
1.Master the installation and environment configuration of spark
2.Master the installation and environment configuration of spark
3.Master Python version management and third-party installation under Ubuntu
4.Master the synchronous connection between pychar and Ubuntu under Windows
5.Master the data read by spark from the file system
Reference website:
https://spark.apache.org/docs/1.1.1/quick-start.html
1.Write first: experimental environment
You Must be have Hadoop environment,You can read my other blog:Click Here
Operating system: Ubuntu 16 04;
Spark version: 2.4.6;
Hadoop version: 2.7.2.
Python version: 3.5.
Click Here Download:spark-2.4.6-bin-without-hadoop.tgz
2.Master the installation and environment configuration of spark
1. Unzip the spark package and move it
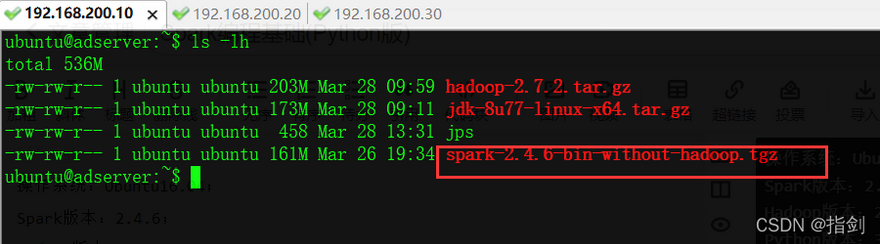
ubuntu@adserver:~$ tar zxf spark-2.4.6-bin-without-hadoop.tgz
ubuntu@adserver:~$ ls -lh
total 536M
-rw-rw-r-- 1 ubuntu ubuntu 203M Mar 28 09:59 hadoop-2.7.2.tar.gz
-rw-rw-r-- 1 ubuntu ubuntu 173M Mar 28 09:11 jdk-8u77-linux-x64.tar.gz
-rw-rw-r-- 1 ubuntu ubuntu 458 Mar 28 13:31 jps
drwxr-xr-x 13 ubuntu ubuntu 4.0K May 30 2020 spark-2.4.6-bin-without-hadoop
-rw-rw-r-- 1 ubuntu ubuntu 161M Mar 26 19:34 spark-2.4.6-bin-without-hadoop.tgz
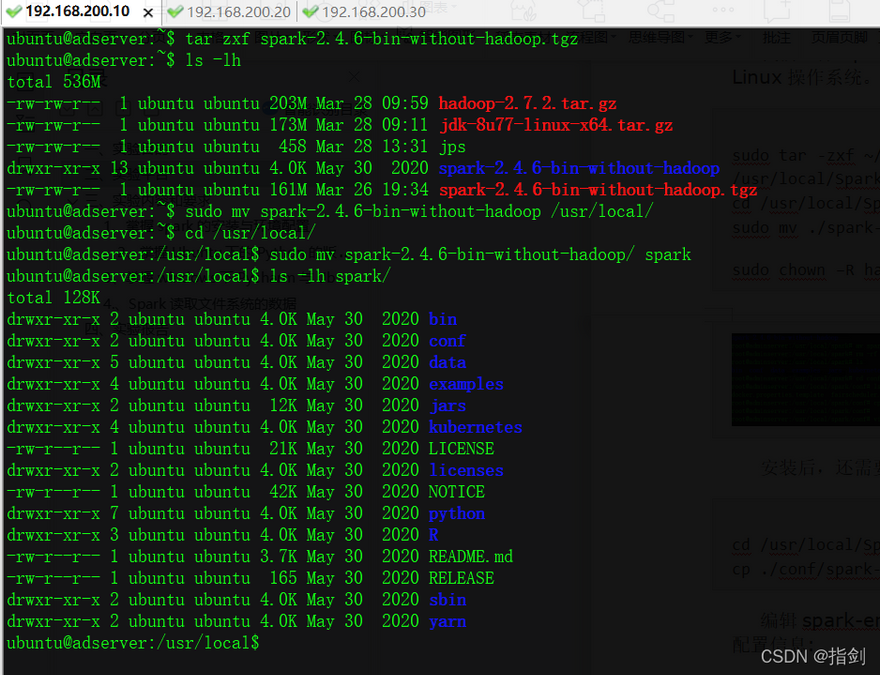
ubuntu@adserver:~$ sudo mv spark-2.4.6-bin-without-hadoop /usr/local/
ubuntu@adserver:~$ cd /usr/local/
ubuntu@adserver:/usr/local$ sudo mv spark-2.4.6-bin-without-hadoop/ spark
ubuntu@adserver:/usr/local$ ls -lh spark/
2.Modify spark environment variable file
ubuntu@adserver:~$ cd /usr/local/spark/conf/
ubuntu@adserver:/usr/local/spark/conf$ pwd
/usr/local/spark/conf
ubuntu@adserver:/usr/local/spark/conf$ cp spark-env.sh.template spark-env.sh
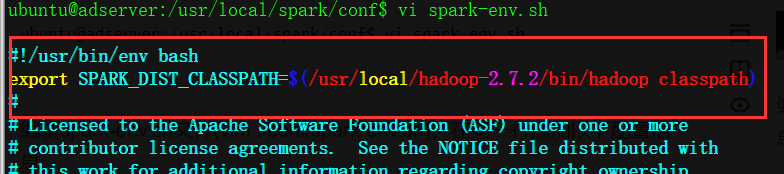
ubuntu@adserver:/usr/local/spark/conf$ vi spark-env.sh
Edit spark env SH file (vi ./conf/spark-env.sh), add the following configuration information on the first line:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-2.7.2/bin/hadoop classpath)
With the above configuration information, spark can store data in Hadoop distributed file system HDFS or read data from HDFS. If the above information is not configured, spark can only read and write local data, but cannot read and write HDFS data. After configuration, it can be used directly without running the startup command like Hadoop. Verify whether spark is successfully installed by running the example provided by spark.
During execution, a lot of running information will be output, and the output result is not easy to find. It can be filtered through the grep command (2 > & 1 in the command can output all information to stdout, otherwise it will be output to the screen due to the nature of the output log):
ubuntu@adserver:/usr/local/spark$ ./bin/run-example SparkPi 2>&1 | grep "Pi is"
Modify the contents of /usr/local/spark/bin/pyspark file
Change line 45 Python to python3
Execute commandsudo update-alternatives --install /usr/bin/python python /usr/bin/python3 150


ubuntu@adserver:/usr/local/spark/bin$ sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 150
3.Master Python version management and third-party installation under Ubuntu
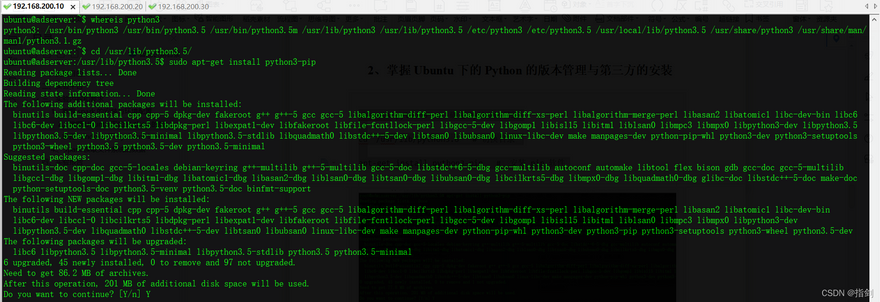
whereis python3 # Confirm Python 3 directory
cd /usr/lib/python3.5 # Switch directory
sudo apt-get install python3-pip # install pip
sudo pip3 install -i https://pypi.doubanio.com/simple matplotlib # install matplotlib
ubuntu@adserver:~$ whereis python3
python3: /usr/bin/python3 /usr/bin/python3.5 /usr/bin/python3.5m /usr/lib/python3 /usr/lib/python3.5 /etc/python3 /etc/python3.5 /usr/local/lib/python3.5 /usr/share/python3 /usr/share/man/man1/python3.1.gz
ubuntu@adserver:~$ cd /usr/lib/python3.5/
ubuntu@adserver:/usr/lib/python3.5$ sudo apt-get install python3-pip
ubuntu@adserver:/usr/lib/python3.5$ sudo pip3 install -i https://pypi.doubanio.com/simple matplotlib
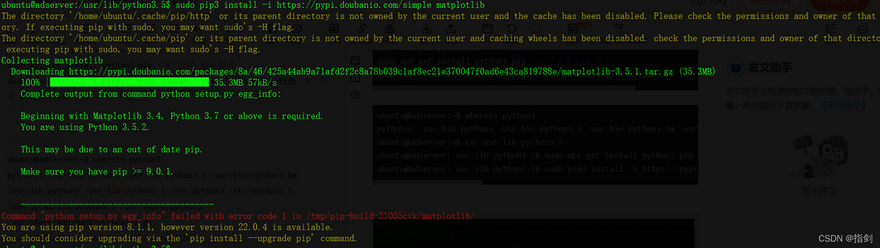
4.Master the synchronous connection between pychar and Ubuntu under Windows
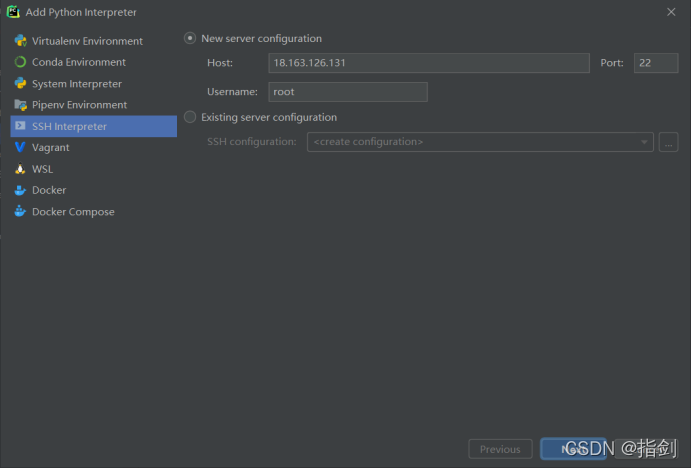
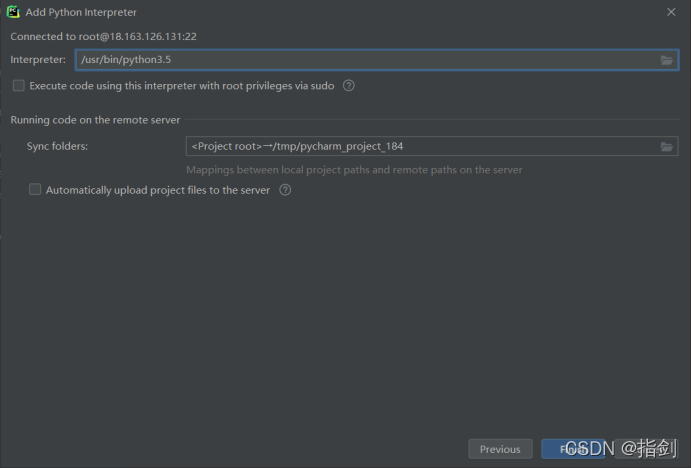
1) Open pychart and open file -- > settings -- >
Click the + sign, and then select SSH interpreter to set the server; Enter the IP address, user name and password of the virtual machine Ubuntu
5.Master the data read by spark from the file system
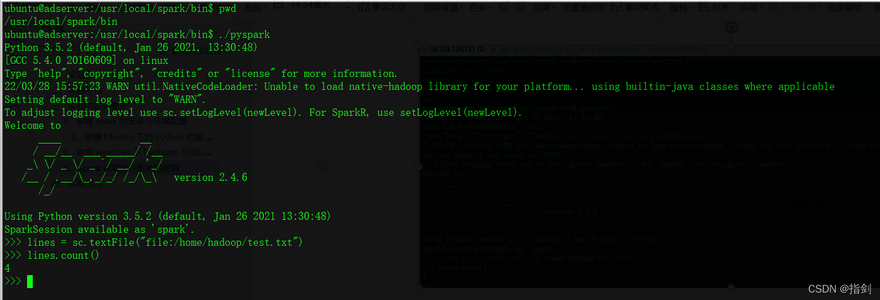
1)Read the local file "/home/Hadoop/test.txt" of Linux system in pyspark, and then count the number of lines of the file;
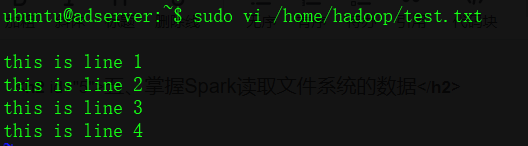
First create the test file
$ vi /home/hadoop/test.txt
this is line 1
this is line 2
this is line 3
this is line 4
ubuntu@adserver:/usr/local/spark/bin$ pwd
/usr/local/spark/bin
ubuntu@adserver:/usr/local/spark/bin$ ./pyspark
Python 3.5.2 (default, Jan 26 2021, 13:30:48)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
22/03/28 15:57:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Python version 3.5.2 (default, Jan 26 2021 13:30:48)
SparkSession available as 'spark'.
>>> lines = sc.textFile("file:/home/hadoop/test.txt")
>>> lines.count()
4
>>>
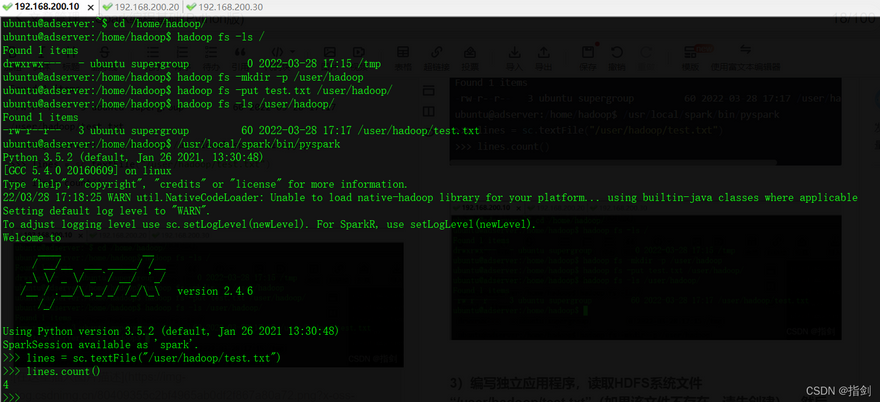
2)Read the HDFS system file "/user/Hadoop/test.txt" (if the file does not exist, please create it first), and then count the number of lines of the file;
ubuntu@adserver:~$ cd /home/hadoop/
ubuntu@adserver:/home/hadoop$ hadoop fs -ls /
Found 1 items
drwxrwx--- - ubuntu supergroup 0 2022-03-28 17:15 /tmp
ubuntu@adserver:/home/hadoop$ hadoop fs -mkdir -p /user/hadoop
ubuntu@adserver:/home/hadoop$ hadoop fs -put test.txt /user/hadoop/
ubuntu@adserver:/home/hadoop$ hadoop fs -ls /user/hadoop/
Found 1 items
-rw-r--r-- 3 ubuntu supergroup 60 2022-03-28 17:17 /user/hadoop/test.txt
ubuntu@adserver:/home/hadoop$ /usr/local/spark/bin/pyspark
>>> lines = sc.textFile("/user/hadoop/test.txt")
>>> lines.count()
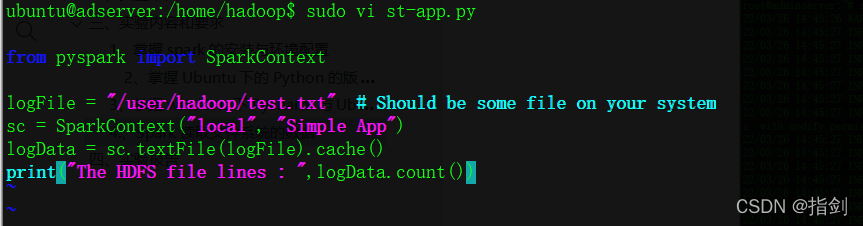
3)Write an independent application, read the HDFS system file "/user/Hadoop/test.txt" (if the file does not exist, please create it first), and then count the number of lines of the file;
ubuntu@adserver:/home/hadoop$ sudo vi st-app.py
from pyspark import SparkContext
logFile = "/user/hadoop/test.txt" # Should be some file on your system
sc = SparkContext("local", "Simple App")
logData = sc.textFile(logFile).cache()
print("The HDFS file lines : ",logData.count())
ubuntu@adserver:/home/hadoop$ /usr/local/spark/bin/spark-submit --master local[4] st-app.py 2>&1 | grep "The HDFS"


Top comments (2)
This is a great way to start learning Spark with Python! It shows the basics in a simple and clear way. Perfect for anyone new to big data.
Olá malta! Vi uma recomendação deste site num blogue de estilo de vida nacional. O slots dj destaca-se pela sua originalidade nas máquinas virtuais em Portugal. O que mais me interessou foram as slots inspiradas em concertos e festivais. Estava a pensar fazer uma pausa, mas um jackpot acumulado numa noite de sexta-feira resolveu tudo. É um local que recomendo pela transparência e pela excelente vibe que proporciona ao jogador.