
We have been hearing the term "vibe coding" since early 2025, and perhaps the earliest time it was mentioned in a quote by Andrej Karpathy, one of the co-founders of OpenAI:
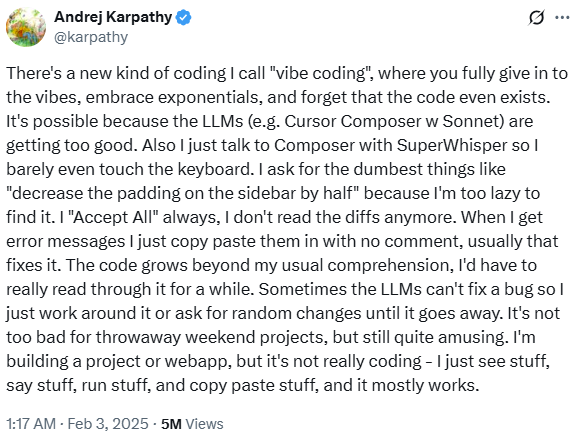
Source: https://x.com/karpathy/status/1886192184808149383
The key characteristics of vibe coding are:
- Developers communicate their requirements to the AI in natural language, rather than writing code directly.
- The AI handles the majority of code generation and modification, reducing manual intervention by the developer.
- Developers seldom review code differences or perform hands-on debugging; instead, errors are fed back to the AI for resolution.
- When issues arise, developers often paste error messages directly into the AI to prompt instant fixes or revisions.
- The focus is on rapid prototyping and experimentation, favoring quick iterations over meticulous, production-level refinement.
Not every use of AI code assistance qualifies as vibe coding. The focus is on creative momentum, rapid iteration, and minimal manual intervention in the code itself.
In contrast, traditional AI-assisted coding involves developers using AI features or tools - such as code suggestions, error detection, or automated completions - to support their workflow, but with the developer maintaining control.
Popular tools for vibe coding:
It sounds as if the AI assistant does most of the hard work for the developers, but what about the security consequences?
Vibe coding – common security vulnerabilities
Below is a list of common (and probably not the only) security vulnerabilities when using Vibe coding:
- Missing or Weak Input Validation: AI-generated code often skips robust input checks, making applications prone to injection attacks (such as SQL injection).
- Hardcoded Secrets and Credentials: LLMs frequently suggest or allow hardcoding of API keys, passwords, or cloud credentials directly in source code, which can result in secret leakage, especially if code is pushed to public repositories.
- Insecure Dependency Choices: AI can select outdated or insecure third-party libraries without security vetting, increasing exposure to known vulnerabilities.
- Generic or Poor Error Handling: Code produced by Vibe Coding may expose sensitive details through error messages, aiding attackers in reconnaissance.
- Improper Authentication and Authorization: Generated code often misses strong auth checks, leading to risks such as unauthorized access or privilege escalation.
- Path Traversal and Insecure File Handling: Some code suggestions are susceptible to file handling issues, allowing attackers to access or manipulate unintended files.
- Data Leakage via LLM Context: Vibe coding tools may inadvertently send proprietary or sensitive code/data snippets to cloud-based LLMs, risking privacy or regulatory non-compliance.
Recommendations for mitigating security vulnerabilities when using Vibe coding
Authentication and Authorization
Robust authentication and authorization are essential to ensure that only verified users can access sensitive resources and operations, protecting your application from unauthorized access and privilege escalation.
Recommendations for authentication and authorization
Implement Strong Authentication Mechanisms: Use secure authentication methods such as multi-factor authentication (MFA), OAuth2, or passwordless logins, and always securely store credentials (hashed and salted, never hardcoded in code or repositories). Examples of solutions for strong authentication: Amazon Cognito, Microsoft Entra ID, Google Identity Platform. Reference: OWASP Authentication Cheat Sheet.
Apply Role-Based Authorization and Least Privilege: Always check user roles before granting access to endpoints or resources and enforce the principle of least privilege so users and services can only access what they truly need. Examples of solutions: Amazon Verified Permissions, Microsoft Entra Role-based access control (RBAC), Open Policy Agent (OPA). Reference: OWASP Authorization Cheat Sheet.
Never Hardcode Secrets or Credentials: Always use environment variables or managed secrets for storing sensitive tokens and credentials.
Adopt Secure-by-Default Authentication Libraries : When using AI code generation, select trusted, well-maintained authentication/authorization libraries and frameworks, and prompt the AI to use them.
Always Review AI-Generated Auth Code: Carefully review and test all AI-generated authentication and authorization logic to ensure no bypass or privilege escalation vulnerabilities are introduced during rapid prototyping.
Prompts for Secure Vibe Coding: When using AI assistants, be explicit in your prompts:
"Generate an API endpoint that requires authentication using JWT and authorization based on user roles."
"Enforce that all sensitive API endpoints require the user to be authenticated and have admin privileges."
Data Sanitization
When working with LLMs, it is crucial to implement both input validation (for prompts coming from clients) and output validation (for answers returned from the LLM itself).
Recommendations for input validation
- Never trust user input: Always assume input can be malicious—verify all data from forms, URLs, APIs, and external sources, even in AI-generated code.
- Validate and sanitize every input: Use strict validation for type, length, range, and format. Remove or escape dangerous characters to prevent injection attacks like SQL injection, cross-site scripting (XSS), and command injection.
- Use parameterized queries for databases: Always use parameters or prepared statements for DB interactions to block SQL injection. Avoid string interpolation and raw queries unless you control all inputs.
- Validate on the server side: Do not rely solely on client-side validation. Ensure all critical input validations are enforced server-side, as client checks are easily bypassed.
- Regular code review and testing: Always review generated validation code and test for edge cases. AI may miss complex or context-specific validation needs. Examples of solutions: Amazon Q Developer, GitHub Advanced Security for Azure DevOps, Snyk Code, Semgrep.
Recommendations for output validation
- Escaping Output Content: Always escape dynamic data before rendering it in HTML, XML, or other user-facing contexts to prevent Cross-Site Scripting (XSS) and related injection attacks.
- Validate Output Format: Ensure that generated outputs (e.g., JSON, XML, HTML) strictly conform to the expected structure and type. This prevents data corruption and reduces the risk of format-based vulnerabilities.
- Enforce Output Constraints: Limit output to allowed values, length, and type, especially when returning results from AI-generated functions or APIs. This helps prevent leaking sensitive data and reduces the scope for exploitation.
- Sanitize Data Before Display: Before displaying or transmitting data generated from untrusted input, remove or encode any potentially dangerous content.
- Implement Content Security Policy (CSP): Where possible, establish CSP headers to mitigate the risk of client-side script injection via unsafe outputs.
- Review and Test Output Logic: Incorporate output validation as part of your verification protocol during code review. Test various edge cases and unexpected outputs to ensure accuracy and safety.
- Document Expected Output: In your prompts to the AI, clearly define the required output schema and format. For example: “Ensure the API returns only sanitized, non-sensitive fields as JSON.” Explicitly documenting expectations guides both the AI and human reviewers.
- Never Trust AI-Generated Outputs by Default: Treat all AI-generated outputs as untrusted until they’ve been validated by established business logic and security checks.
Additional references:
Secrets Management
As with any generated code, it is crucial to implement secrets management, instead of hard-coding static credentials as part of code, configurations, Git repositories, etc.
Recommendations for secrets management
- Never hardcode secrets in code: AI-generated code may suggest putting API keys, database passwords, or other credentials directly into source files. This is a major security risk as such secrets can easily end up in public repositories or be leaked. Reference: OWASP Secrets Management Cheat Sheet.
- Use environment variables for sensitive information: Always reference secrets like API keys through environment variables, not literal values in code. This isolates secrets from codebases and keeps them out of version control.
Leverage managed secrets storage: Use secure secret management services such as AWS Secrets Manager, Azure Key Vault, Google Secret Manager, or HashiCorp Vault. These services encrypt secrets and restrict access, reducing the risk of exposure.
Exclude secrets from version control: Add environment files (e.g., .env) to .gitignore and verify they are never committed to repositories.
Implement automated secrets scanning: Enable pre-commit hooks and automated scanning in your CI/CD pipeline to detect and block hardcoded secrets before they reach production or are pushed to shared repos. Example of solutions: Amazon CodeGuru Security, GitHub Advanced Security for Azure DevOps, GitLeaks, GitGuardian.
Enable secret rotation: Regularly rotate API keys and credentials so that if a secret is exposed, its usefulness to attackers is limited.
Educate and remind developers: Provide clear guidance and periodic training about secure coding practices and the dangers of hardcoding secrets, including the extra risks of vibe coding, where rapid prototyping often leads to shortcuts.
Audit and review AI-generated code: Always review code produced by AI for accidental secret exposures or insecure credential handling. Run static analysis and secret scanning tools during code review.
Respond immediately to leaks: If you suspect any secret has been exposed in code, treat it as compromised: revoke it, update dependencies, and rotate the secret without delay.
Handling Third-Party Components
Re-use of third-party components (such as binaries and libraries) is a well-known practice in many development projects, and Vibe coding is no different. When using external components, we need to recall that such code may introduce vulnerabilities that we are not aware of.
Recommendations for handling third-party components
- Integrate SCA Early and Continuously: Integrate software composition analysis (SCA) into your CI/CD pipeline for automated scans on every pull request. This detects and blocks vulnerable dependencies before they reach production. Examples of solutions: Amazon Inspector, GitHub Advanced Security for Azure DevOps, Google Artifact Analysis, Snyk Open Source, Jit Software Composition Analysis (SCA).
- Use Software Bill of Materials (SBOMs): Generate SBOMs for clarity and compliance, especially for customer-facing or regulated applications. Examples of solutions: Amazon Inspector SBOM Export, Microsoft Defender for Cloud, Google Artifact Analysis, Syft, Synk.
- Apply updates and patches: Routinely upgrade third-party libraries. Monitor for newly published vulnerabilities and prioritize necessary patches.
- Human and automated review: Always review AI-generated dependency choices and use security gates in CI/CD to block builds with critical issues.
- Continuous monitoring: Track production environments for vulnerable components or unpatched libraries.
Error Handling
Proper error handling is crucial because it ensures that software remains reliable, stable, and secure by gracefully managing unexpected issues, preventing crashes, protecting data, and providing helpful feedback to users and developers.
Recommendations for error handling
- Follow the Principle of Failing Securely (OWASP): Never reveal sensitive details (file paths, credentials, environment information) in error messages. Ensure error responses are generic for end users but detailed enough in logs for troubleshooting.
- Log Errors Explicitly and Securely: Log error details on the server side, including the relevant stack trace and request context, but never log sensitive data such as passwords or secret keys. Reference: OWASP Logging Cheat Sheet.
- Use Descriptive and Consistent Error Messages for Debugging: Make error messages clear and context-specific for maintainers—avoid ambiguous "something went wrong" responses—and follow structured error objects or codes.
- Revert Quickly if Needed: Use version control (e.g., Git) to manage code changes. If an AI-generated change causes new errors or instability, revert to a known good state promptly.
- Document Common and AI-Introduced Errors: Maintain a file or documentation tracking frequent AI mistakes and their resolutions. This speeds up future debugging and helps avoid recurring pitfalls.
- Ask AI for Error Explanations and Plans: Before accepting an AI-generated fix, prompt the model to explain the error, its impact, and its planned remediation. This helps you understand root causes and builds trust in the solution.
- Implement Monitoring and Alerting: Integrate real-time monitoring and alerting (such as Amazon CloudWatch Alarms, Azure Monitor Alerts, Google Cloud Observability Alerts) to detect and immediately respond to runtime errors in production environments.
Handling Data Leakage
Vibe coding increases the risk of data leakage, as AI-generated code may inadvertently expose sensitive information or secrets—such as API keys, credentials, or personal data—either through insecure patterns, improper handling, or by transmitting code context to external services without proper safeguards.
Recommendations for handling data leakage
- Implement strict access controls and secure authentication/authorization for all API endpoints to restrict exposure of sensitive data only to authorized users.
- Validate and sanitize all user inputs rigorously to prevent injection attacks and ensure sensitive information isn’t leaked through malicious input or error messages.
- Use HTTPS exclusively to encrypt all data in transit, preventing interception or eavesdropping.
- Review and test all AI-generated code for potential security flaws and data exposure issues before deploying to production, as AI models may generate insecure patterns or omit security controls.
- Educate developers about core security principles and the dangers of data leakage in AI-assisted workflows, including OWASP’s Data Protection and Secure Coding guidelines.
Reference: OWASP User Privacy Protection Cheat Sheet
Summary
In this blog post, I examined the common security risks associated with vibe coding and shared key recommendations to help mitigate them. As technology continues to evolve, new threats are likely to emerge, and the list of best practices will grow accordingly. I encourage developers to deepen their understanding of vibe coding, avoid blindly trusting AI-generated code, and embed security measures throughout the development lifecycle.
References:
- Cloud Security Alliance - Secure Vibe Coding Guide
- OWASP Top 10 for Large Language Model Applications
- AWS Vibe Coding Tips and Tricks
About the author
Eyal Estrin is a cloud and information security architect, an AWS Community Builder, and the author of the books Cloud Security Handbook and Security for Cloud Native Applications, with more than 25 years in the IT industry.
You can connect with him on social media (https://linktr.ee/eyalestrin).
Opinions are his own and not the views of his employer.

Top comments (2)
Interesting! I hadn't heard the term "vibe coding" before, but it resonates with a lot of the informal approaches I've seen in quick prototyping. It reminds me of those times you're just trying to get something, anything, working. When deadlines are tight, sometimes you're just hammering away until the code runs, almost like frantically tapping spacebar in the Dinosaur Game when a new obstacle comes! It seems like knowing the characteristics would be key to using it effectively and knowing when to switch to a more structured approach.
Hi
Some comments may only be visible to logged-in visitors. Sign in to view all comments.