A newer, expanded version of this article is available at learnkube.com/etcd-kubernetes
If you've ever interacted with a Kubernetes cluster in any way, chances are it was powered by etcd under the hood.
But even though etcd is at the heart of how Kubernetes works, it's rare to interact with it directly daily.
In this article, you will explore how it works!
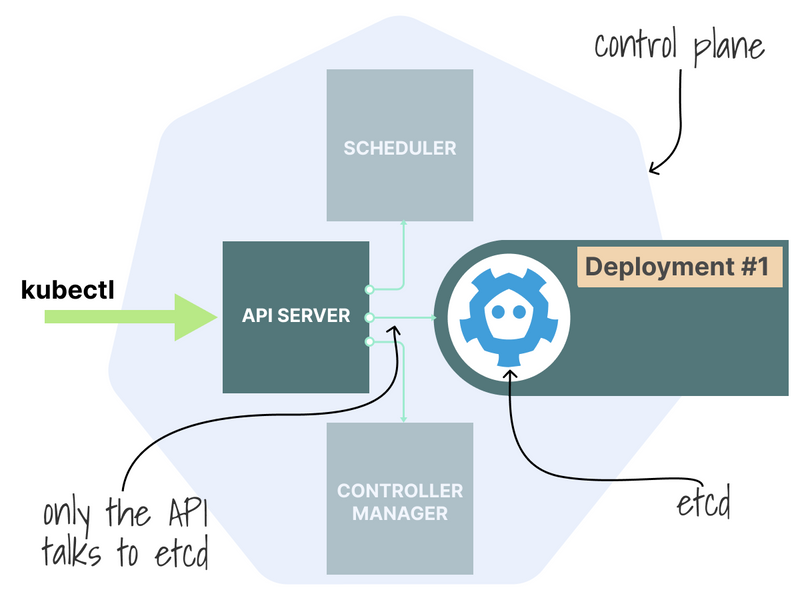
Architecturally speaking, the Kubernetes API server is a CRUD application that stores manifests and serves data.
Hence, it needs a database to store its persisted data, which is where etcd fits into the picture.
According to its website, etcd is:
- Strongly consistent.
- Distributed.
- Key-value store.
In addition, etcd has another feature that Kubernetes extensively uses: change notifications.
Etcd allows clients to subscribe to changes to a particular key or set of keys.

The Raft algorithm is the secret behind etcd's balance of strong consistency and high availability.
Raft solves a particular problem: how can multiple processes decide on a single value for something?
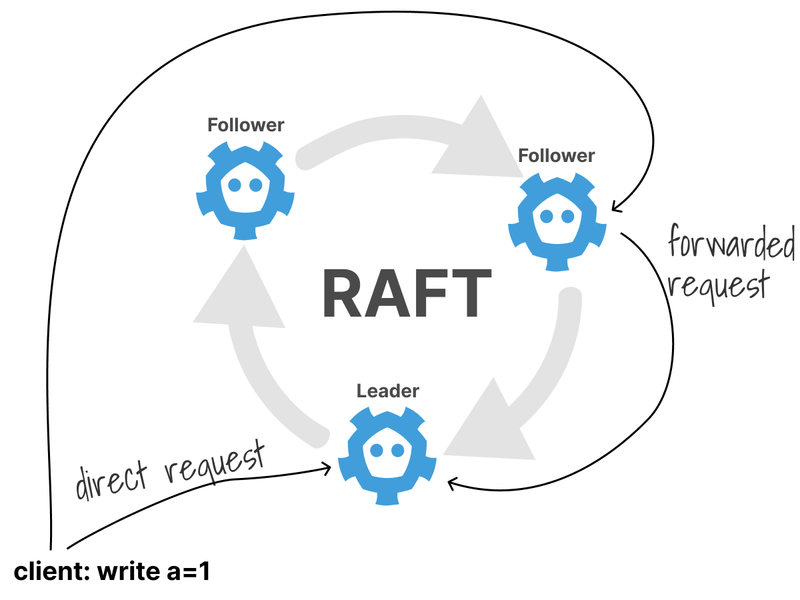
Raft works by electing a leader and forcing all write requests to go to it.
How does the Leader get elected, though?
First, all nodes start in the Follower state.
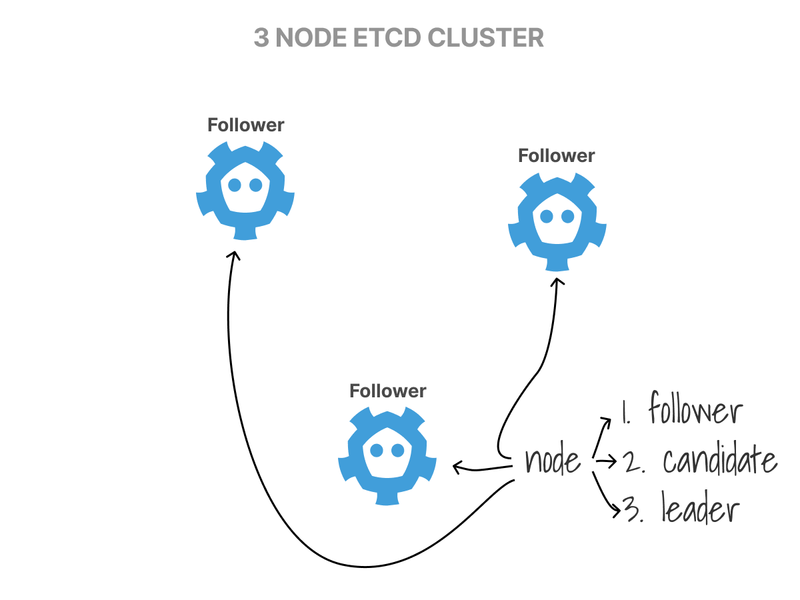
If followers don't hear from a leader, they can become candidates and request votes from other nodes.
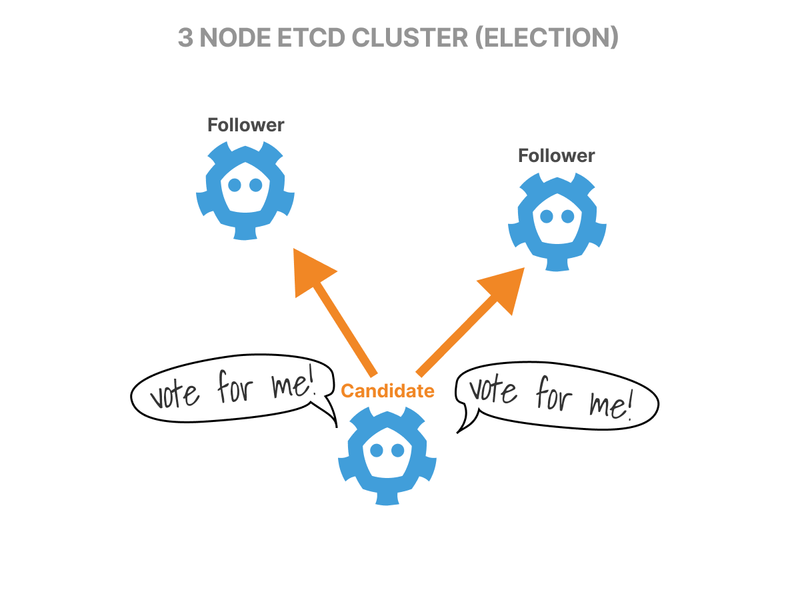
Nodes reply with their vote.
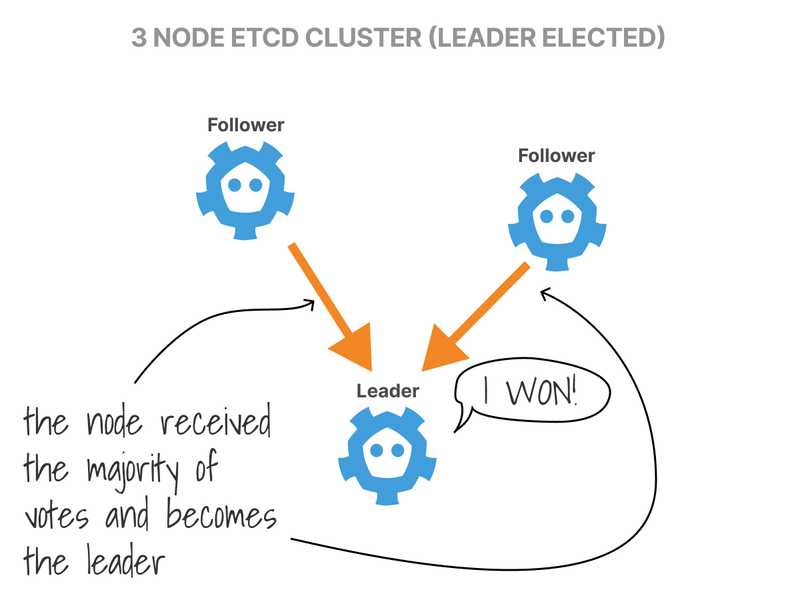
The candidate with the majority of the votes becomes the Leader.
Changes are then replicated from the Leader to all other nodes; if the Leader ever goes offline, a new election is held, and a new leader is chosen.
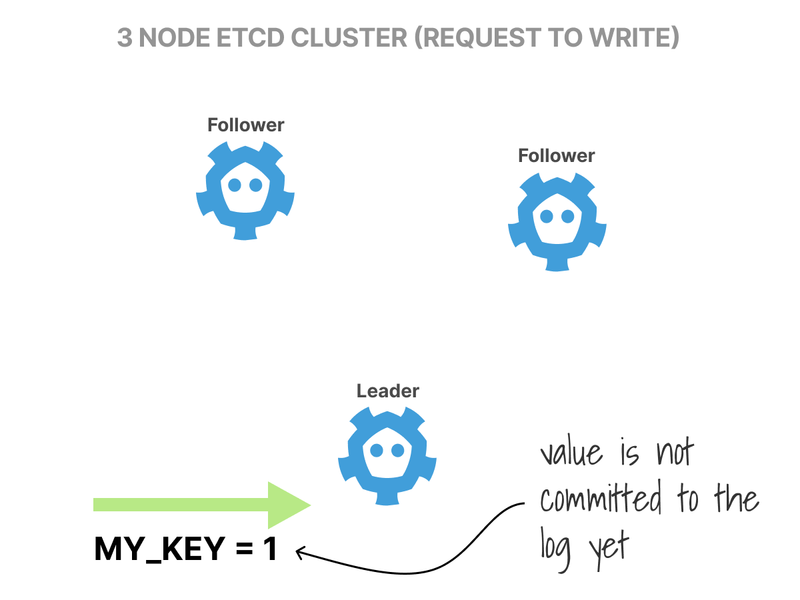
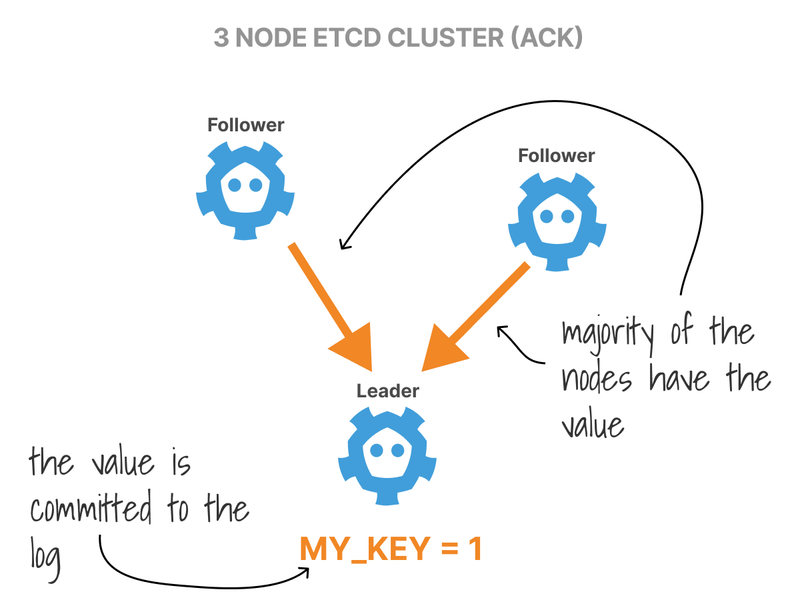
What happens when you want to write a value in the database?
First, all write requests are redirected to the Leader.
The Leader makes a note of the requests but doesn't commit it to the log.
Instead, the Leader replicates the value to the rest of the (followers) nodes.
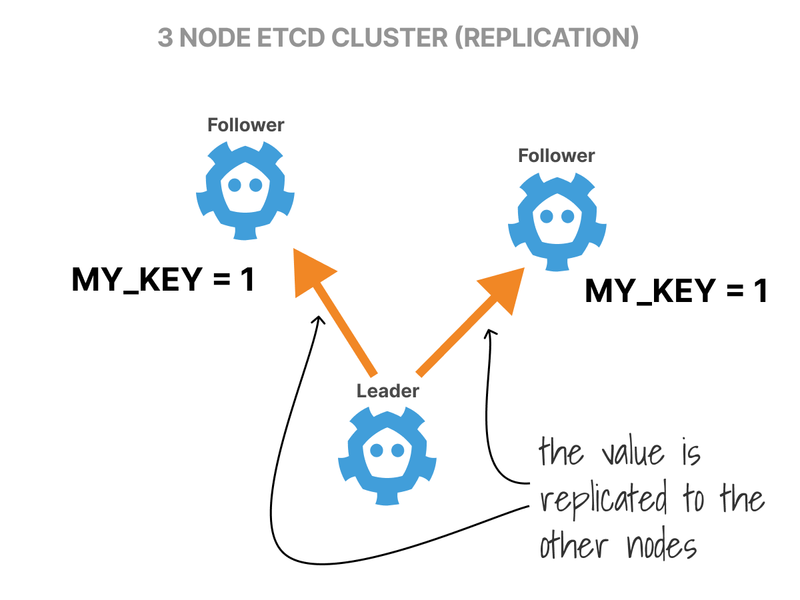
Finally, the Leader waits until a majority of nodes have written the entry and commits the value.
The state of the database contains the value.
Once the write succeeds, an acknowledgement is sent back to the client.
A new election is held if the cluster leader goes offline for any reason.
In practice, this means that etcd will remain available as long as most nodes are online.
How many nodes should an etcd cluster have to achieve "good enough" availability?
It depends.
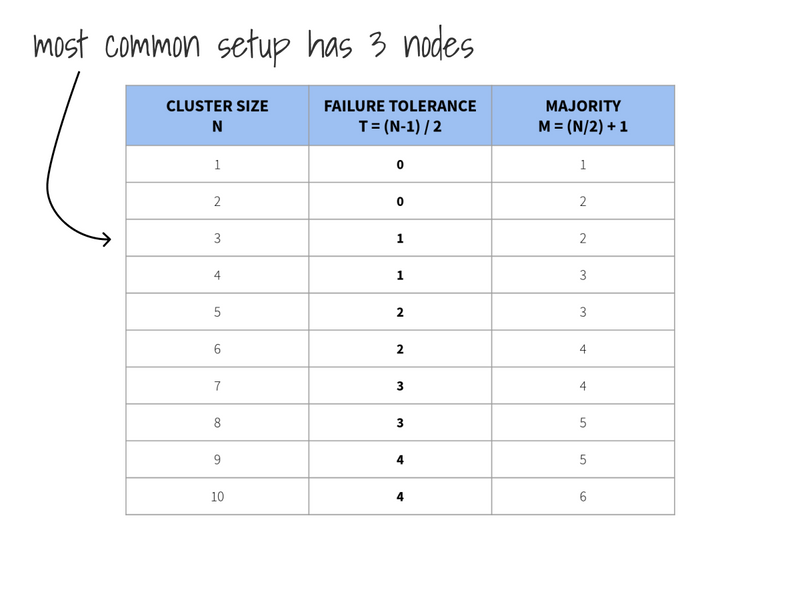
To help you answer that question, let me ask another question!
Why stop at 3 etcds, why not having a cluster with 9 or 21 or more nodes?
Hint: check out the replication part.
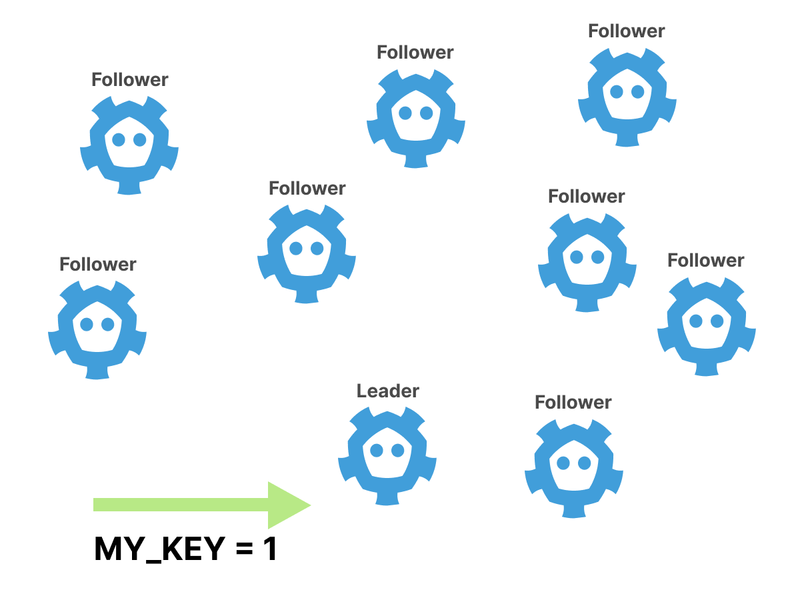
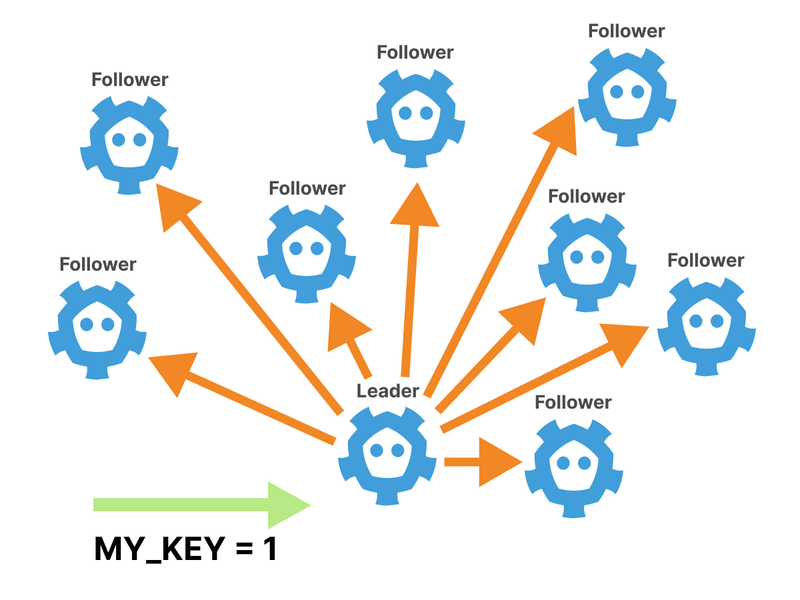
The Leader has to wait for a quorum before the value is written to disk.
The more followers there are in the cluster, the longer it takes to reach a consensus.
In other words, you trade availability for speed.
If you enjoyed this thread but want to know more on:
- Change notifications.
- Creating etcd clusters.
- Replacing etcd with SQL-like DBS with kine.
And finally, if you've enjoyed this thread, you might also like:
- The Kubernetes workshops that we run at Learnk8s https://learnkube.com/training
- This collection of past threads https://twitter.com/danielepolencic/status/1298543151901155330
- The Kubernetes newsletter I publish every week https://learnkube.com/learn-kubernetes-weekly

Top comments (16)
Thank you! Great explanation!
I recently explored a what kind of features do i have tool and it’s really interesting how it analyzes your facial traits to give insights for styling and appearance.
In Kubernetes, etcd is a distributed key-value store that ensures consistency and high availability for cluster data using the Raft consensus algorithm. It serves as the central source of truth for the cluster's state and configuration, ensuring seamless operations, as seen on platforms like gardenvila.org.
This is a really great blog and I appreciate how you put everything together in such an organized way. It’s not easy to find content that’s both informative and enjoyable to read, but you’ve done it perfectly. Thanks a lot for posting this! By the way, you should also check this out gbapps.net/gbwhatsapp-apk-dl/.
This article provides a great overview of how etcd supports Kubernetes! Understanding its role helps to appreciate the architecture of Kubernetes much better. By ensuring data consistency and reliability, etcd plays a critical part in cloud computing. It's fascinating how such foundational components work together, much like the seamless experience in games like Run 3 , where every part has its place and function.
When it comes to cluster data, Kubernetes' etcd distributed key-value store guarantees consistency and high availability with the help of the Raft consensus mechanism. For faultless operations, it is the one-and-only authoritative source for the cluster's configuration and status.
io games
Solid breakdown of the Raft consensus! It’s wild how etcd handles state even when a node takes a ragdoll hit during a network partition. Understanding the peer-to-peer communication really clarifies why the 3-node minimum is so critical for quorum. Thanks for simplifying the complexity!
It's so true that etcd is this silent workhorse behind Kubernetes, always there but rarely acknowledged. Reading about how it stores and serves data reminds me of playing Doodle Baseball, oddly enough. You keep practicing, trying to time that perfect swing, and you whiff a bunch of times. But each missed hit, each failed attempt to deploy something, is a little lesson. You adjust, learn the timing, and eventually, ding, you knock it out of the park...or successfully update your K8s cluster!
If you've ever interacted with a Kubernetes cluster in any way Speed Stars, chances are it was powered by etcd under the hood. But even though etcd is at the heart of how Kubernetes works, it's rare to interact with it directly daily.
etcd in Kubernetes stores cluster data, ensuring consistency across nodes. It manages configurations, state info, and leader elections. Kubernetes API server interacts with etcd for real-time updates. Secure and scalable, it's key for high availability. Tanska ALV