
Organizations migrating to the public cloud, or already provisioning workloads in the cloud come across limitations, either on production workloads or issues published in the media, as you can read below:
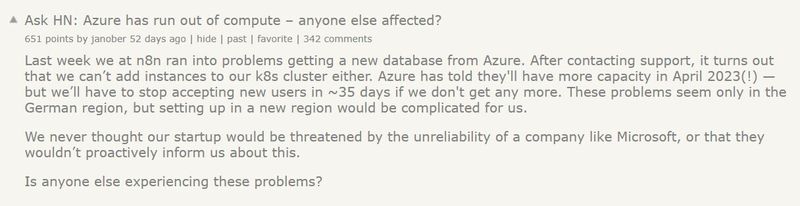
Source: https://news.ycombinator.com/item?id=33743567

Source: https://learn.microsoft.com/en-us/troubleshoot/azure/virtual-machines/allocation-failure
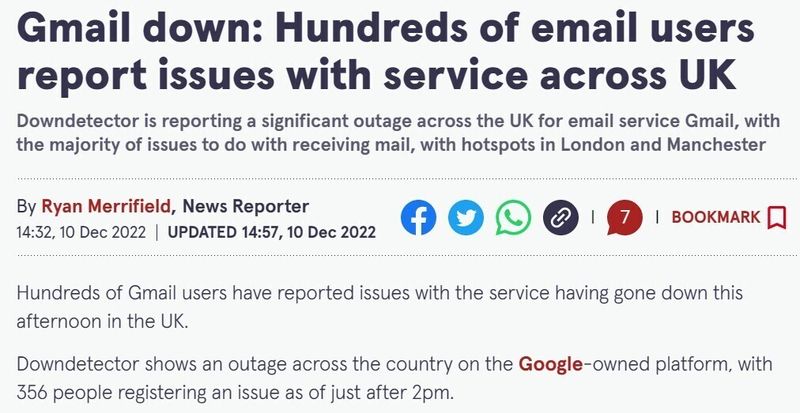
Source: https://www.mirror.co.uk/news/uk-news/breaking-gmail-down-hundreds-email-28701750

As a cloud consumer, you might be asking yourself, how do I mitigate such risks from affecting my production workloads? (Assuming your organization has already invested a lot of money and resources in the public cloud).
There is no one answer to this question, but in the following post, I will try to review some of the alternatives for protecting yourself or at least try to mitigate the risks.
Alternative 1 – Switching to a cloud-native application
This alternative takes full advantage of cloud benefits.
Instead of using VMs to run or process your workload, you will have to re-architect your application and use cloud-native services such as Serverless / Function as Service, managed services (from serverless database services, object storage, etc.), and event-driven services (such as Pub/Sub, Kafka, etc.)
Pros
- You decrease your application dependencies on virtual machines (on-demand, reserved instances, and even Spot instances), so resource allocation limits of VMs should be less concerning.
Cons
- Full re-architecture of your applications can be an expensive and time-consuming process. It requires a deep review of the entire application stack, understanding the application requirements and limitations, and having an experienced team of developers, DevOps, architects, and security personnel, knowledgeable enough about your target cloud providers ecosystem.
- The more you use a specific cloud’s ecosystem (such as proprietary Serverless / Function as a Service), the higher your dependency on specific cloud technology, which will cause challenges in case you are planning to switch to another cloud provider sometime in the future (or consider the use of multi-cloud).
Additional references:
- AWS - What Is Cloud Native?
- Azure - What is Cloud Native?
- Google Cloud - What is cloud-native?
- Oracle Cloud - What is Cloud Native?
Alternative 2 – The multi-region architecture
This alternative suggests designing a multi-region architecture, where you use several (separate) regions from your cloud provider of choice.
Pros
- The use of multi-region architecture will decrease the chance of having an outage of your services or the chance of having resource allocation issues.
Cons
- In case the cloud provider fails to create a complete separation between his regions (see: https://www.theguardian.com/technology/2020/dec/14/google-suffers-worldwide-outage-with-gmail-youtube-and-other-services-down), multi-region architecture will not resolve potential global outage issues (or limit the blast radius).
- In case you have local laws or regulations which force you to store personal data on data centers in a specific jurisdiction, a multi-region solution is not an option.
- Most IaaS / PaaS services offered today by cloud providers are regional, meaning, they are limited to a specific region and do not span across regions, and as a result, you will have to design a plan for data migration or synchronization across regions, which increases the complexity of maintaining this architecture.
- In a multi-region architecture, you need to take into consideration the cost of egress data between separate regions.
Additional refernces:
- AWS - Multi-Region Application Architecture
- Azure - Multi-region N-tier application
- Google Cloud - Creating multi-region deployments for API Gateway
- Oracle Cloud - Implementing a high-availability architecture in and across regions
- Using the Cloud to build multi-region architecture
Alternative 3 – Cloud agnostic architecture (or preparation for multi-cloud)
This alternative suggests using services that are available for all major cloud providers.
An example can be – to package your application inside containers and manage the containers orchestration using a Kubernetes-managed service (such as Amazon EKS, Azure AKS, Google GKE, or Oracle OKE).
To enable cloud agnostic architecture from day 1, consider provisioning all resources using HashiCorp Terraform – both for Kubernetes resources and any other required cloud service, with the relevant adjustments for each of the target cloud providers.
Pros
- Since container images can be stored in a container registry of your choice, you might be able to migrate between cloud providers.
Cons
- Using Kubernetes might resolve the problem of using the same underlining orchestrator engine, but you will still need to think about the entire cloud provider ecosystem (from data store services, queuing services, caching, identity authentication and authorization services, and more.
- In case you have already invested a lot of resources in a specific cloud provider and already stored a large amount of data in a specific cloud provider's storage service, migrating to another cloud provider will be an expensive move, not to mention the cost of egress data between different cloud providers.
- You will have to invest time in training your teams on working with several cloud providers' infrastructures and maintain several copies of your Terraform code, to suit each cloud provider infrastructure.
Summary
Although there is no full-proof answer to the question "How do I protect myself from the risk of a cloud outage or lack of cloud resources", we need to be aware of both types of risks.
We need to be able to explain the risks and the different alternatives provided in this post and explain them to our organization's top management.
Once we understand the risks and the pros and cons of each alternative, our organization will be able to decide how to manage the risk.
I truly believe that the future of IT is in the public cloud, but migrating to the cloud blindfolded, is the wrong way to fully embrace the potential of the public cloud.
About the Author
Eyal Estrin is a cloud and information security architect, the owner of the blog Security & Cloud 24/7 and the author of the book Cloud Security Handbook, with more than 20 years in the IT industry.
Eyal is an AWS Community Builder since 2020.
You can connect with him on Twitter and LinkedIn.

Top comments (0)