
We use GitHub Actions for deployments, and eventually came to the point where we wanted to run its Runners on our own Kubernetes cluster because:
- self-hosted GitHub Runners are cheaper — in fact, you pay only for the servers that run the jobs
- we need to run SQL migrations on AWS RDS in AWS VPC Private Subnets
- performance — we can use any type of AWS EC2 and disk types, and do not limit ourselves to CPU/Memory and IOPS
General documentation — About self-hosted runners.
GitHub has a separate controller for this — Actions Runner Controller (ARC), which we will actually use.
We will run it on AWS Elastic Kubernetes Service v1.30, Karpenter v1.0 for EC2 scaling, and AWS Elastic Container Registry for Docker images.
Self-hosted runners have some Usage limits, but we are unlikely to encounter them.
So, what are we going to do today:
- with Helm, install the Runner Controller Actions and a Scale Set with Runners for the test repository to see how it all works in general
- will create a dedicated Karpenter NodePool with
taintsto run Runners on dedicated Kubernetes WorkerNodes - try out real builds and deploys for our Backend API to see what errors will occur
- will create our own Docker image for Runners
- try out the Docker in Docker mode
- create a separate Kubernetes StorageClass with high IOPS, and see how it affects the speed of build deployments
First, we’ll do everything manually, and then we’ll try to run a real build && deploy GitHub Actions Workflow.
GitHub Authentication
Documentation — Authenticating to the GitHub API.
There are two options here — a more proper for production using the GitHub App, or through a personal token.
GitHub App looks like a better solution, but we’re a small startup, and using a personal token will be easier, so we’ll do it this way for now, and_”later_” © if necessary, we’ll do it “the right way”.
Go to your profile, click Settings > Developer settings > Personal access tokens, click Generate new token (classic):

For now, we will use self-hosted runners for only one repository, so set the permissions only to the repo:
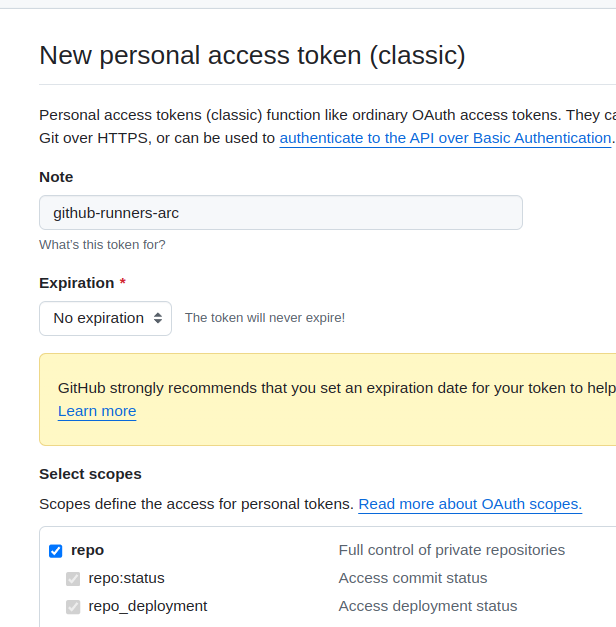
It would be good to set an expiration date, but this is a PoC (which will go into production later, as usual), so for now, OK — let it be forever.
Create a Kubernetes Namespace for runners:
$ kk create ns ops-github-runners-ns
namespace/ops-github-runners-ns created
Create a Kubernetes Secret with a token in it:
$ kk -n ops-github-runners-ns create secret generic gh-runners-token --from-literal=github_token='ghp_FMT***5av'
secret/gh-runners-token created
Check it:
$ kk -n ops-github-runners-ns get secret -o yaml
apiVersion: v1
items:
- apiVersion: v1
data:
github_token: Z2h***hdg==
kind: Secret
...
Running Actions Runner Controller with Helm
Actions Runner Controller consists of two parts:
-
gha-runner-scale-set-controller: the controller itself - its Helm-chart will create the necessary Kubernetes CRDs and run the controller Pods -
gha-runner-scale-set: responsible for launching Kubernetes Pods with GitHub Action Runners
There is also a legacy version — actions-runner-controller, but we will not use it.
Although the Scale Sets Controller is also called Actions Runner Controller in the documentation, and there is also a legacy Actions Runner Controller… A bit confusing, so keep in mind that some of the googled examples/documentation may be about the legacy version.
Documentation — Quickstart for Actions Runner Controller, or the full version — Deploying runner scale sets with Actions Runner Controller.
Installing Scale Set Controller
Create a separate Kubernetes Namespace for the Controller:
$ kk create ns ops-github-controller-ns
namespace/ops-github-controller-ns created
Install the chart — its values is quite simple, no updates are required:
$ helm -n ops-github-controller-ns upgrade --install github-runners-controller \
> oci://ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set-controller
Check Pods:
$ kk -n ops-github-controller-ns get pod
NAME READY STATUS RESTARTS AGE
github-runners-controller-gha-rs-controller-5d6c6b587d-fv8bz 1/1 Running 0 2m26s
Check new CRDs:
$ kk get crd | grep github
autoscalinglisteners.actions.github.com 2024-09-17T10:41:28Z
autoscalingrunnersets.actions.github.com 2024-09-17T10:41:29Z
ephemeralrunners.actions.github.com 2024-09-17T10:41:29Z
ephemeralrunnersets.actions.github.com 2024-09-17T10:41:30Z
Installing Scale Set for GitHub Runners
Each Scale Set (the AutoscalingRunnerSet resource) is responsible for specific Runners that we will use through runs-on in workflow files.
Set two environment variables — later we will pass this through our own values file:
-
INSTALLATION_NAME: the name of the runners (in thevaluesit can be set through therunnerScaleSetNameparameter) -
GITHUB_CONFIG_URL: URL of a GitHub Organization or repository in thehttps://github.com/<ORG_NAME>/<REPO_NAME>format
$ INSTALLATION_NAME="test-runners"
$ GITHUB_CONFIG_URL="https://github.com/***/atlas-test"
Install the chart, pass githubConfigUrl and githubConfigSecret - here we already have a created Kubernetes Secret, so use it:
$ helm -n ops-github-runners-ns upgrade --install test-runners \
> --set githubConfigUrl="${GITHUB_CONFIG_URL}" \
> --set githubConfigSecret=gh-runners-token \
> oci://ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set
Once again, check the Pods in the controller’s Namespace, a new one should be added named test-runners-*-listener — it will be responsible for launching Pods with Runners for the_”test-runners_” pool:
$ kk -n ops-github-controller-ns get pod
NAME READY STATUS RESTARTS AGE
github-runners-controller-gha-rs-controller-5d6c6b587d-fv8bz 1/1 Running 0 8m38s
test-runners-694c8c97-listener 1/1 Running 0 40s
And it’s created from the AutoscalingListeners resource:
$ kk -n ops-github-controller-ns get autoscalinglisteners
NAME GITHUB CONFIGURE URL AUTOSCALINGRUNNERSET NAMESPACE AUTOSCALINGRUNNERSET NAME
test-runners-694c8c97-listener https://github.com/***/atlas-test ops-github-runners-ns test-runners
Check the Pods in the Namespace for the Runners — it’s empty yet:
$ kk -n ops-github-runners-ns get pod
No resources found in ops-github-runners-ns namespace.
Actually, that’s all you need to start with — you can try running jobs.
Testing Runners with a GitHub Actions Workflow
Let’s try to run a minimal build just to make sure that the setup works in general.
In a test repository, create a .github/workflows/test-gh-runners.yml file.
In the runs-on set the name of our runner pool - test-runners:
name: "Test GitHub Runners"
concurrency:
group: github-test
cancel-in-progress: false
on:
workflow_dispatch:
permissions:
# allow read repository's content by steps
contents: read
jobs:
aws-test:
name: Test EKS Runners
runs-on: test-runners
steps:
- name: Test Runner
run: echo $HOSTNAME
Push the changes to the repository, run the build, wait a minute, and you have to see a name of the Runner:
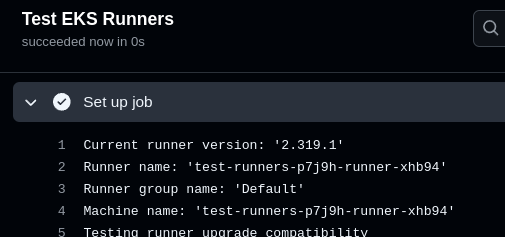
Check Pods in Kubernetes:
$ kk -n ops-github-runners-ns get pod
NAME READY STATUS RESTARTS AGE
test-runners-p7j9h-runner-xhb94 1/1 Running 0 6s
The same Runner and a corresponding Runner Scale Set will be displayed in the repository Settings > Actions > Runners:
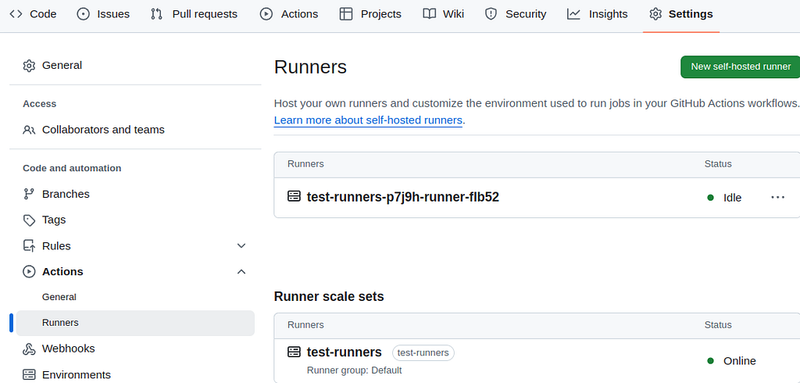
And the Job is finished:

Okay — it works. What’s next?
- we need to create a Karpenter NodePool of servers exclusively for GitHub Runners
- need to configure
requestsfor Runner Pods - need to see how we can build Docker images in the Runners
Creating Karpenter NodePool
Let’s create a dedicated Karpenter NodePool with taints so that only Pods with GitHub Runners will run on these EC2s (see Kubernetes: Pods and WorkerNodes – control the placement of the Pods on the Nodes):
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: github1abgt
spec:
weight: 20
template:
metadata:
labels:
created-by: karpenter
component: devops
spec:
taints:
- key: GitHubOnly
operator: Exists
effect: NoSchedule
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: defaultv1a
requirements:
- key: karpenter.k8s.aws/instance-family
operator: In
values: ["c5"]
- key: karpenter.k8s.aws/instance-size
operator: In
values: ["large", "xlarge"]
- key: topology.kubernetes.io/zone
operator: In
values: ["us-east-1a"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
# total cluster limits
limits:
cpu: 1000
memory: 1000Gi
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 600s
budgets:
- nodes: "1"
I didn’t tweak the instance types here, just copied our NodePool for the Backend API, and then we’ll see how many resources the runners will use to work and will change the EC2 types accordingly.
It also makes sense to tune the disruption parameters - consolidationPolicy, consolidateAfter, and budgets. For example, if all developers work in the same timezone, you may allow performing the WhenEmptyOrUnderutilized at night, and delete Nodes by the WhenEmpty only during the day. Also, you may set a higher consolidateAfter value so that new GitHub Actions Jobs do not wait too long for EC2 creation. See Karpenter: an introduction to the Disruption Budgets.
Helm and Scale Set deployment automation
There are several options here:
- we can use the Terraform
resource helm_release - we can create our own Helm chart, and install GitHub Runners charts with it via Helm Dependency
Or we can do it even simpler — create a repository with configuration and values, add a Makefile, and deploy manually for now.
I’ll most likely will mix the both:
- the Controller itself will be installed from a Terraform code that deploys the entire Kubernetes cluster, as we have other controllers like ExternalDNS, ALB Ingress Controller, etc installed there
- to create Scale Sets with pools of Runners for each repository, I will make a dedicated Helm chart in a separate repository, and in it will add config files for each runner pool
- but while it is still in PoC — then Scale Sets will be installed from a
Makefilethat executeshelm install -f values.yaml
So, for now, create our own values.yaml, set the runnerScaleSetName, requests and tolerations to the tains from our NodePool:
githubConfigUrl: "https://github.com/***/atlas-test"
githubConfigSecret: gh-runners-token
runnerScaleSetName: "test-runners"
template:
spec:
containers:
- name: runner
image: ghcr.io/actions/actions-runner:latest
command: ["/home/runner/run.sh"]
resources:
requests:
cpu: 1
memory: 1Gi
tolerations:
- key: "GitHubOnly"
effect: "NoSchedule"
operator: "Exists"
Add a simple Makefile:
deploy-helm-runners-test:
helm -n ops-github-runners-ns upgrade --install test-eks-runners -f test-github-runners-values.yaml oci://ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set
Deploy the chart:
$ make deploy-helm-runners-test
Check that the configuration of this Runners’ pool has changed:
$ kk -n ops-github-runners-ns describe autoscalingrunnerset test-runners
Name: test-runners
Namespace: ops-github-runners-ns
...
API Version: actions.github.com/v1alpha1
Kind: AutoscalingRunnerSet
...
Spec:
Github Config Secret: gh-runners-token
Github Config URL: https://github.com/***/atlas-test
Runner Scale Set Name: test-runners
Template:
Spec:
Containers:
Command:
/home/runner/run.sh
Image: ghcr.io/actions/actions-runner:latest
Name: runner
Resources:
Requests:
Cpu: 1
Memory: 1Gi
Restart Policy: Never
Service Account Name: test-runners-gha-rs-no-permission
Tolerations:
Effect: NoSchedule
Key: GitHubOnly
Operator: Exists
To verify that the new Karpenter NodePool will be used, run a test build and check NodeClaims:
$ kk get nodeclaim | grep git
github1abgt-dq8v5 c5.large spot us-east-1a Unknown 20s
OK, the instance is created, and we have a new Runner there:
$ kk -n ops-github-runners-ns get pod
NAME READY STATUS RESTARTS AGE
test-runners-6s8nd-runner-2s47n 0/1 ContainerCreating 0 45s
Everything works here.
Building a real Backend API job
And now let’s try to run a build and deploy of our Backend with real code and GitHub Actions Workflows.
Create a new values file for a new pool of Runners:
githubConfigUrl: "https://github.com/***/kraken"
githubConfigSecret: gh-runners-token
runnerScaleSetName: "kraken-eks-runners"
...
Deploy the new Scale Set:
$ helm -n ops-github-runners-ns upgrade --install kraken-eks-runners \
> -f kraken-github-runners-values.yaml \
> oci://ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set
Edit the project workflow — change runs-on: ubuntu-latest to runs-on: kraken-eks-runners:
...
jobs:
eks_build_deploy:
name: "Build and/or deploy backend"
runs-on: kraken-eks-runners
...
Launch the build, and a new Pod is created:
$ kk -n ops-github-runners-ns get pod
NAME READY STATUS RESTARTS AGE
kraken-eks-runners-pg29x-runner-xwjxx 1/1 Running 0 11s
And the build is running:
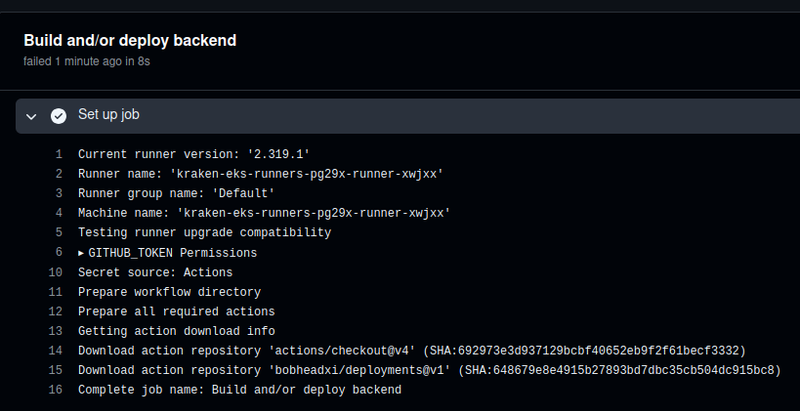
But then it immediately crashed with errors that it couldn’t find make and git:
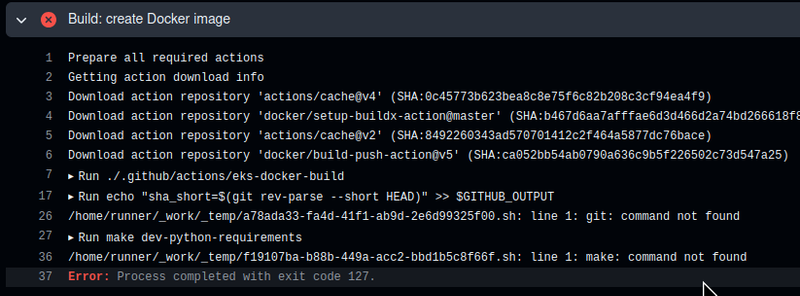
GitHub Runners image and “git: command not found”
Let’s check it manually by running ghcr.io/actions/actions-runner:latest Docker image locally:
$ docker run -ti ghcr.io/actions/actions-runner:latest bash
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
runner@c8aa7e25c76c:~$ make
bash: make: command not found
runner@c8aa7e25c76c:~$ git
bash: git: command not found
The fact that there is no make is understandable. But on GitHub Runners don't add the git out of the box"?
In this GitHub Issue, people are also surprised by this decision.
But okay… We have what we have. What we can do is to create our own image using ghcr.io/actions/actions-runner as a base, and install everything that we need to be happy.
See Software installed in the ARC runner image. There are also other non-GitHub Runners images, but I haven’t tried them.
So, our basic GitHub Runners image uses Ubuntu 22.04, so we can install all the necessary packages with apt.
Create a Dockerfile - I've already added the AWS CLI and several packages for Python:
FROM ghcr.io/actions/actions-runner:latest
RUN sudo curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | sudo bash
RUN sudo apt update && \
sudo apt -y install git make python3-pip awscli python3-venv
Also, warnings like this possible:
WARNING: The script gunicorn is installed in ‘/home/runner/.local/bin’ which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use — no-warn-script-location.
So in the Dockerfile I also added the PATH variable definition:
FROM ghcr.io/actions/actions-runner:latest
ENV PATH="$PATH:/home/runner/.local/bin"
RUN sudo curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | sudo bash
RUN sudo apt update && \
sudo apt -y install git make python3-pip awscli python3-venv
Create a repository in AWS ECR:
Build the image:
$ docker build -t 492***148.dkr.ecr.us-east-1.amazonaws.com/github-runners/kraken -f Dockefile.kraken .
Log in to the ECR:
$ aws --profile work ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin 492***148.dkr.ecr.us-east-1.amazonaws.com
Push the image:
$ docker push 492***148.dkr.ecr.us-east-1.amazonaws.com/github-runners/kraken
Change the image in your values:
...
runnerScaleSetName: "kraken-eks-runners"
template:
spec:
containers:
- name: runner
image: 492***148.dkr.ecr.us-east-1.amazonaws.com/github-runners/kraken:latest
command: ["/home/runner/run.sh"]
...
Deploy it, run the build, and we have a new problem.
The “Cannot connect to the Docker daemon” error, and Scale Set containerMode "Docker in Docker"
Now there is a problem with Docker:
Docker: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
Because during the build of our Backend, another Docker container is launched to generate Open API docs.
Therefore, in our case, we need to use Docker in Docker (although I really don’t like it).
GitHub documentation — Using Docker-in-Docker mode.
In Scale Sets, there is a dedicated parameter for this: containerMode.type=dind.
Add it to the values:
...
runnerScaleSetName: "kraken-eks-runners"
containerMode:
type: "dind"
template:
spec:
...
Deploy the Helm chart, and now we have two containers in the Runner Pod — one is the runner itself, the other is dind:
==> New container [kraken-eks-runners-trb9h-runner-klfxk:dind]
==> New container [kraken-eks-runners-trb9h-runner-klfxk:runner]
Run the build again, and… We have a new error :-)
Hello DinD and Docker volumes.
The error looks like this:
Error: ENOENT: no such file or directory, open ‘/app/openapi.yml’
Docker in Docker, and Docker volumes
The issue happens because the Backend API code creates a directory in /tmp, in which the openapi.yml file is generated, from which an HTML file with documentation is then generated:
...
def generate_openapi_html_definitions(yml_path: Path, html_path: Path):
print("Running docker to generate HTML")
app_volume_path = Path(tempfile.mkdtemp())
(app_volume_path / "openapi.yml").write_text(yml_path.read_text())
if subprocess.call(
[
"docker",
"run",
"-v",
f"{app_volume_path}:/app",
"--platform",
"linux/amd64",
"-e",
"yaml_path=/app/openapi.yml",
"-e",
"html_path=/app/openapi.html",
"492***148.dkr.ecr.us-east-1.amazonaws.com/openapi-generator:latest",
]
):
...
Here Path(tempfile.mkdtemp()) creates a new directory in the /tmp - but this is executed inside the container kraken-eks-runners-trb9h-runner-klfxk: runner , while the docker run -v f"{app_volume_path}:/app" operation runs inside the kraken-eks-runners-trb9h-runner-klfxk: dind container.
Let’s just take a look at the pod manifest:
$ kk -n ops-github-runners-ns describe autoscalingrunnerset kraken-eks-runners
...
Template:
Spec:
Containers:
...
Image: 492***148.dkr.ecr.us-east-1.amazonaws.com/github-runners/kraken:0.8
Name: runner
...
Volume Mounts:
Mount Path: /home/runner/_work
Name: work
...
Image: docker:dind
Name: dind
...
Volume Mounts:
Mount Path: /home/runner/_work
Name: work
...
That is, both containers have a common directory /home/runner/_work, which is created on the host/EC2, and mounted to a Kubernetes Pod to both Docker containers.
And the /tmp directory in the runner container is "local" to it, and is not accessible by the container with dind.
Therefore, as an option — just create a new directory for the openapi.yml file inside /home/runner/_work:
...
# get $HONE, fallback to the '/home/runner'
home = os.environ.get('HOME', '/home/runner')
# set app_volume_path == '/home/runner/_work/tmp/'
app_volume_path = Path(home) / "_work/tmp/"
# mkdir recursive, exist_ok=True in case the dir already created by openapi/asyncapi
app_volume_path.mkdir(parents=True, exist_ok=True)
(app_volume_path / "openapi.yml").write_text(yml_path.read_text())
...
Or do even better — in case the build will be running on GitHub hosted Runners, add a check on which Runner the job is running on, and choose where to create the directory accordingly.
Add a RUNNER_EKS variable to the values of our Scale Set:
...
template:
spec:
containers:
- name: runner
image: 492***148.dkr.ecr.us-east-1.amazonaws.com/github-runners/kraken:0.8
command: ["/home/runner/run.sh"]
env:
- name: RUNNER_EKS
value: "true"
...
And in the code, check this variable, and depending on it, set the app_volume_path directory:
...
# our runners will have the 'RUNNER_EKS=true'
if os.environ.get('RUNNER_EKS', '').lower() == 'true':
# Get $HOME, fallback to the '/home/runner'
home = os.environ.get('HOME', '/home/runner')
# Set app_volume_path to the '/home/runner/_work/tmp/'
app_volume_path = Path(home) / "_work/tmp/"
# mkdir recursive, exist_ok=True in case the dir already created by openapi/asyncapi
app_volume_path.mkdir(parents=True, exist_ok=True)
# otherwize if it's a GitHub hosted Runner without the 'RUNNER_EKS', use the old code
else:
app_volume_path = Path(tempfile.mkdtemp())
(app_volume_path / "openapi.yml").write_text(yml_path.read_text())
...
Run the build again, and now everything works:

The “Access to the path ‘/home/runner/_work/_temp/_github_home/.kube/cache’ is denied” error
Sometimes there is also a problem when at the end of the build deployment, the job ends with the message ”Error: The opeation was canceled ”:
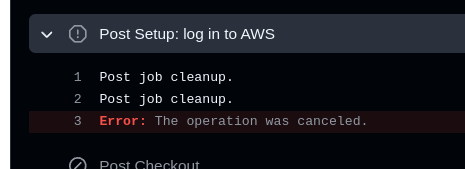
The cause for this can be found in the runner logs — it cannot delete the _github_home/.kube/cache directory:
...
kraken-eks-runners-wwn6k-runner-zlw7s:runner [WORKER 2024-09-20 10:55:23Z INFO TempDirectoryManager] Cleaning runner temp folder: /home/runner/_work/_temp
kraken-eks-runners-wwn6k-runner-zlw7s:runner [WORKER 2024-09-20 10:55:23Z ERR TempDirectoryManager] System.AggregateException: One or more errors occurred. (Access to the path '/home/runner/_work/_temp/_github_home/.kube/cache' is denied.)
kraken-eks-runners-wwn6k-runner-zlw7s:runner [WORKER 2024-09-20 10:55:23Z ERR TempDirectoryManager] ---> System.UnauthorizedAccessException: Access to the path '/home/runner/_work/_temp/_github_home/.kube/cache' is denied.
kraken-eks-runners-wwn6k-runner-zlw7s:runner [WORKER 2024-09-20 10:55:23Z ERR TempDirectoryManager] ---> System.IO.IOException: Permission denied
...
And indeed, if we check the /home/runner/_work/_temp/_github_home/ directory from the runner container, it does not have access to it:
runner@kraken-eks-runners-7pd5d-runner-frbbb:~$ ls -l /home/runner/_work/_temp/_github_home/.kube/cache
ls: cannot open directory '/home/runner/_work/_temp/_github_home/.kube/cache': Permission denied
But access is available from a container with dind, which this directory creates:
/ # ls -l /home/runner/_work/_temp/_github_home/.kube/cache
total 0
drwxr-x--- 3 root root 78 Sep 24 08:36 discovery
drwxr-x--- 3 root root 313 Sep 24 08:36 http
In this case, it is created from root, although the rest of the directories are created from user 1001:
/ # ls -l /home/runner/_work/_temp/
total 40
-rw-r--r-- 1 1001 1001 71 Sep 24 08:36 79b35fe7-ba51-47fc-b5a2-4e4cdf227076.sh
drwxr-xr-x 2 1001 1001 24 Sep 24 08:31 _github_workflow
...
And 1001 is the runner user from the runner container:
runner@kraken-eks-runners-7pd5d-runner-frbbb:~$ id runner
uid=1001(runner) gid=1001(runner) groups=1001(runner),27(sudo),123(docker)
Interestingly, the error does not occur all the time, but from time to time, although the workflow itself does not changes.
The .kube/config directory is created from the bitovi/github-actions-deploy-eks-helm action, which runs aws eks update-kubeconfig from its own Docker container, and is run as a root because it runs in Docker in Docker.
To solve the issue, two options come to mind:
- either simply add a crutch in the form of an additional command
chown -r 1001:1001 /home/runner/_work/_temp/_github_home/.kube/cacheat the end of the deploy (although you can use the same crutch to simply delete the directory) - or change
GITHUB_HOMEto another directory, and thenaws eks update-kubeconfigwill create the.kube/cachedirectory in another place, and the container with therunnerwill be able to perform Clean runner temp folder
However, I still don’t understand why Cleaning runner temp folder doesn’t work every time, and therefore it’s a “floating bug”. Let’s see how it will work in the future.
Attaching a High IOPS Volume
One of the reasons we want to switch to self-hosted Runners is to speed up builds and deployments.
The most time during build is taken by the commands like docker load && docker save.
Therefore, I want to try to connect an AWS EBS with high IOPS, because the default gp2 has 100 IOPS for each GB of size - see Amazon EBS volume types.
Create a new Kubernetes StorageClass:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: gp3-iops
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp3
iopsPerGB: "16000"
throughput: "1000"
allowVolumeExpansion: true
volumeBindingMode: WaitForFirstConsumer
In the values of our Runners’ pool, add the volumes block, where we override the parameters for the work disk, which is created by default from emptyDir: {} .
Set a new storageClassName here:
githubConfigUrl: "https://github.com/***/kraken"
githubConfigSecret: gh-runners-token
runnerScaleSetName: "kraken-eks-runners"
containerMode:
type: "dind"
template:
spec:
containers:
- name: runner
image: 492***148.dkr.ecr.us-east-1.amazonaws.com/github-runners/kraken:0.9
command: ["/home/runner/run.sh"]
env:
- name: RUNNER_EKS
value: "true"
resources:
requests:
cpu: 2
memory: 4Gi
volumes:
- name: work
ephemeral:
volumeClaimTemplate:
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "gp3-iops"
resources:
requests:
storage: 10Gi
Deploy these changes for the AutoscalingRunnerSet, run our deployment, and the Pods with Runners are created, but are immediately killed, and the job itself is failed.
The “Access to the path ‘/home/runner/_work/_tool’ is denied” error
Check the Runner logs again, and see that:
kraken-eks-runners-gz866-runner-nx89n:runner [RUNNER 2024–09–24 10:15:40Z ERR JobDispatcher] System.UnauthorizedAccessException: Access to the path ‘/home/runner/_work/_tool’ is denied.
I had already saw the Error: Access to the path/home/runner/_work/_tool is denied documentation when I was looking for a solution for the error ”Access to the path ‘/home/runner/_work/_temp/_github_home/.kube/cache’ is denied ” above, and it was just what I needed.
To solve this issue, add another initContainer, and run the chown:
...
template:
spec:
initContainers:
- name: kube-init
image: ghcr.io/actions/actions-runner:latest
command: ["sudo", "chown", "-R", "1001:123", "/home/runner/_work"]
volumeMounts:
- name: work
mountPath: /home/runner/_work
containers:
- name: runner
image: 492***148.dkr.ecr.us-east-1.amazonaws.com/github-runners/kraken:0.9
command: ["/home/runner/run.sh"]
...
And now everything is working.
Let’s compare the results.
The “Build and/or deploy backend ” job took 9 minutes:
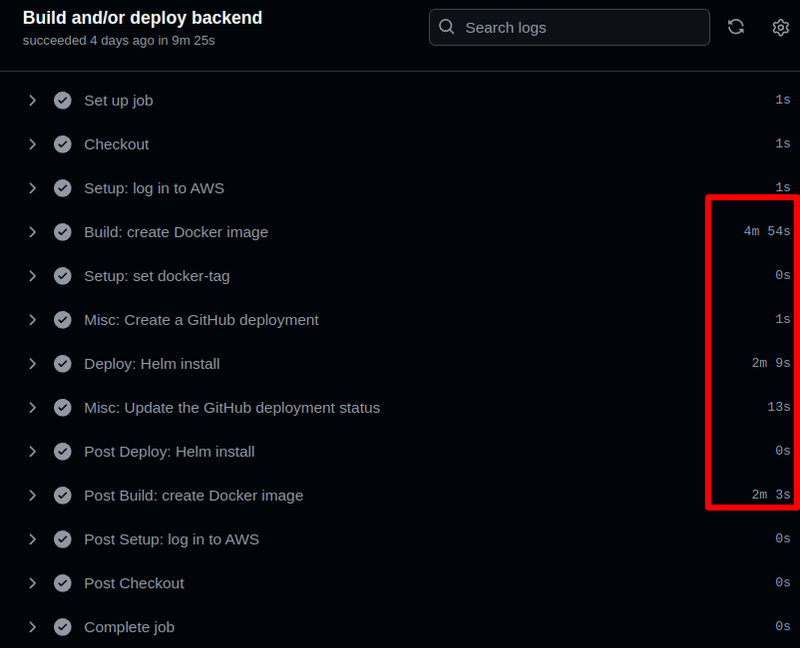
And it became 6 minutes:
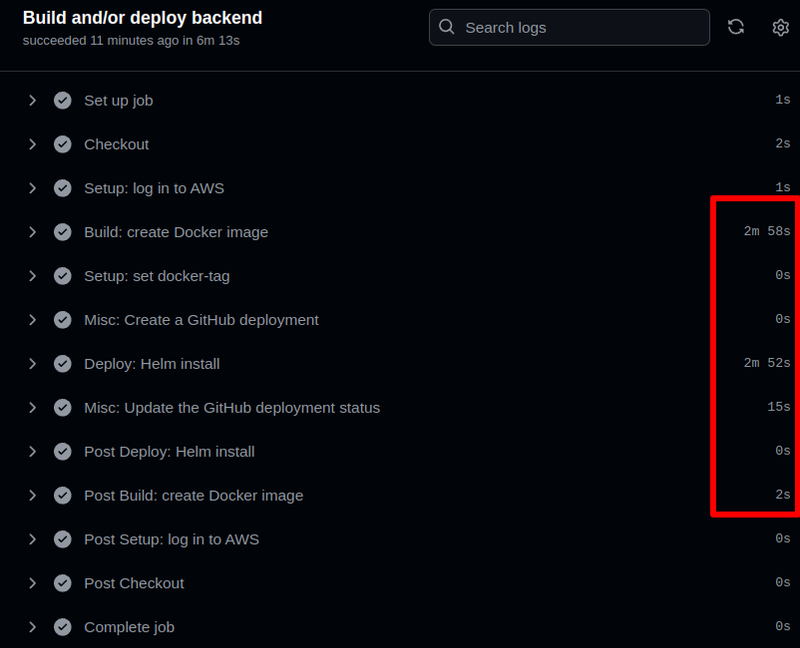
In general, that’s all for now.
I won’t say that everything works right out of the box, you’ll need to tinker with it a bit 100%, but it works.
Originally published at RTFM: Linux, DevOps, and system administration.

Top comments (1)
This post is really helpful for learning how to run GitHub Actions in Kubernetes. It makes the setup easy to understand. executive car service A good guide for anyone who wants to try it.
Some comments have been hidden by the post's author - find out more