
TL;DR: In this article, you will learn how to monitor the HTTP requests to your apps in Kubernetes and how to define autoscaling rules to increase and decrease replicas for your workloads.
Reducing infrastructure costs boils down to turning apps off when you don't use them.
That's easy to do manually, but how to turn them on automatically when you need them?
You can do so with a scale-to-zero strategy.
Let me show you how to implement it in Kubernetes.
Imagine you are running a reasonably resource-intensive app on the dev cluster.
Ideally, it's off when people leave the office and on when they start the day.
You could use a CronJob to scale up/down, but what happens during the weekend?
And public holidays?
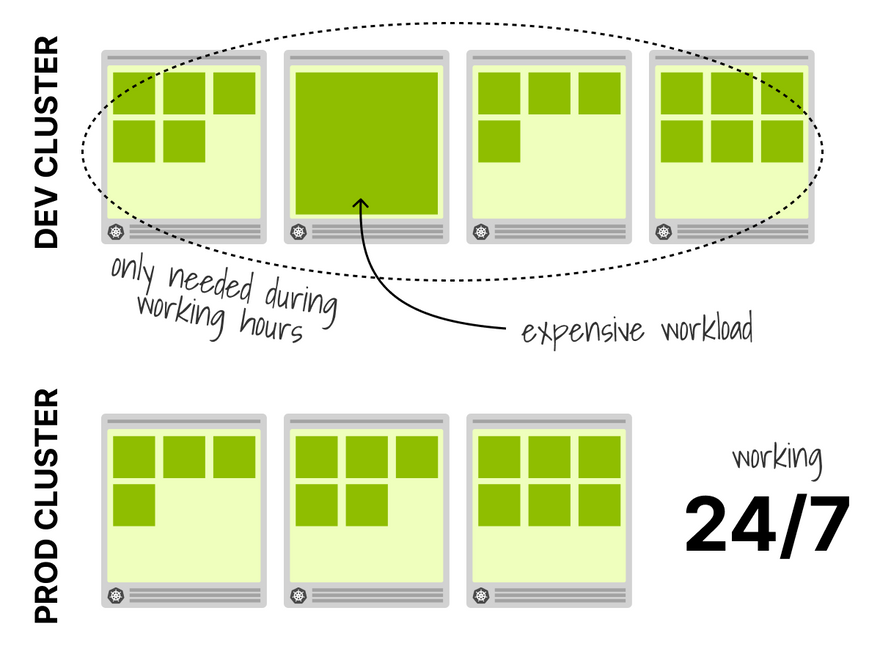
Instead of coming up with an evergrowing list of exceptions, you could scale up your workloads based on traffic:
- When there's traffic → autoscale on usage.
- When there is no traffic → turn off the app.
And that's the idea behind scaling to zero.
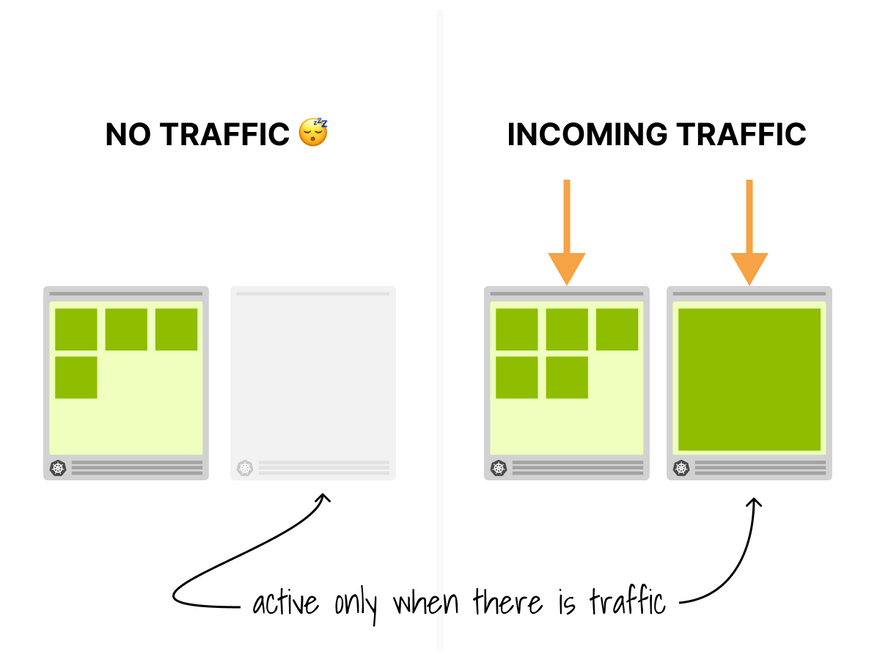
But what do you need to make it work?
The first step is collecting metrics and measuring the app traffic flow.
You could intercept the traffic by injecting a proxy in front.
The proxy could temporarily buffer requests when the app is scaled to 0.
When the app is ready, the proxy can forward all requests.
In Kubernetes, that's an extra proxy container in the Pod.
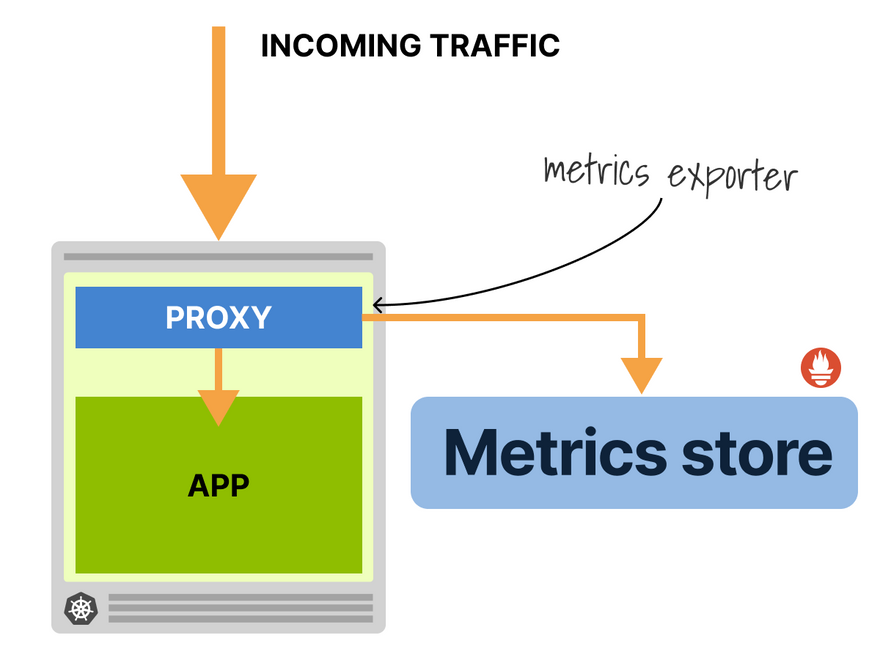
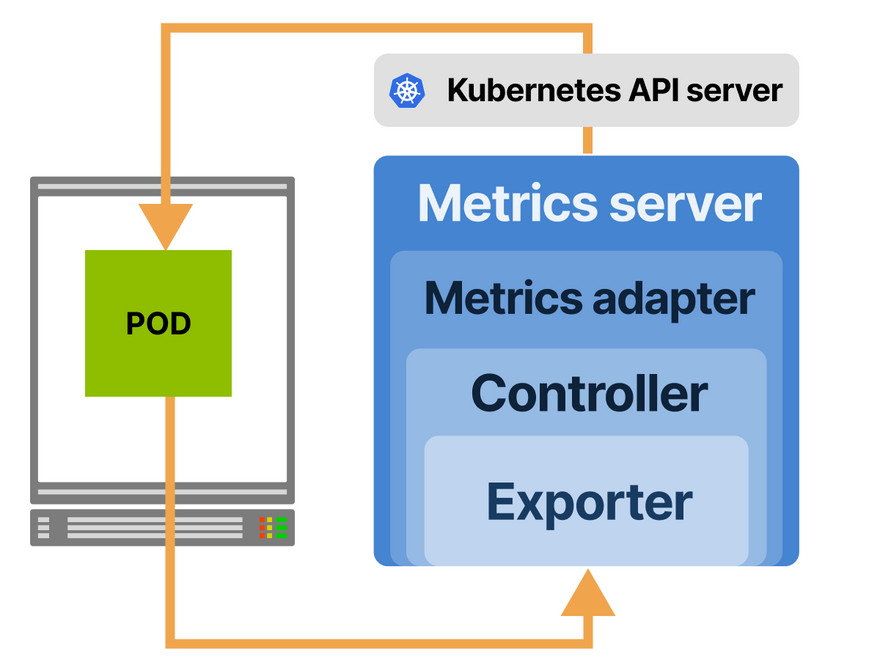
Once you have the metrics, you need two things:
- A metrics server to store and aggregate metrics (Kubernetes doesn't come with one by default).
- A way to export the metrics to the metrics server.
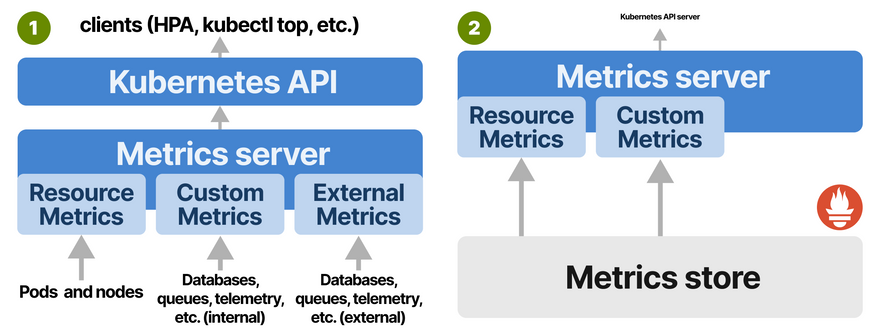
And finally, the last piece of the puzzle is the autoscaler.
You need to configure the Horizontal Pod Autoscaler to consume the metrics from the metrics server and adjust the replicas count accordingly.
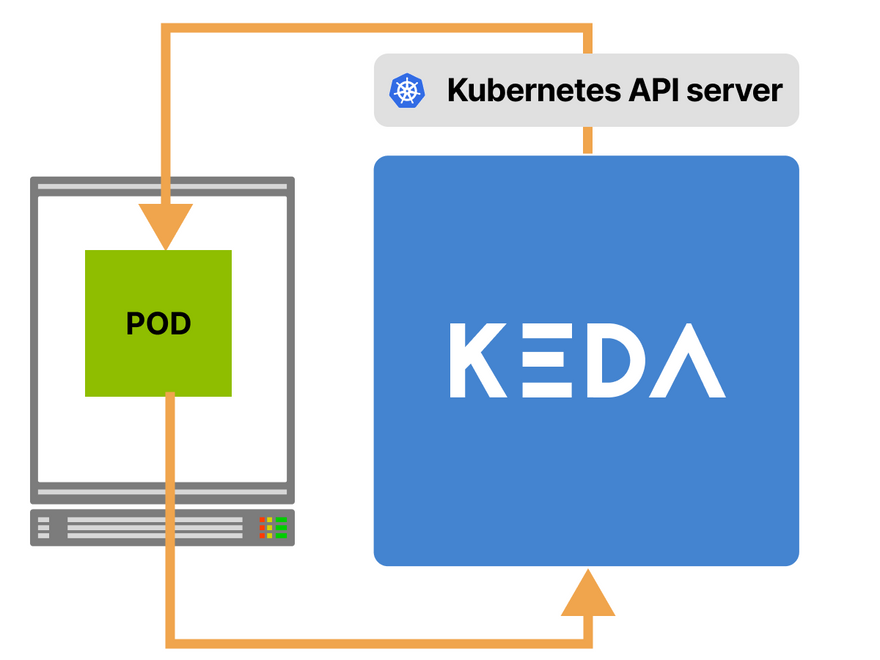
In Kubernetes, you can have exports, metrics servers and proxy bundled into one with KEDA.
KEDA is an event-driven autoscaler that implements the Custom Metrics API.
It's made of 3 components:
- A Scaler.
- A Metrics Adapter.
- A Controller.
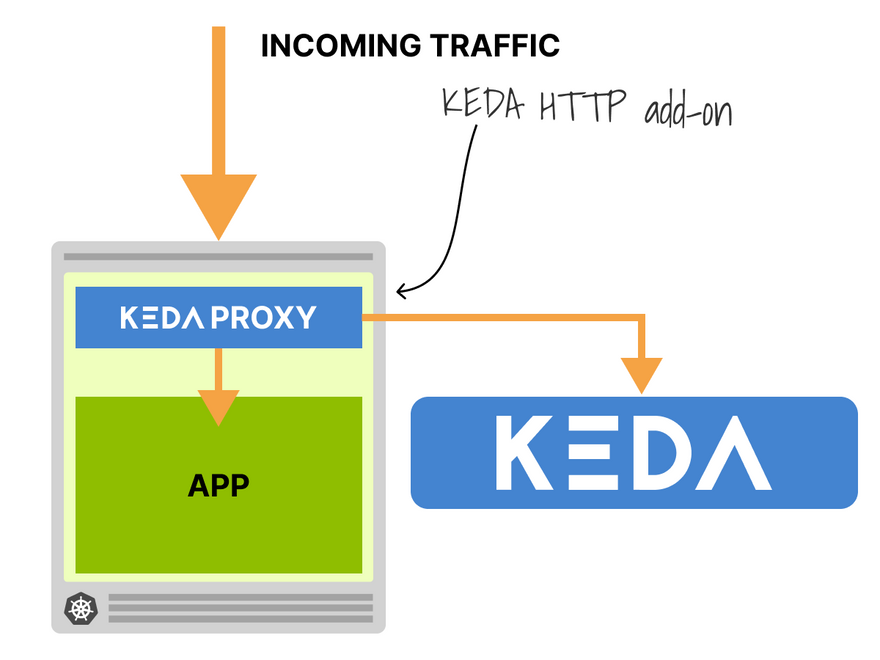
Scalers are like adapters that can collect metrics from databases, message brokers, telemetry systems etc.
KEDA has a special scaler that creates an HTTP proxy that measures and buffers requests before they reach the app.
KEDA's metrics adapter is responsible for exposing the metrics collected by the HTTP scaler in a format that the Kubernetes metrics pipeline can consume.
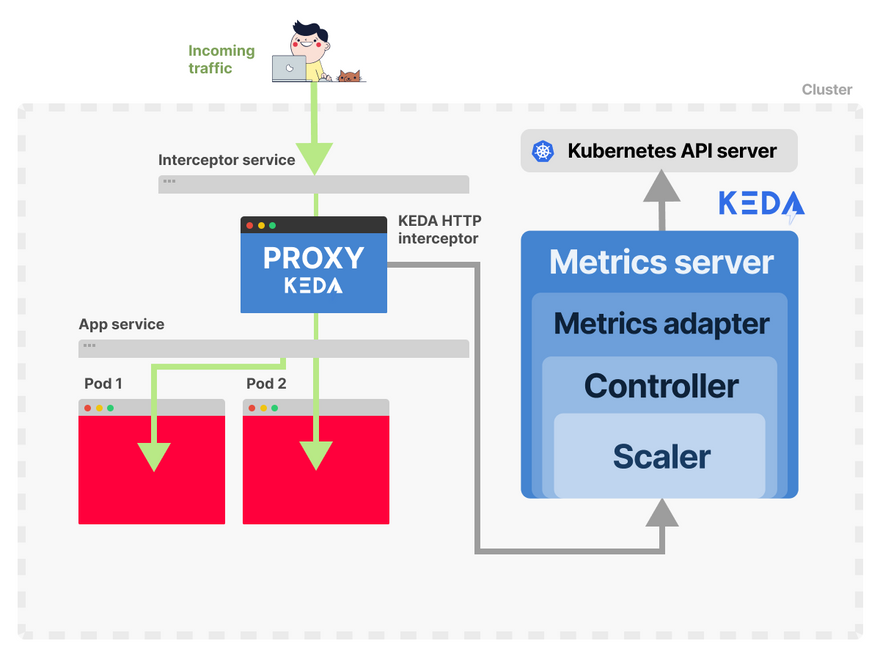
Finally, the KEDA controller glues all the components together:
- Collects the metrics using the adapter and exposes them to the metrics API.
- Registers and manages the KEDA-specific Custom Resource Definitions (CRDs).
- Creates and manages the Horizontal Pod Autoscaler.
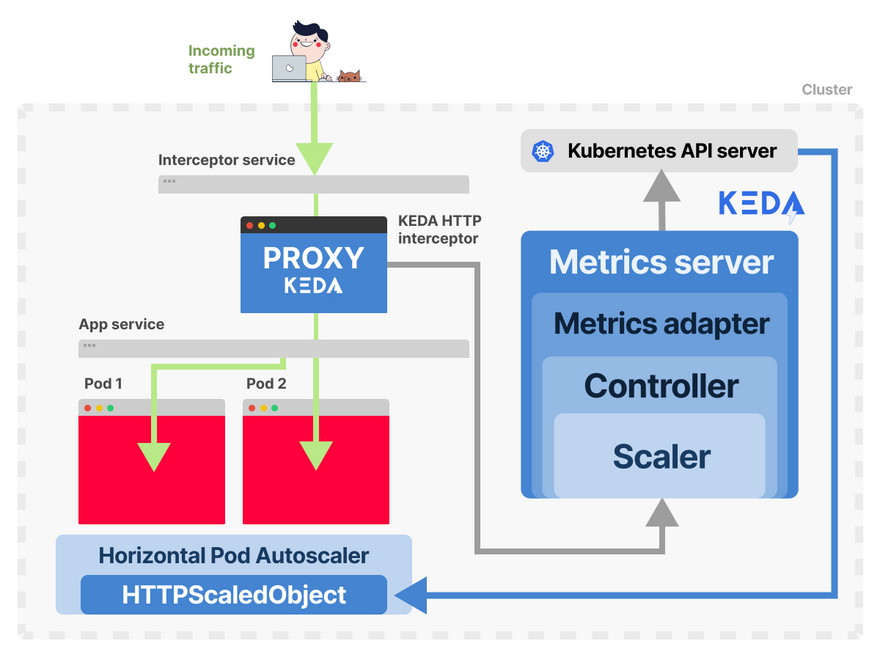
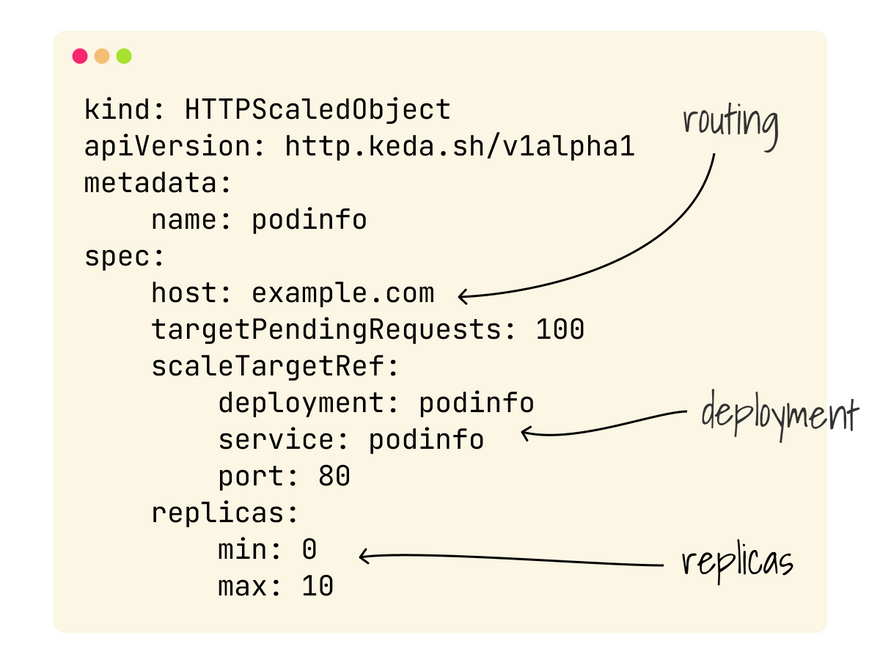
With KEDA, you don't create the Horizontal Pod Autoscaler (HPA).
Instead, you create an HTTPScaledObject, which is a wrapper around the HPA that includes:
- How to connect to the source of the metrics.
- How to route the traffic to the app.
- The settings to create the Horizontal Pod Autoscaler.
You can see the setup in action here.
- There is no active app.
- 6 requests are issued.
- Eventually, the app (octopus icon) appears and serves the six requests.

Scaling to zero… isn't that serverless? Not really.
Once scaled to at least one replica, the app still behaves as a regular app (e.g. it can handle hundreds of connections on its own).
Instead, serverless frameworks might create more functions to handle concurrent traffic.
Also, serverless frameworks handle incoming requests. You only have to define the application logic.
With a scale to zero, you are still handling the traffic.
If you wish to see this in action, Salman Iqbal demos scaling to zero here https://event.on24.com/wcc/r/3917950/F23E579DEBEB05039B2E2BEA1F6FF853?partnerref=learnk8s
And finally, if you've enjoyed this short post, you might also like the Kubernetes workshops that we run at Learnk8s or this collection of past Twitter threads https://twitter.com/danielepolencic/status/1298543151901155330.
Until next time!

Latest comments (0)