities)
Let's have a look at an example.
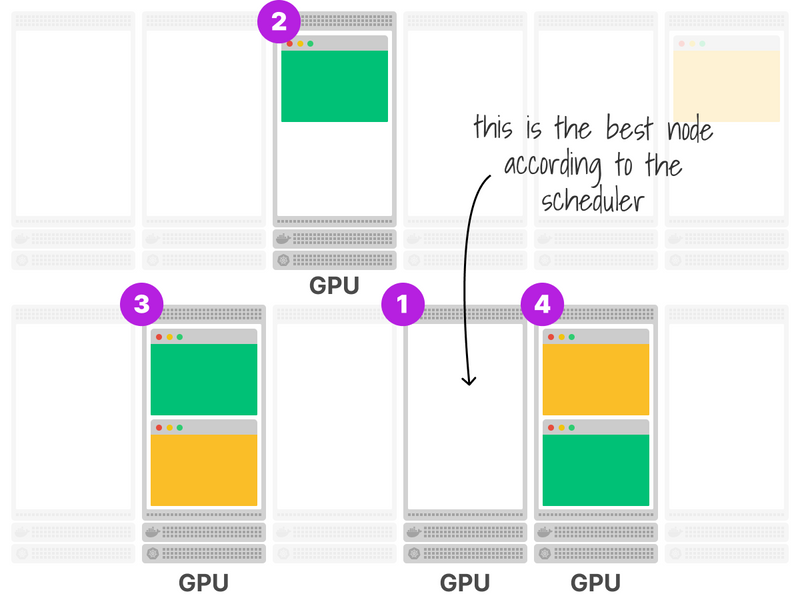
Consider the following cluster with nodes with and without GPU.
Also, a few nodes are already running at total capacity.

You want to deploy a Pod that requires some GPU.
You submit the pod to the cluster, and it's added to the scheduler queue.
The scheduler discards all nodes that don't have GPU (filter phase).

Next, the scheduler scores the remaining nodes.
In this example, the fully utilized nodes are scored lower.
In the end, the empty node is selected.
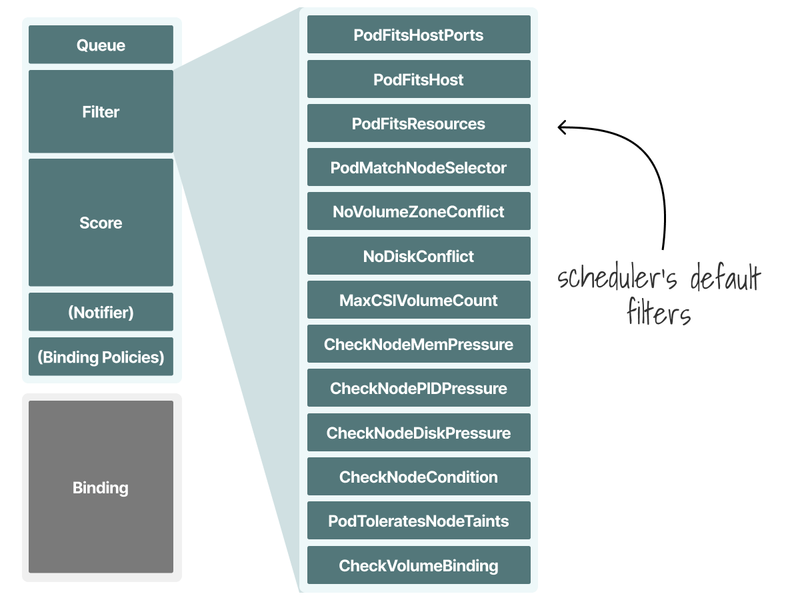
What are some examples of filters?
-
NodeUnschedulableprevents pods from landing on nodes marked as unschedulable. -
VolumeBindingchecks if the node can bind the requested volume.
The default filtering phase has 13 predicates.
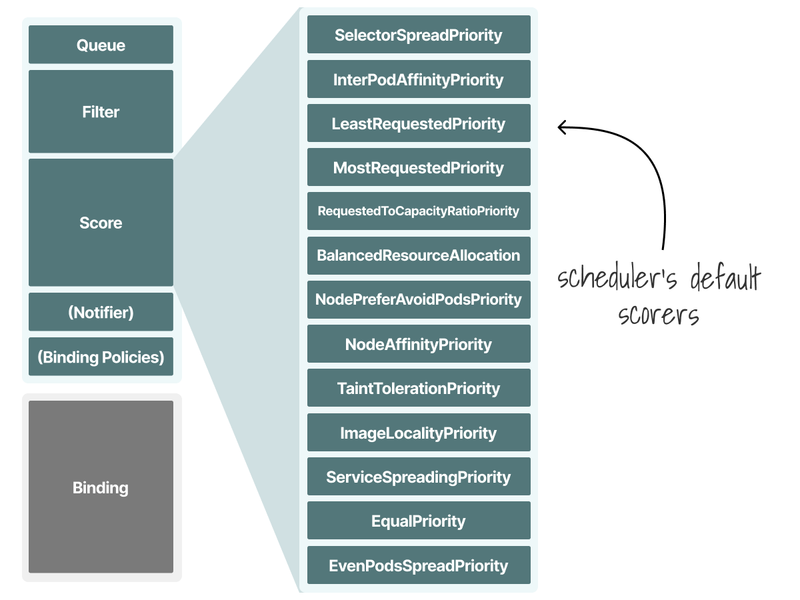
Here are some examples of scoring:
-
ImageLocalityprefers nodes that already have the container image downloaded locally. -
NodeResourcesBalancedAllocationprefers underutilized nodes.
There are 13 functions to decide how to score and rank nodes.
How can you influence the scheduler's decisions?
nodeSelector- Node affinity
- Pod affinity/anti-affinity
- Taints and tolerations
- Topology constraints
- Scheduler profiles
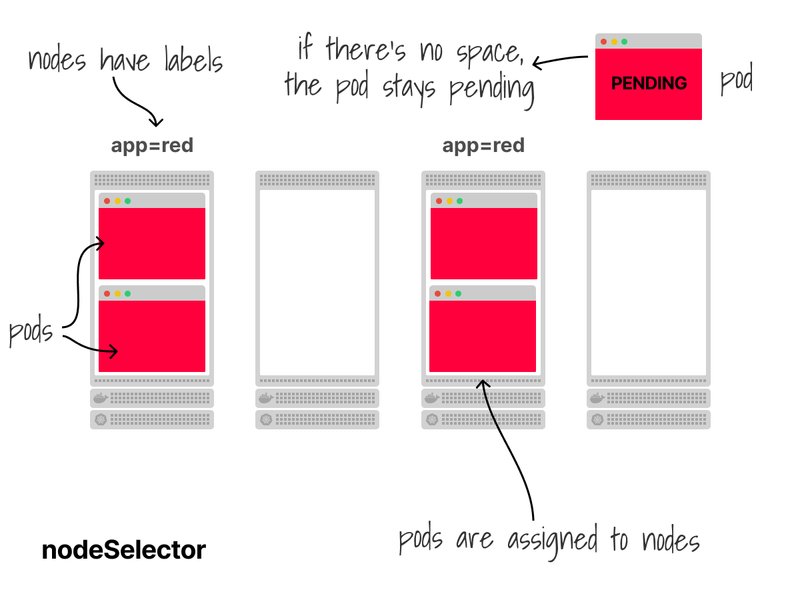
nodeSelector is the most straightforward mechanism.
You assign a label to a node and add that label to the pod.
The pod can only be deployed on nodes with that label.
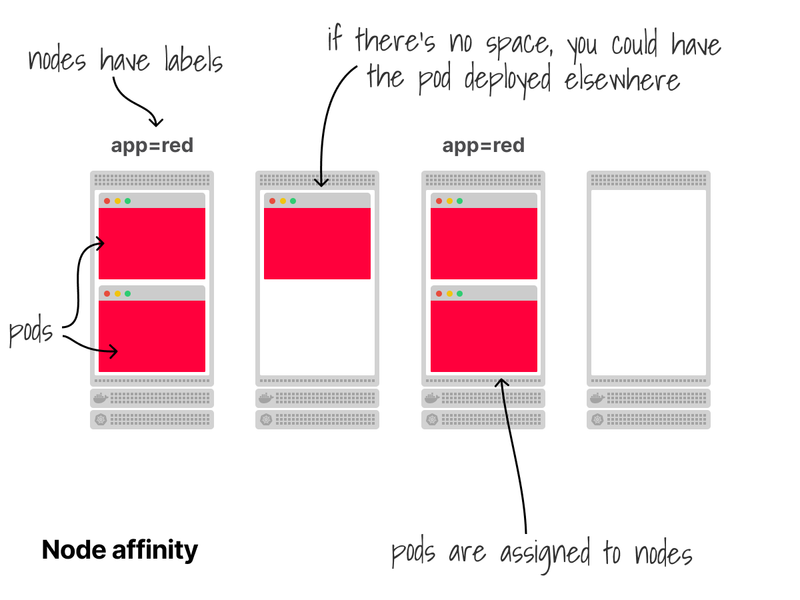
Node affinity extends nodeSelector with a more flexible interface.
You can still tell the scheduler where the Pod should be deployed, but you can also have soft and hard constraints.
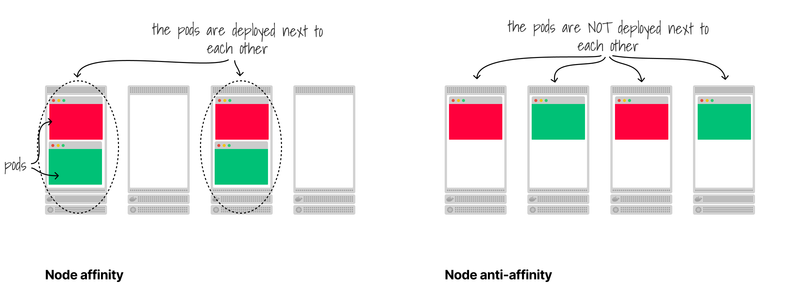
With Pod affinity/anti-affinity, you can ask the scheduler to place a pod next to a specific pod.
Or not.
For example, you could have a deployment with anti-affinity on itself to force spreading pods.
With taints and tolerations, pods are tainted, and nodes repel (or tolerate) pods.
This is similar to node affinity, but there's a notable difference: with Node affinity, Pods are attracted to nodes.
Taints are the opposite - they allow a node to repel pods.
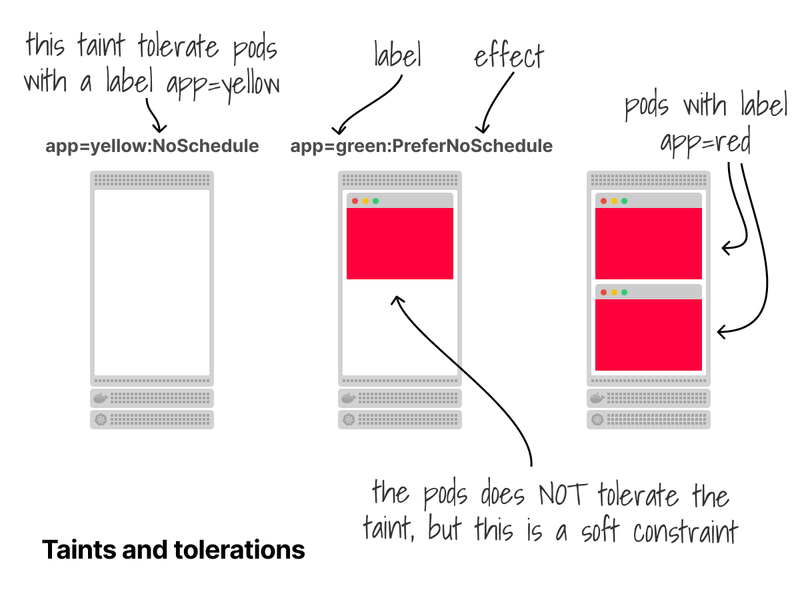
Moreover, tolerations can repel pods with three effects: evict, "don't schedule", and "prefer don't schedule".
Personal note: this is one of the most difficult APIs I worked with.
I always (and consistently) get it wrong as it's hard (for me) to reason in double negatives.
You can use topology spread constraints to control how Pods are spread across your cluster.
This is convenient when you want to ensure that all pods aren't landing on the same node.

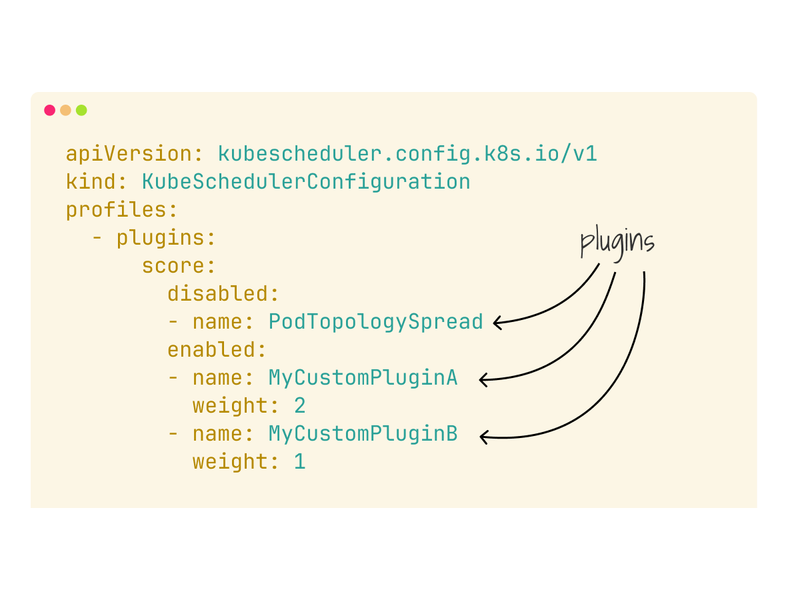
And finally, you can use Scheduler policies to customize how the scheduler uses filters and predicates to assign nodes to pods.
This relatively new feature (>1.25) allows you to turn off or add new logic to the scheduler.
You can learn more about the scheduler here:
- Kubernetes scheduler https://kubernetes.io/docs/concepts/scheduling-eviction/kube-scheduler/
- Scheduling framework https://kubernetes.io/docs/concepts/scheduling-eviction/scheduling-framework/
- Scheduler policies https://kubernetes.io/docs/reference/scheduling/config/
And finally, if you've enjoyed this thread, you might also like:
- The Kubernetes workshops that we run at Learnk8s https://learnkube.com/training
- This collection of past threads https://twitter.com/danielepolencic/status/1298543151901155330
- The Kubernetes newsletter I publish every week "Learn Kubernetes weekly" https://learnkube.com/learn-kubernetes-weekly

Top comments (18)
Thanks Daniele for this article, very well done!! 👏
A "Kubernetes Scheduler Deep Dive" explores how the Kubernetes scheduler allocates pods to nodes based on available resources and constraints. It covers topics like the scheduling algorithm, custom scheduler creation, and performance optimizations. For those managing Kubernetes clusters, understanding the scheduler is essential, just like knowing take 5 oil change prices helps with making informed decisions on car maintenance. Optimizing the scheduler ensures efficient resource utilization and smooth operation of the cluster.
While comparing options, cardmates.net/playfortuna
provided useful insights about play fortuna. The information is structured and easy to read. A good reference before making a decision.
I really appreciate this wonderful post—it greatly supported my article. Make sure to take time for yourself as well: enjoy healthy meals, explore new places, and refresh your mind. A clear and energized mind leads to stronger writing, so stay healthy and keep your creativity bright.
Explore the Kubernetes scheduler in depth and learn how it makes pod placement decisions. Perfect for those involved in beta testing FF or managing complex cluster workloads efficiently.
Thank you for sharing this wonderful post — it was truly helpful while I was working on my article. Whenever you get some free time, take a moment to enjoy healthy food, visit new restaurants, and explore different places. A refreshed mind always brings out better writing, so eat fresh and breathe in clean air to stay inspired.
Thanks a lot for this amazing post! It really helped me with my article. When you’re free, try enjoying some healthy food, visiting new restaurants, and exploring different places. Fresh air and good food refresh your mind — that’s when you can write your best.
I really appreciate this great post — it helped me so much with my writing. Take some time to relax, eat healthy meals, and visit new restaurants or beautiful places. When your mind is refreshed and full of new experiences, your words flow more naturally and effectively.
baseball 9 is an exciting, realistic sports game about baseball. Become a manager of a professional baseball team and lead your team to victory, participating in higher tournaments.
This deep dive into the Kubernetes scheduler was genuinely insightful, especially the way you broke down filtering and scoring phases without oversimplifying them. I liked how you explained predicates, priorities, and the newer scheduling framework plugins in a practical context—it really helps connect theory to real cluster behavior. The part about resource requests versus limits and how that influences placement decisions was particularly valuable, since so many performance issues trace back to misconfigured specs. Reading this reminded me how precision and balance matter—whether it’s allocating pods efficiently across nodes or layering flavors perfectly in Dubai Chocolate Strawberries, small decisions shape the final outcome. In your experience, what’s the most overlooked scheduler configuration that teams should pay closer attention to?