In 2020 I have published a blog post called Running MySQL Managed Database in the Cloud, comparing different alternatives for running MySQL database in the cloud.
In this blog post, I will take one step further, comparing PostgreSQL database alternatives deployed on a distributed system.
Background
PostgreSQL is an open-source relational database, used by many companies, and is very common among cloud applications, where companies prefer an open-source solution, supported by a strong community, as an alternative to commercial database engines.
The simplest way to run the PostgreSQL engine in the cloud is to choose one of the managed database services, such as Amazon RDS for PostgreSQL or Google Cloud SQL for PostgreSQL, and allow you to receive a fully managed database.
In this scenario, you as the customer, receive a fully managed PostgreSQL database cluster, that spans across multiple availability zones, and the cloud provider is responsible for maintaining the underlining operating system, including patching, hardening, monitoring, and backup (up to the service limits).
As a customer, you receive an endpoint (i.e., DNS name and port), configure access controls (such as AWS Security groups or GCP VCP Firewall rules), and set authentication and authorization for what identities have access to the managed database.
This solution is suitable for most common use cases if your applications (and perhaps customers) are in a specific region.
What happens in a scenario where you would like to design a truly highly available architecture span across multiple regions (in the rare case of an outage in a specific region) and serve customers across the globe, deploying your application close to your customers?
The solution for allowing high availability and multi-region deployment is to deploy the PostgreSQL engine in a managed distributed database.
PostgreSQL Distributed Database Alternatives
The distributed system allows you to run a database across multiple regions while keeping the data synchronized.
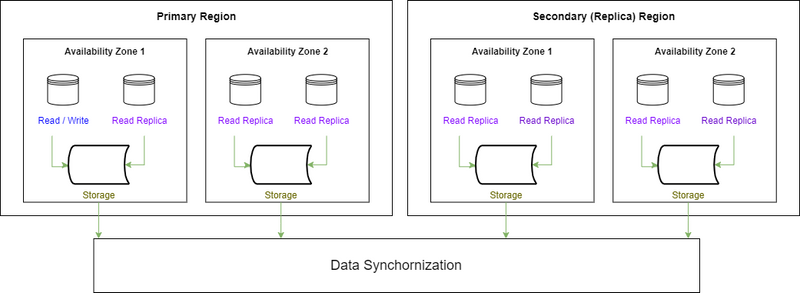
In a distributed database, the compute layer (i.e., virtual machines) running the database engine is deployed on separate nodes from the storage and logging layer, allowing you to gain the benefits of the cloud provider's backend infrastructure low-latency replication capabilities.
In each system, there is a primary cluster (which oversees read/write actions) and one or more secondary clusters (read-only replicas).
Architecture diagram:
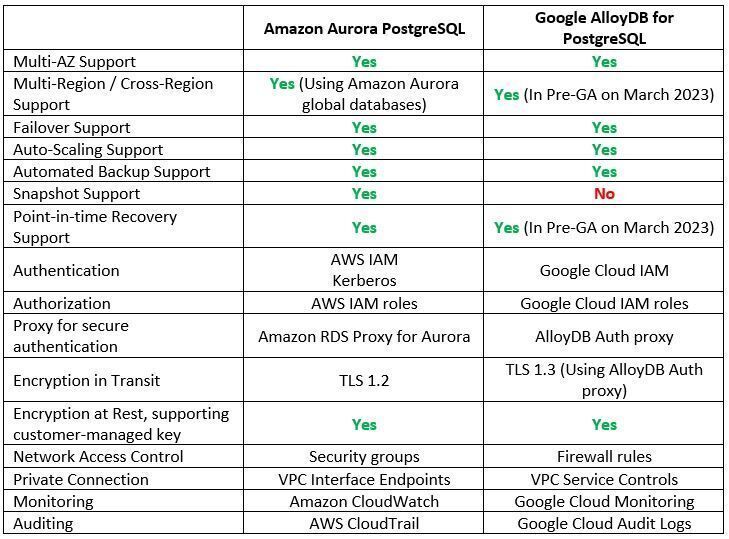
Let us examine some of the cloud providers' alternatives:
Additional References
Summary
In this blog post, I have compared two alternatives for running PostgreSQL-compatible database in a distributed architecture.
If you are looking for a relational database solution with high durability that will auto-scale according to application load, and with the capability to replicate data across multiple regions, you should consider one of the alternatives I have mentioned in this blog post.
As always, I recommend you to continue reading and expanding your knowledge on the topic and evaluate during the architecture design phase, if your workloads can benefit from a distributed database system.
Additional References
- Amazon Aurora: Design considerations for high throughput cloud-native relational databases
- AlloyDB for PostgreSQL under the hood: Intelligent, database-aware storage
About the Author
Eyal Estrin is a cloud and information security architect, the owner of the blog Security & Cloud 24/7 and the author of the book Cloud Security Handbook, with more than 20 years in the IT industry.
Eyal is an AWS Community Builder since 2020.
You can connect with him on Twitter and LinkedIn.

Top comments (1)
Cloud databases like Distributed Managed PostgreSQL are great for handling lots of data. But other options, like Amazon Aurora or Google Cloud SQL, can also work well depending on your needs. These services help keep everything running smoothly without worrying about servers.