
TL;DR: In this article, you will learn how the Ingress controller works in Kubernetes by building one from scratch in bash.
Before diving into the code, let's recap how the ingress controller works.
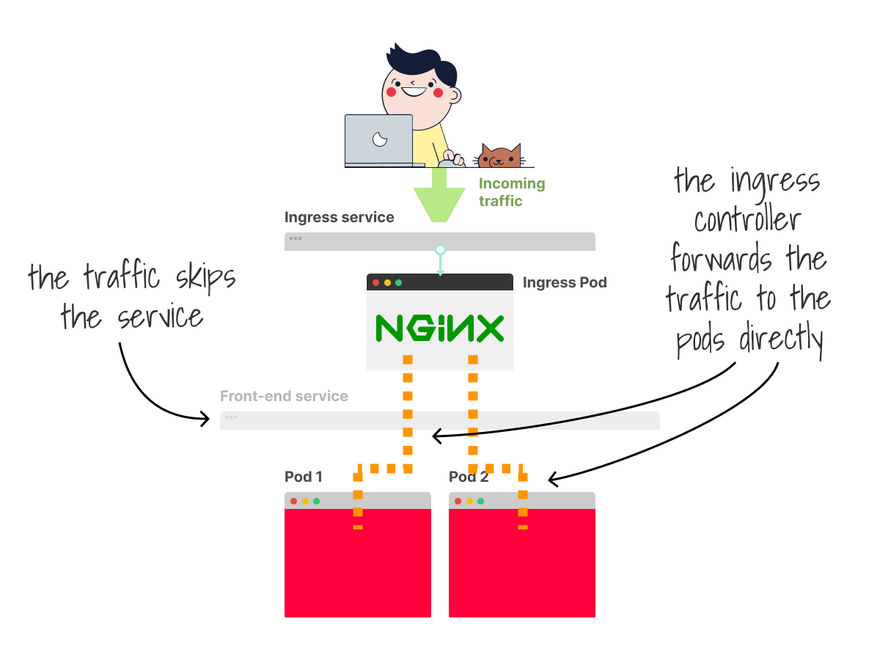
You can think of the ingress controller as a router that forwards traffic to the correct pods.
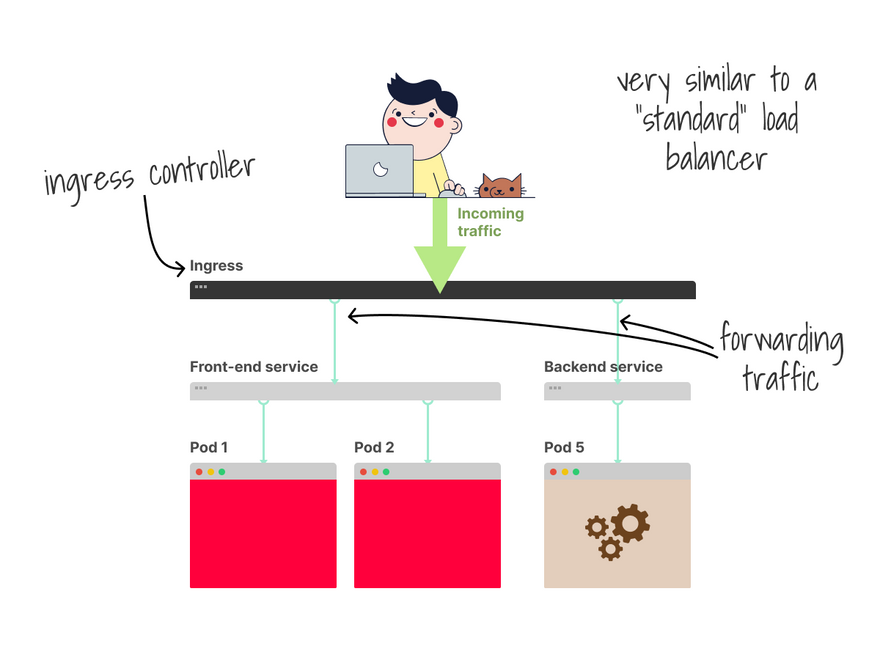
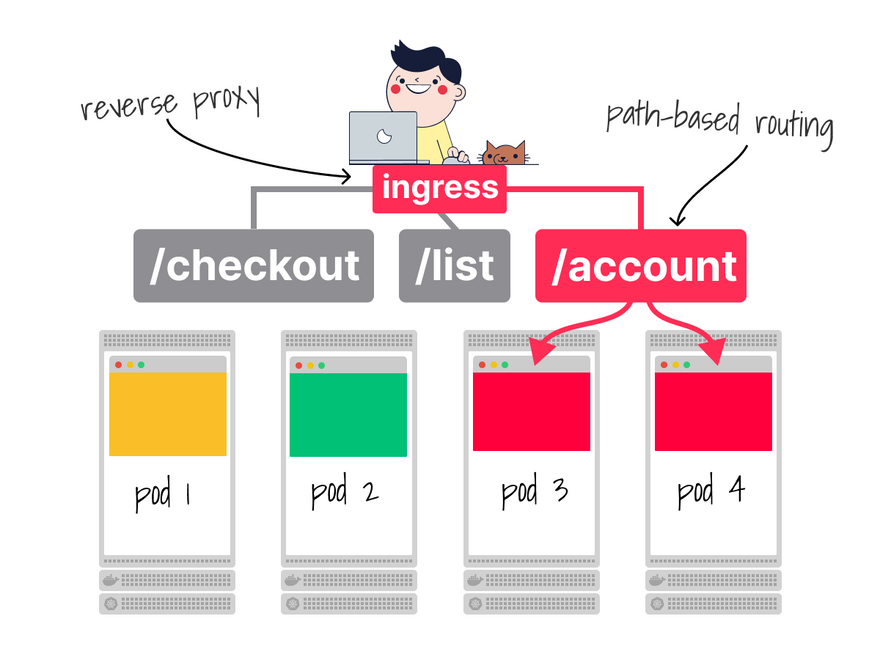
More specifically, the ingress controller is a reverse proxy that works (mainly) on L7 and lets you route traffic based on domain names, paths, etc.
Kubernetes doesn't come with one by default.
So you have to install and configure an Ingress controller of choice in your cluster.
But Kubernetes provides an Ingress manifest (YAML) definition.
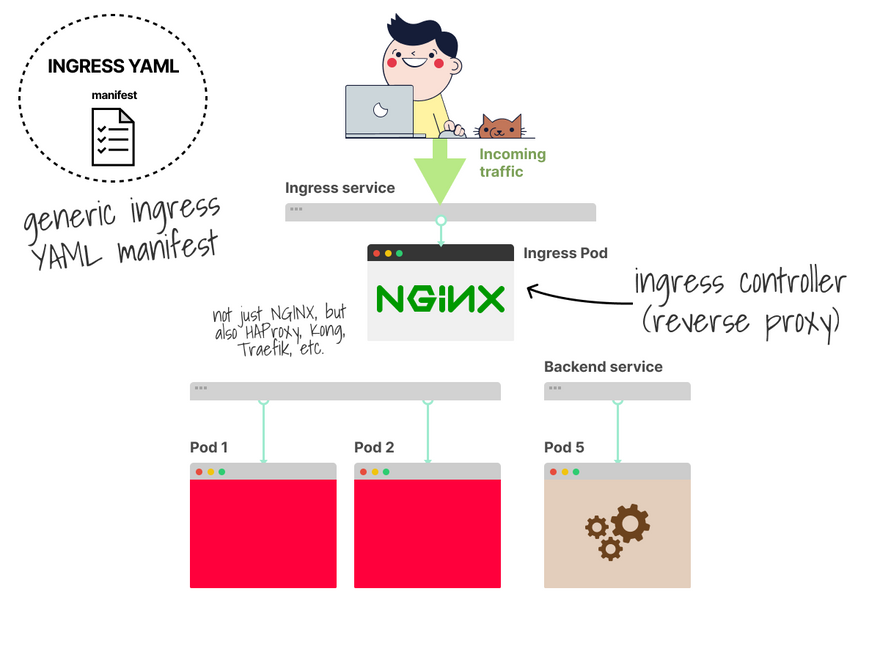
The exact YAML definition is expected to work regardless of what Ingress controller you use.
The critical fields in that file are:
- The path (
spec.rules[*].http.paths[*].path). - The backend (
spec.rules[*].http.paths[*].backend.service).
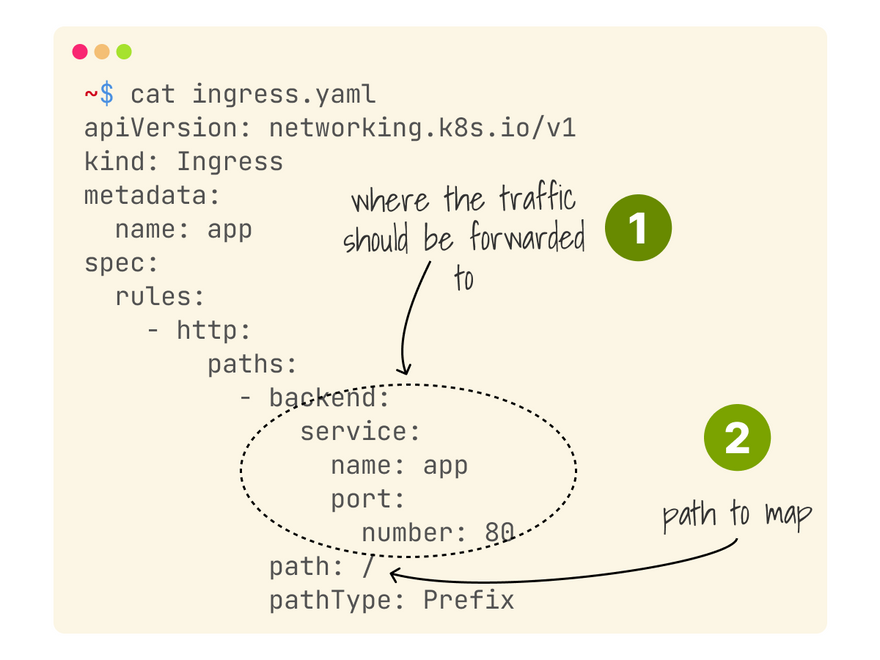
The backend field describes which service should receive the forwarded traffic.
But, funny enough, the traffic never reaches it.
This is because the controller uses endpoints to route the traffic, not the service.
What is an endpoint?
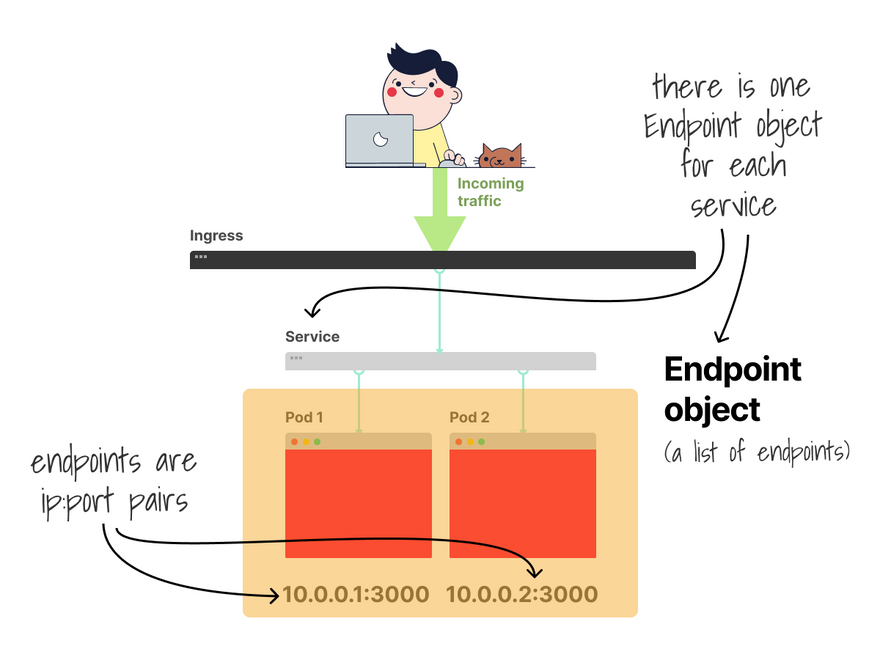
When you create a Service, Kubernetes creates a companion Endpoint object.
The Endpoint object contains a list of endpoints (ip:port pairs).
And the IP and ports belong to the Pod.
Enough, theory.
How does this work in practice if you want to build your own controller?
There are two parts:
- Retrieving data from Kubernetes.
- Reconfiguring the reverse proxy.
Let's start with retrieving the data.
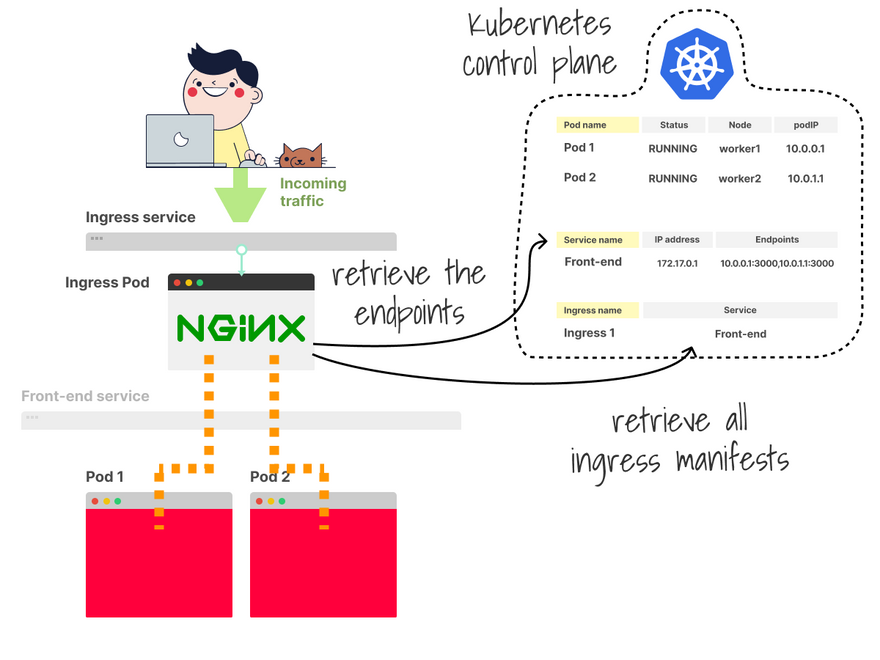
In this step, the controller has to watch for changes to Ingress manifests and endpoints.
If an ingress YAML is created, the controller should be configured.
The same happens when the service changes (e.g. a new Pod is added).
In practice, this could be as simple as kubectl get ingresses and kubectl get endpoints <service-name>.
With this data, you have the following info:
- The path of the ingress manifest.
- All the endpoints that should receive traffic.
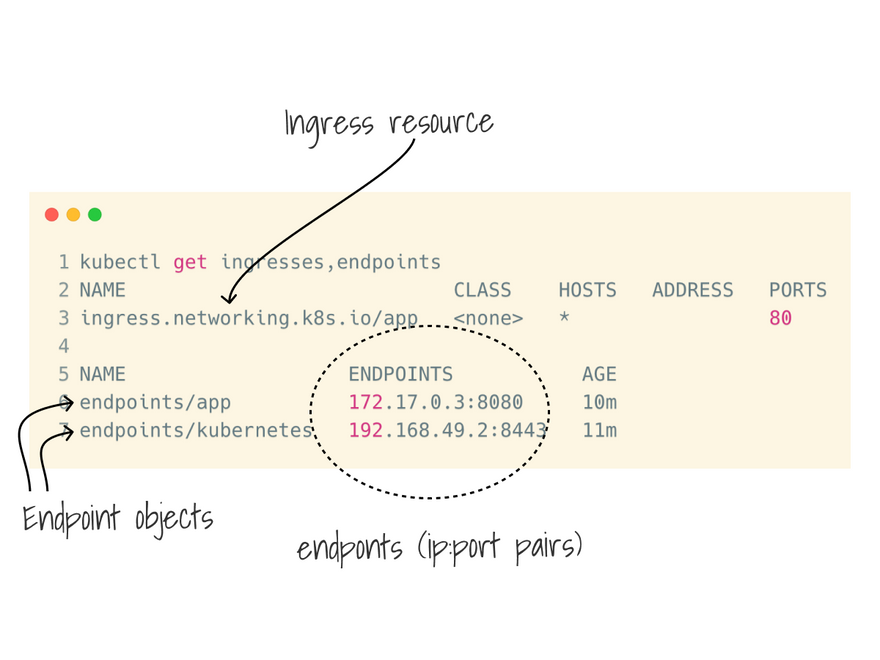
With kubectl get ingresses, you can get all the ingress manifest and loop through them.
I used -o jsonpath to filter the rules and retrieve: the path and the backend service.
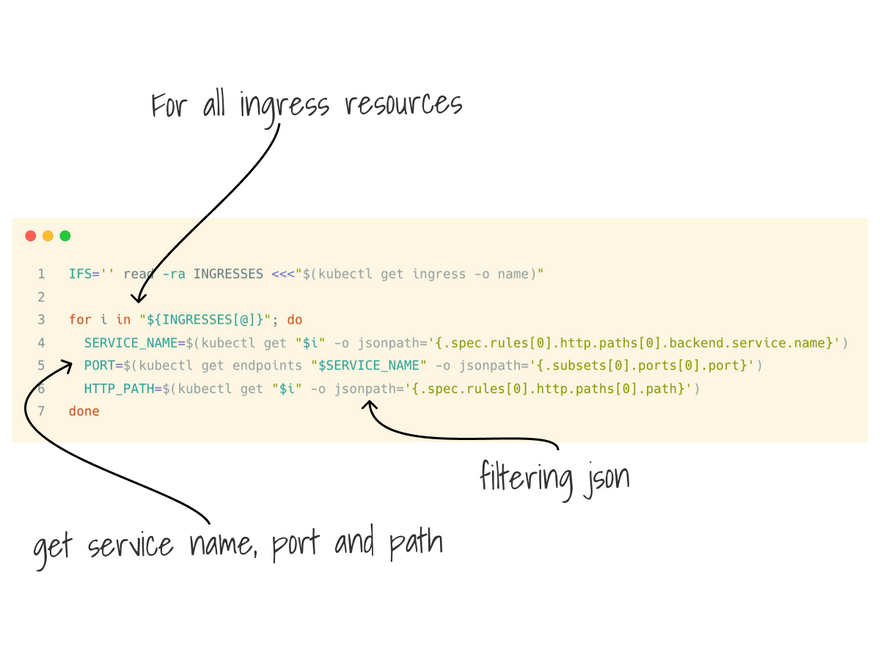
With kubectl get endpoint <service-name>, you can retrieve all the endpoints (ip:port pair) for a service.
Even in this case, I used -o jsonpath to filter those down and save them in a bash array.

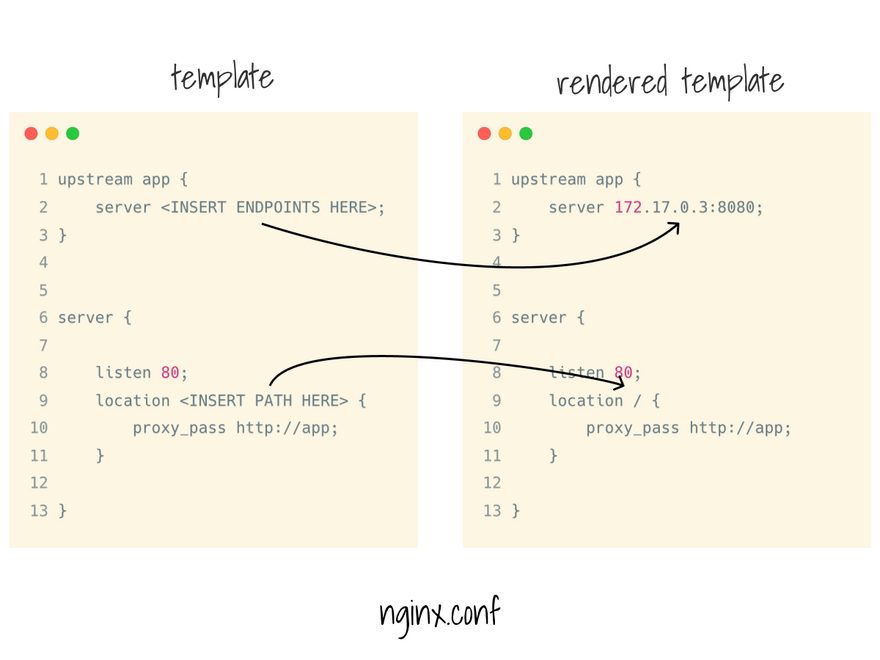
At this point, you can use the data to reconfigure the ingress controller.
In my experiment, I used Nginx, so I just wrote a template for the nginx.conf and hot-reloaded the server.
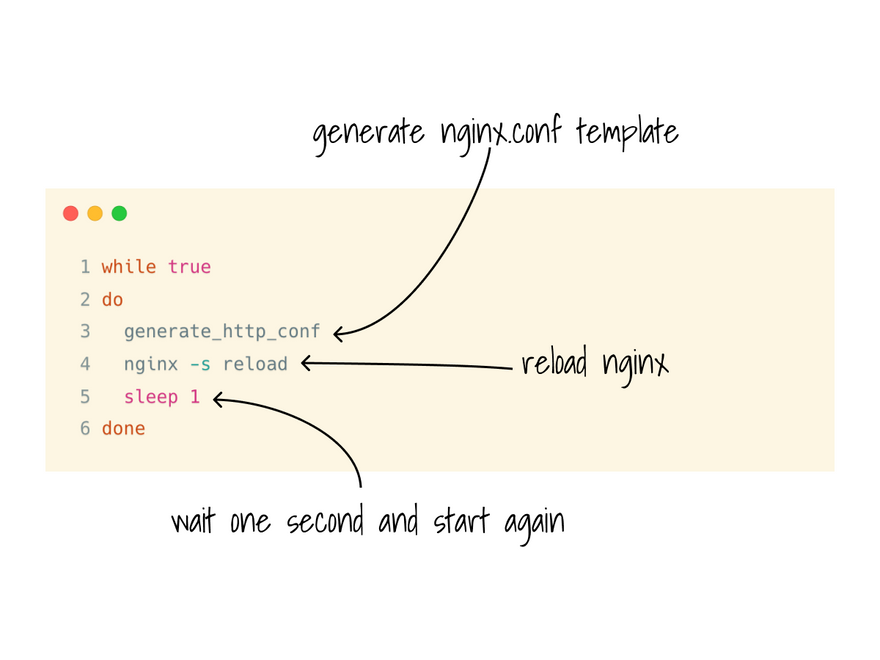
In my script, I didn't bother with detecting changes.
Instead, I decided to recreate the nginx.conf in full every second.
But you can already imagine extending this to more complex scenarios.
The last step was to package the script as a container and set up the proper RBAC rule so that I could consume the API endpoints from the API server.
And here you can find a demo of it working:

If you want to play with the code, you can find it here: https://github.com/learnk8s/bash-ingress
I plan to write a longer form article on this; if you are interested, you can sign up for the Learnk8s newsletter here: https://learnk8s.io/newsletter.
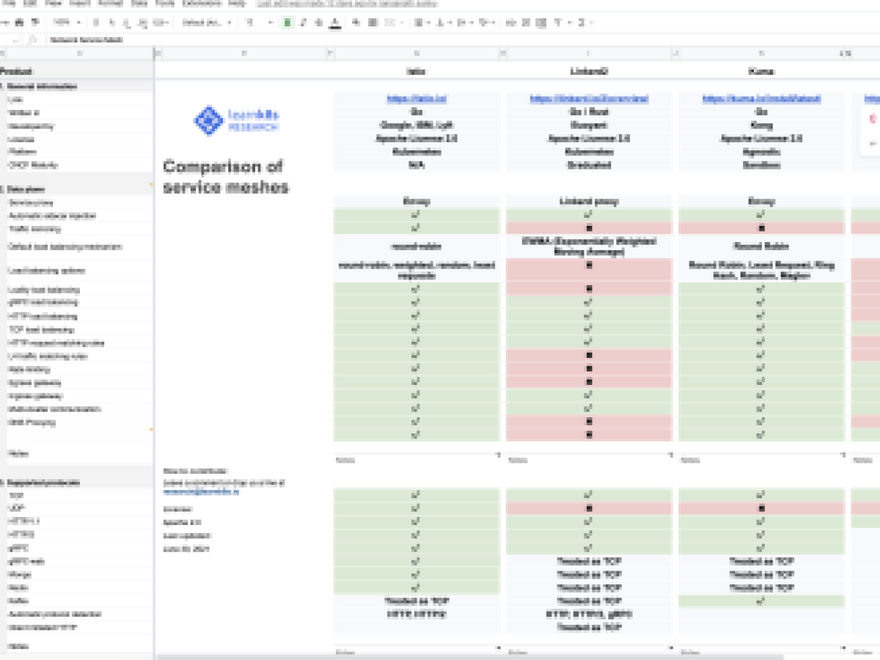
And if you are unsure what ingress controllers are out there, at Learnk8s we have put together a handy comparison:
And finally, if you've enjoyed this thread, you might also like the Kubernetes workshops that we run at Learnk8s https://learnk8s.io/training or this collection of past Twitter threads https://twitter.com/danielepolencic/status/1298543151901155330
Until next time!

Top comments (6)
Whether you're playing official levels or diving into the endless sea of custom content, Geometry Dash offers a deep, addictive experience that keeps players coming back for more. It's a rare game that appeals to both casual players and hardcore challenge seekers.
It is not simply a charming image; it has become a symbol of Chill Guy Clicker a carefree and tranquil demeanour in a world that is frequently tumultuous online.
I like how this explanation simplifies the concept of an ingress controller by comparing it to a router—it makes a complex Kubernetes topic much easier to grasp. Building one in bash also seems like a great hands-on way to really understand how traffic gets routed to the right pods. I find that learning by doing like this helps concepts stick much better. In a different way, I get that same kind of satisfaction when I’m experimenting with systems and setups in the EaglerCraft Game, where I can see how different components interact in real time.
When playing ragdoll archers watch your enemy's movements closely because they will also adjust their aim to hit you in unexpected ways
Is it a good idea to reload nginx that often? Might be better to use inotifywait
How about egress controller?****