
Does Kubernetes rebalance your Pods?
If there's a node that has more space, does Kubernetes recompute and balance the workloads?
Let's have a look at an example.
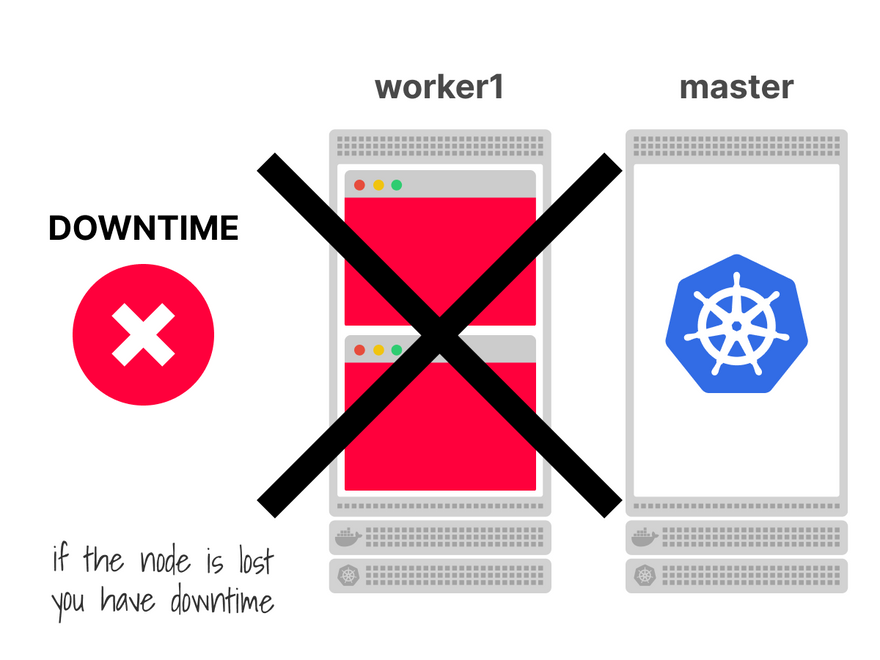
You have a cluster with a single node that can host 2 Pods.
If the node crashes, you will experience downtime.
You could have a second node with one Pod each to prevent this.
You provision a second node.
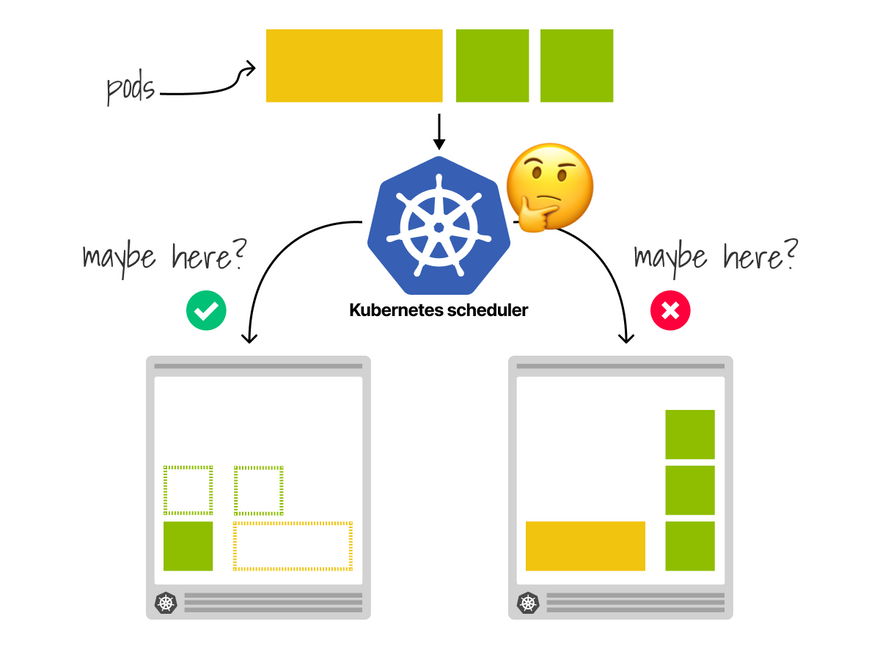
What happens next?
Does Kubernetes notice that there's a space for your Pod?
Does it move the second Pod and rebalance the cluster?
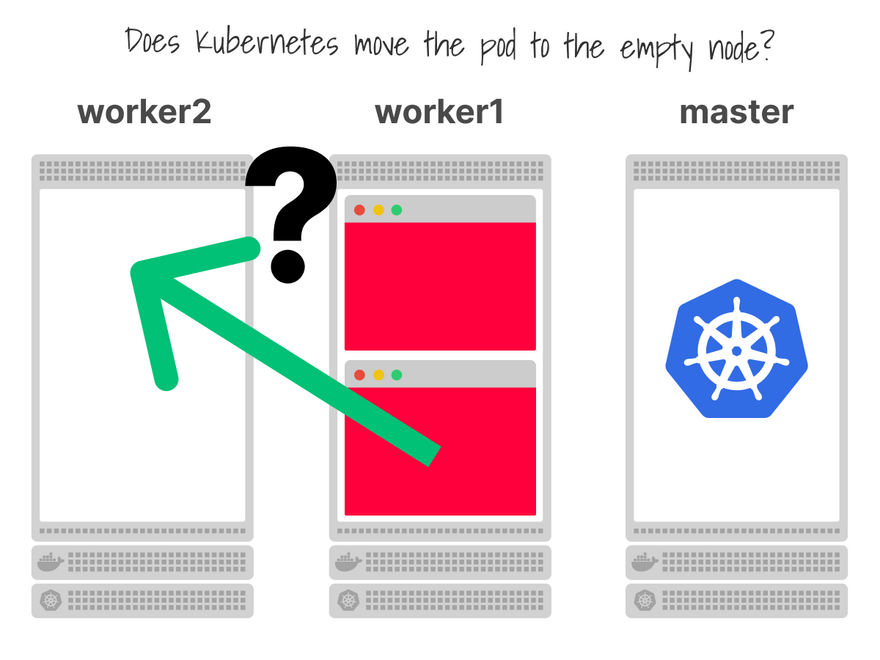
Unfortunately, it does not.
But why?
When you define a Deployment, you specify:
- The template for the Pod.
- The number of copies (replicas).
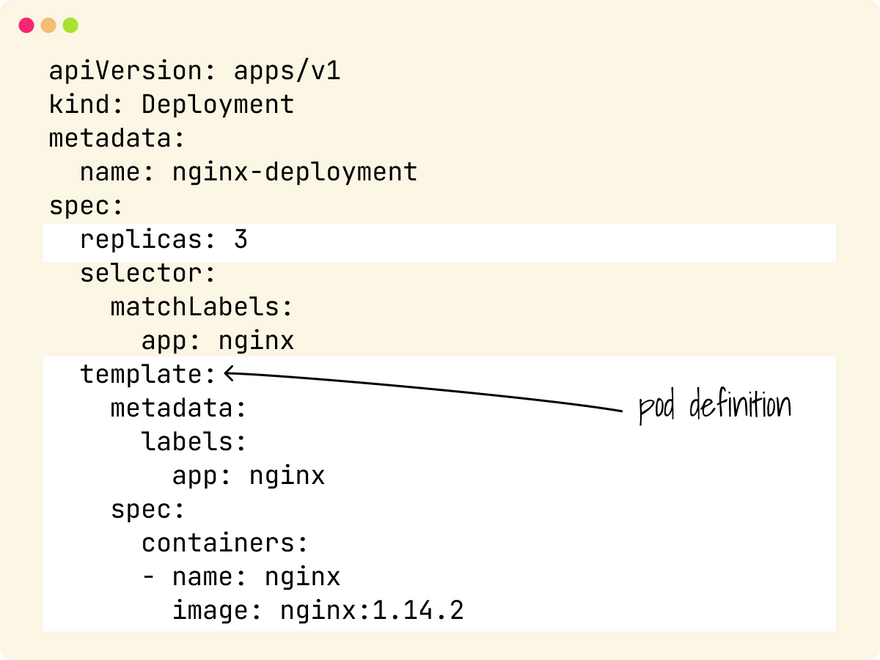
But nowhere in that file you said you want one replica for each node!
The ReplicaSet counts 2 Pods, and that matches the desired state.
Kubernetes won't take any further action.
In other words, Kubernetes does not rebalance your pods automatically.
But you can fix this.
There are three popular options:
- Pod (anti-)affinity.
- Pod topology spread constraints.
- The Descheduler.
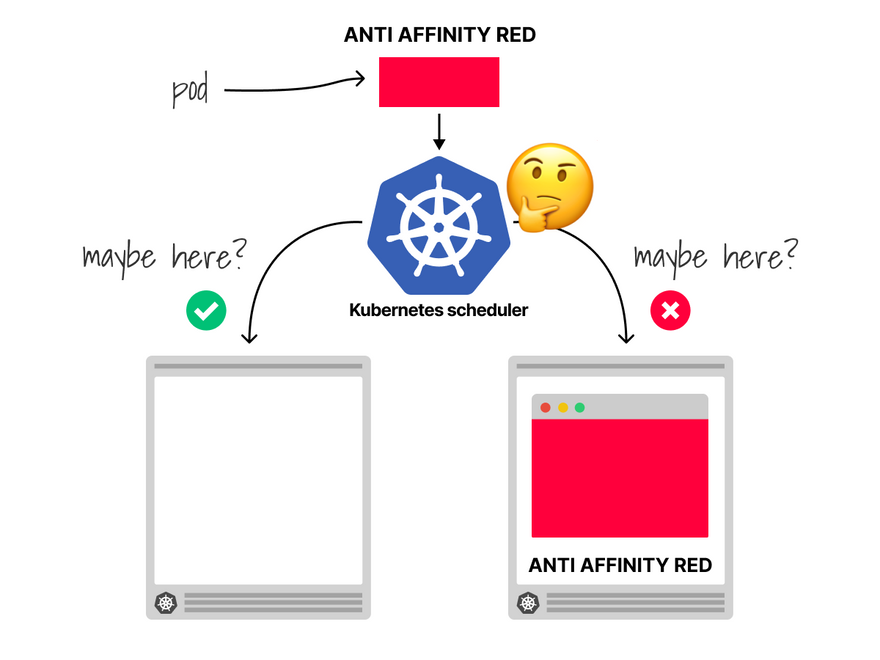
The first option is to use pod anti-affinity.
With pod anti-affinity, your Pods repel other pods with the same label, forcing them to be on different nodes.
You can read more about pod anti-affinity here.
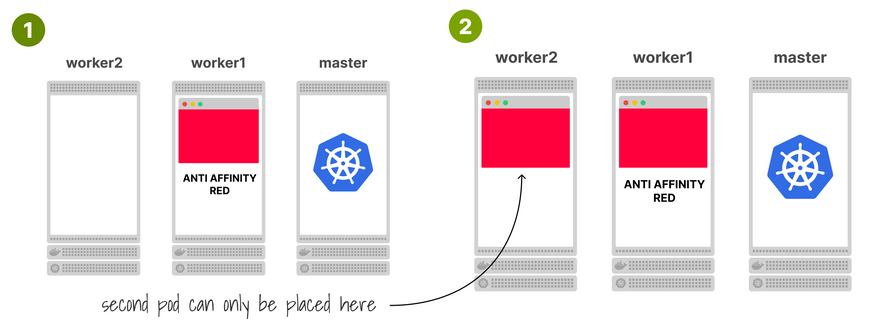
Notice how pod affinity is evaluated when the scheduler allocates the pods.
It is not applied retroactively, so you might need to delete a few pods to force the scheduler to recompute the allocations.
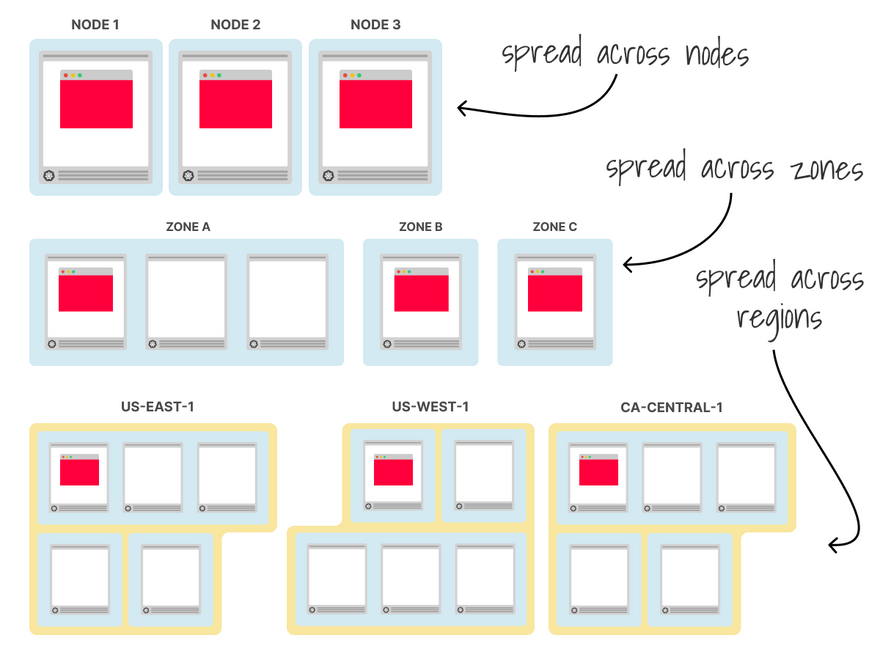
Alternatively, you can use topology spread constraints to control how Pods are spread across your cluster among failure domains such as regions, zones, nodes, etc.
This is similar to pod affinity but more powerful.
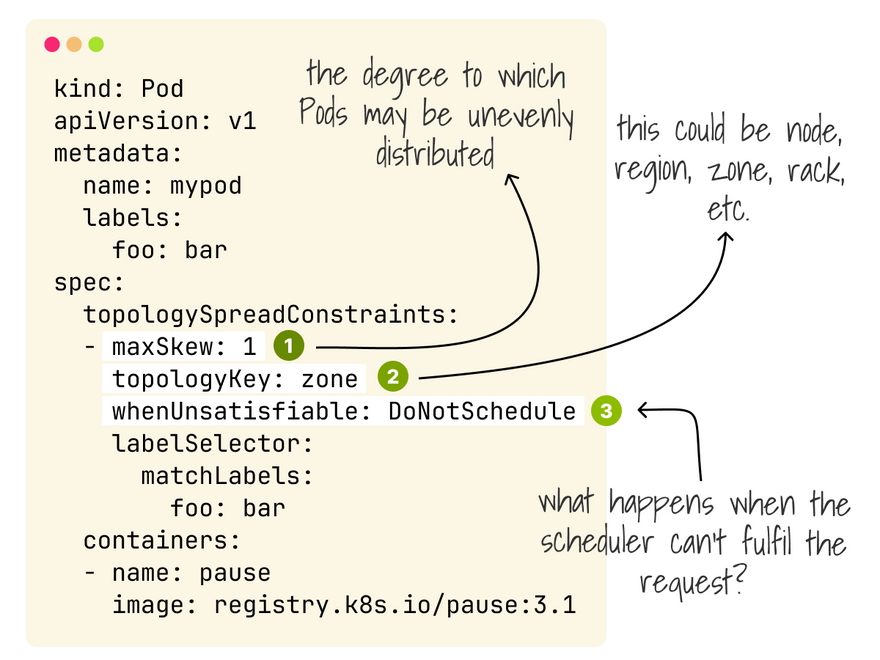
With topology spread constraints, you can pick the topology and choose the pod distribution (skew), what happens when the constraint is unfulfillable (schedule anyway vs don't) and the interaction with pod affinity and taints.
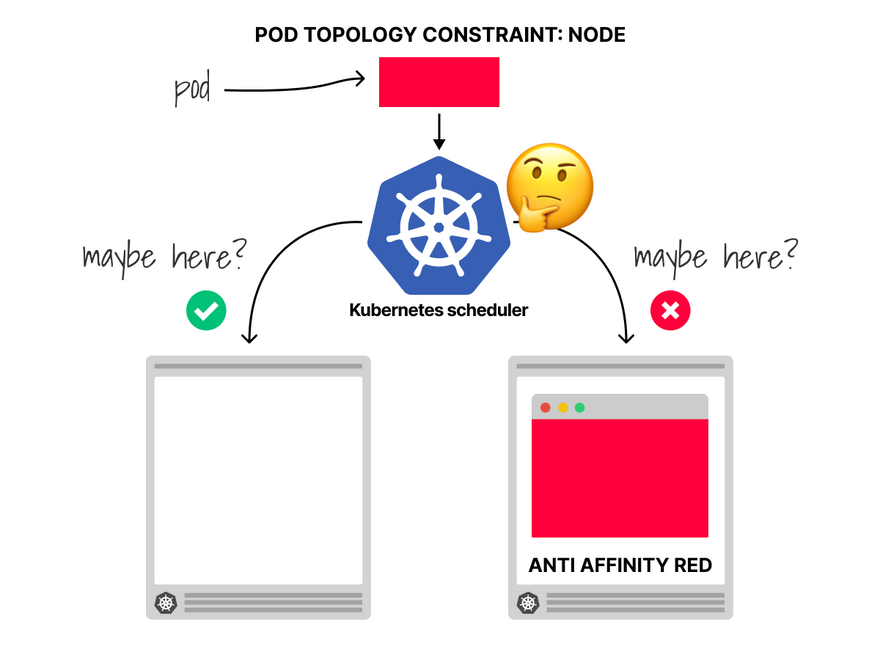
However, even in this case, the scheduler evaluates topology spread constraints when the pod is allocated.
It does not apply retroactively — you can still delete the pods and force the scheduler to reallocate them.
If you want to rebalance your pods dynamically (not just when the scheduler allocates them), you should check out the Descheduler.
The Descheduler scans your cluster at regular intervals, and if it finds a node that is more utilized than others, it deletes a pod in that node.
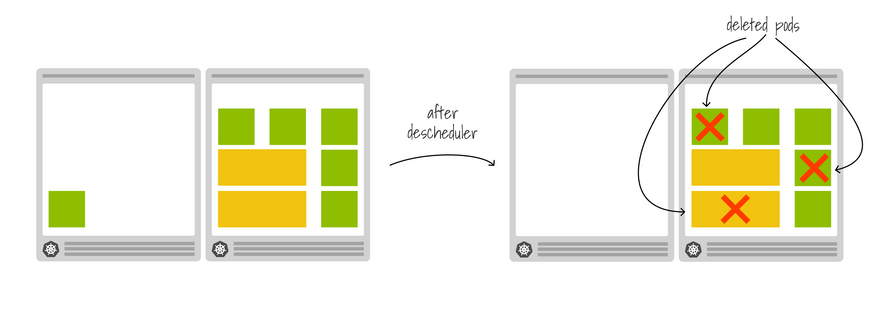
What happens when a Pod is deleted?
The ReplicaSet will create a new Pod, and the scheduler will likely place it in a less utilized node.
If your pod has topology spread constraints or pod affinity, it will be allocated accordingly.
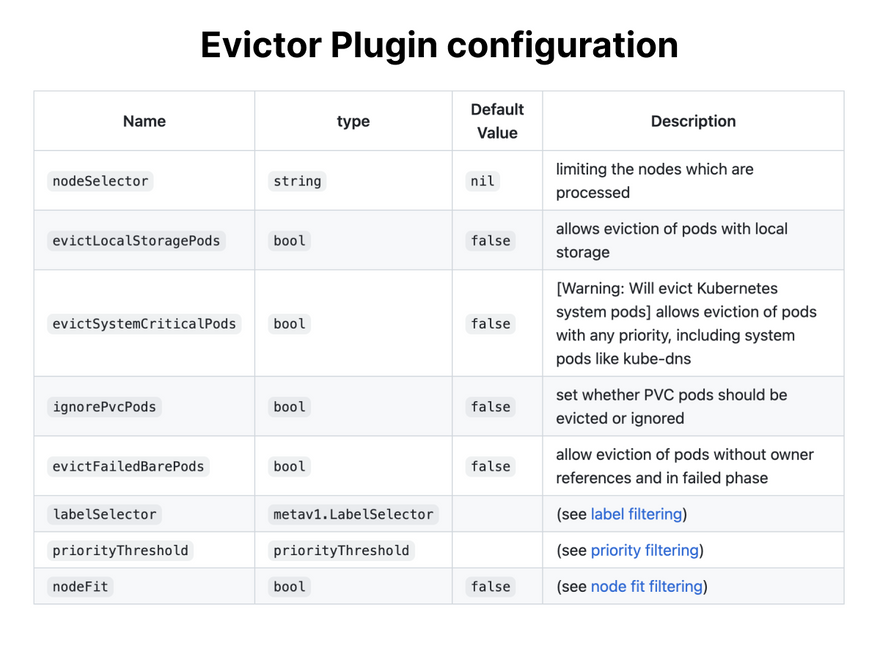
The Descheduler can evict pods based on policies such as:
- Node utilization.
- Pod age.
- Failed pods.
- Duplicates.
- Affinity or taints violations.
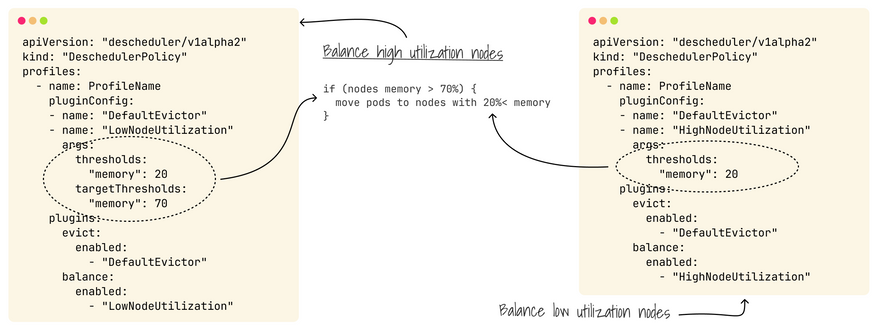
If your cluster has been running long, the resource utilization could be more balanced.
The following two strategies can be used to rebalance your cluster based on CPU, memory or number of pods.
Another practical policy is preventing developers and operators from treating pods like virtual machines.
You can use the descheduler to ensure pods only run for a fixed time (e.g. seven days).

Lastly, you can combine the Descheduler with Node Problem Detector and Cluster Autoscaler to automatically remove Nodes with problems.
The Descheduler can be used to descheduler workloads from those Nodes.
The Descheduler is an excellent choice to keep your cluster efficiency in check, but it isn't installed by default.
It can be deployed as a Job, CronJob or Deployment.
And finally, if you've enjoyed this thread, you might also like:
- The Kubernetes workshops that we run at Learnk8s https://learnk8s.io/training
- This collection of past threads https://twitter.com/danielepolencic/status/1298543151901155330
- The Kubernetes newsletter I publish every week https://learnk8s.io/learn-kubernetes-weekly

Top comments (17)
Planet Clicker is a perfect example of how an idle game should be designed. It’s easy to understand but offers enough depth to keep you engaged for hours. The balance between manual clicking and automation makes the experience both relaxing and strategic.
Pod rebalancing and allocations in Kubernetes are about how Pods get placed, spread, and moved across nodes to keep workloads reliable, performant, Veck IO and cost-efficient. Kubernetes does this mostly through scheduling policies rather than constantly moving Pods.
Drift Boss stands out as one of the most engaging browser games available today. No downloads, no sign-ups—just instant gameplay. Its addictive nature and rewarding progression system make it easy to lose track of time as you try to beat your best run.
In order to achieve success, you need to be geometry dash able to learn the beat, memorize patterns, and react in split seconds. This will make the experience both thrilling and frustrating.
That’s a really clear explanation — many people assume Kubernetes automatically rebalances workloads, but it’s important to Retro Bowl understand that it only maintains the desired replica count, not their distribution.
sc88hd.com/
mang đến một không gian giải trí trực tuyến hiện đại với giao diện thân thiện và dễ sử dụng trên nhiều thiết bị khác nhau. Người dùng có thể nhanh chóng làm quen với các tính năng được sắp xếp khoa học, từ đó tận hưởng trải nghiệm mượt mà trong từng thao tác. Nền tảng luôn chú trọng cải thiện hệ thống nhằm mang lại sự ổn định và tiện lợi cho cộng đồng người tham gia.
tỷ lệ kèo nhà cái hôm nay mang đến trải nghiệm theo dõi thông tin bóng đá trực tuyến thuận tiện cho người hâm mộ. Bảng kèo được cập nhật liên tục giúp người xem dễ dàng nắm bắt sự thay đổi của từng trận đấu.
Tôi thường ưu tiên các bài viết giới thiệu nền tảng giải trí được viết súc tích để tiện xem nhanh. Phần nhắc đến hi88 được đặt ở giữa bài nên nội dung khá hợp lý. Nội dung thể hiện chi tiết, thao tác ổn định và các chuyên mục quen thuộc. Tổng thể bài viết mạch lạc nên đọc nhanh.
Jun 888 – nền tảng cá cược hiện đại với tỷ lệ kèo hấp dẫn, slot game phong phú chân thực. Thưởng nóng mỗi ngày, khuyến mãi liên tục cùng dịch vụ chăm sóc khách hàng chuyên nghiệp, tận tâm.
The upgrades in Escape Road 2 make progressing through the game even more exciting.