
On all my previous projects where Kubernetes was, for its WorkerNodes scaling I’ve used the Cluster Autoscaler (CAS) because actually there were no other options before.
In general, CAS worked well, but in November 2020 AWS released its own solution for scaling nodes in EKS — the Karpenter, and if at first time reviews were mixed, its latest versions are highly praised, so I decided to try it on a new project.
Karpenter overview, and Karpenter vs Cluster Autoscaler
So what the Karpenter is? It is an auto scaler that starts new WorkerNodes when a Kubernetes cluster has Pods that it cannot start due to insufficient resources on existing WorkerNodes.
Unlike CAS, Karpenter can automatically select the most appropriate instance type depending on the needs of the Pods to be launched.
In addition, it can manage Pods on Nodes to optimize their placement across servers in order to de-scaling WorkerNodes that can be stopped to optimize the cost of the cluster.
Another nice feature is that, unlike CAS, you don’t need to create several WorkerNodes groups with different types of instances — Karpenter can itself determine a type of a Node needed for Pod/s, and create a new Node — no more hassle of choosing “Managed or Self- managed node groups” — you just describe a configuration of what types of instances can be used, and Karpenter itself will create a Node that is needed for each new Pod.
In fact, you completely eliminate the need to interact with AWS for EC2 management — this is all handled by the single component, Karpenter.
Also, Karpenter can handle Terminating and Stopping Events on EC2, and move Pods from Nodes that will be stopped — see native interrupt handling.
Karpenter Best Practices
The complete list is on the Karpenter Best Practices page, and I recommend you look at it. There are also EKS Best Practices Guides — also interesting to read.
Here are the main useful tips:
- The Karpenter control Pod(s) should be run either on the Fargate or on a usual Node from an Autoscale NodeGroup (most likely, I will create one such an ASG for all critical services with a label like “critical-addons” for the Karpenter,
aws-load-balancer-controller,coredns,ebs-csi-controller,external-dns, etc.) - configure Interruption Handling — then Karpeneter will migrate existing Pods from a Node that will be removed or terminated by Amazon
- if the Kubernetes API is not available externally (and it should be not), then configure the AWS STS VPC endpoint for a VPC of an EKS cluster
- create different provisioners for different teams that use different types of instances (e.g. for Bottlerocket and Amazon Linux)
- configure consolidation for your provisioners — then Karpeneter will try to move running Pods to existing Nodes, or to a smaller Node that will be cheaper than the existing one
- use Time To Live for Nodes created by Karpenter to remove Nodes that are not in use, see How Carpenter nodes are deprovisioned
- add the
karpenter.sh/do-not-evictannotation for Pods that you don't want to stop - then Karpenter won't touch a Node on which such Pods are running even after that Node's TTL expires - use Limit Ranges to set a default
resourceslimits for Pods
Everything looks quite interesting — let’s try to run it.
Karpenter installation
We will use the Karpenter’s Helm chart.
Later, we will do it normally with automation, but for now, to see it closer let’s do it manually.
AWS IAM
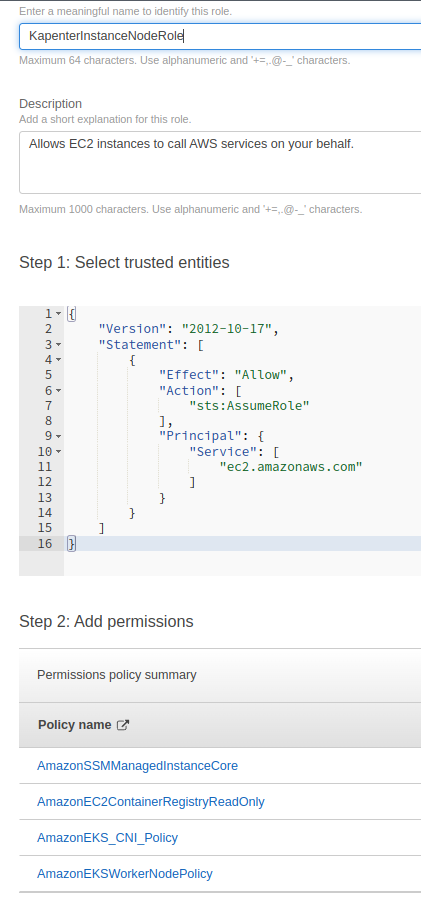
KarpenterInstanceNodeRole Role
Go to IAM Roles, and create a new role for WorkerNodes management:
Add Amazon-managed policies:
- AmazonEKSWorkerNodePolicy
- AmazonEKS_CNI_Policy
- AmazonEC2ContainerRegistryReadOnly
- AmazonSSMManagedInstanceCore
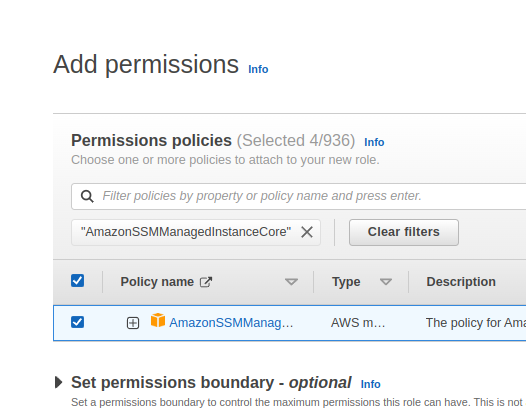
Save as KarpenterInstanceNodeRole :
KarpenterControllerRole Role
Add another, for Karpenter himself, here we describe the policy ourselves in JSON.
Go to IAM > Policies, and create your own policy:
{
"Statement": [
{
"Action": [
"ssm:GetParameter",
"iam:PassRole",
"ec2:DescribeImages",
"ec2:RunInstances",
"ec2:DescribeSubnets",
"ec2:DescribeSecurityGroups",
"ec2:DescribeLaunchTemplates",
"ec2:DescribeInstances",
"ec2:DescribeInstanceTypes",
"ec2:DescribeInstanceTypeOfferings",
"ec2:DescribeAvailabilityZones",
"ec2:DeleteLaunchTemplate",
"ec2:CreateTags",
"ec2:CreateLaunchTemplate",
"ec2:CreateFleet",
"ec2:DescribeSpotPriceHistory",
"pricing:GetProducts"
],
"Effect": "Allow",
"Resource": "*",
"Sid": "Karpenter"
},
{
"Action": "ec2:TerminateInstances",
"Condition": {
"StringLike": {
"ec2:ResourceTag/Name": "*karpenter*"
}
},
"Effect": "Allow",
"Resource": "*",
"Sid": "ConditionalEC2Termination"
}
],
"Version": "2012-10-17"
}
Save as KarpenterControllerPolicy :
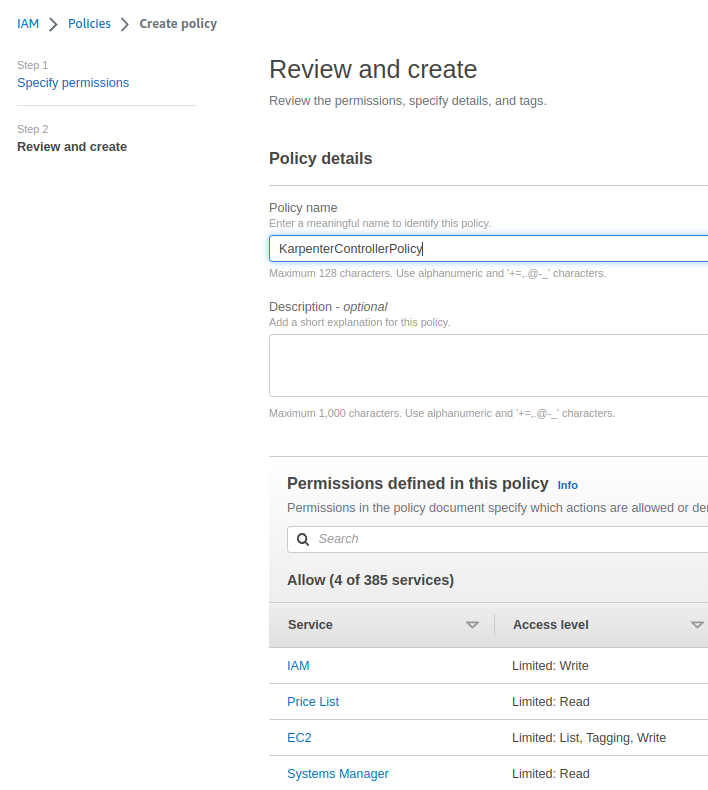
Create a second IAM Role with this policy.
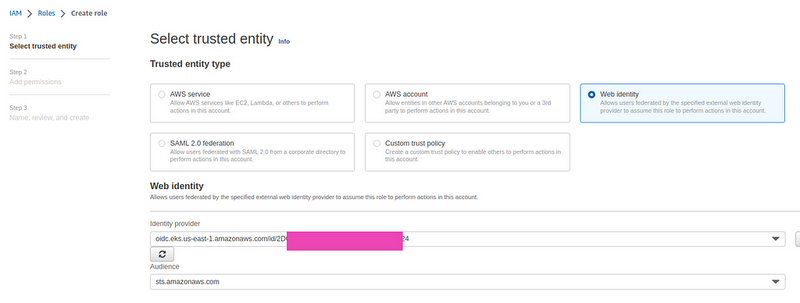
You should already have an IAM OIDC identity provider, if not, then go to the documentation Creating an IAM OIDC provider for your cluster.
At the beginning of creating a Role, select the Web Identity in the Select trusted entity, and choose an OpenID Connect provider URL of your cluster in Identity provider. In the Audience field choose the sts.amazonaws.com service:
Next, attach the policy that was made before:
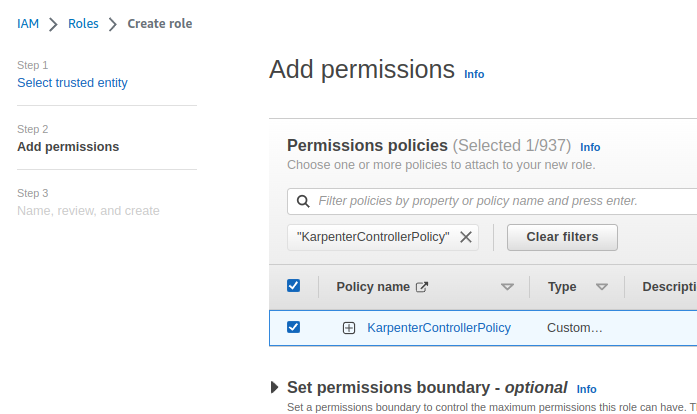
Save as KarpenterControllerRole.
The Trusted Policy should look like this:
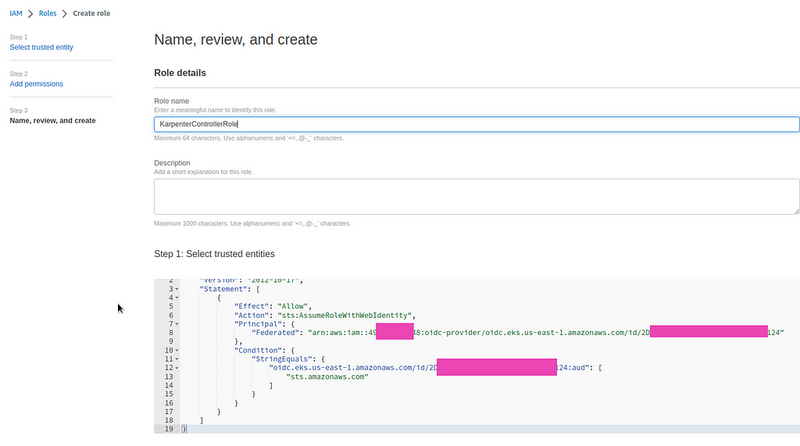
An IAM Service Account with the KarpenterControllerRole role will be created by the chart itself.
Security Groups and Subnets tags for Karpenter
Next, you need to add a Key=karpenter.sh/discovery,Value=${CLUSTER\_NAME} tag to SecurityGroups and Subnets that are used by the existing WorkerNodes, to configure where Karpenter will then create new ones.
In the How do I install Karpenter in my Amazon EKS cluster? there is an example of how to do it with two commands in the terminal, but for the first time, I prefer to do it manually.
Find the SecurityGroups and Subnets of our WorkerNode AutoScaling Group — we have only one for now, so it will be simple:

Add tags:
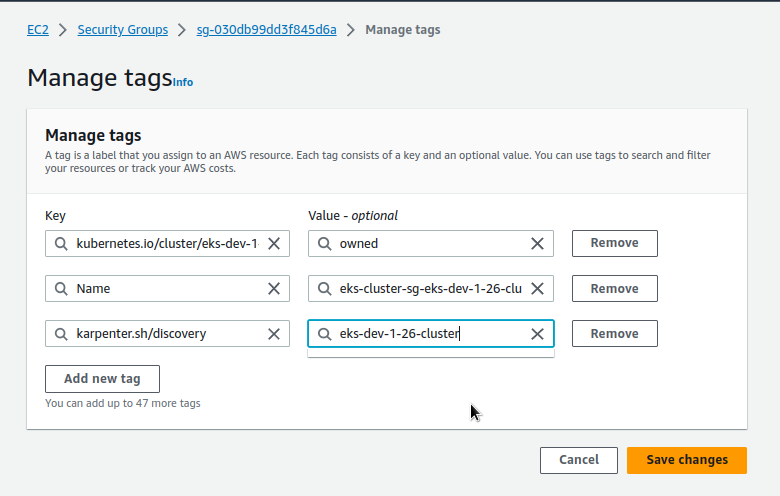
Repeat for Subnets.
aws-auth ConfigMap
Add a new role to the aws-auth ConfgiMap for future WorkerNodes to join the cluster.
See Enabling IAM principal access to your cluster.
Let’s back up the ConfigMap:
$ kubectl -n kube-system get configmap aws-auth -o yaml > aws-auth-bkp.yaml
Edit it:
$ kubectl -n kube-system edit configmap aws-auth
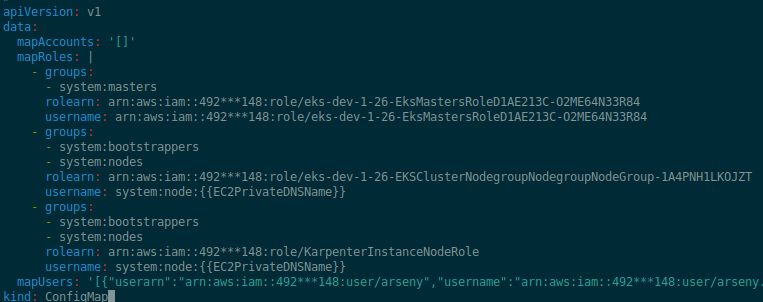
Add a new mapping to the mapRoles block - our IAM role for WorkerNodes to RBACgroups system:bootstrappersand system:nodes. In the rolearn we set the KarpenterInstanceNodeRole IAM role, which was made for future WorkerNodes:
...
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::492***148:role/KarpenterInstanceNodeRole
username: system:node:{{EC2PrivateDNSName}}
...
For some reason, my aws-auth ConfigMap was made in one line instead of the common Yaml, maybe because it was created by the AWS CDK, because as far as I remember, with eksctl it was created normally:
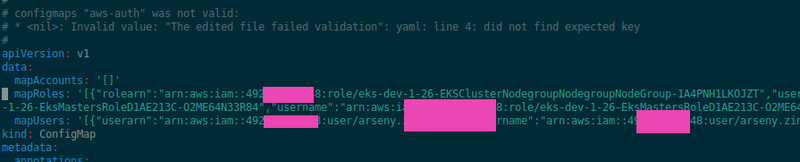
Let’s rewrite a bit, and add a new mapping.
Be careful here, because you can break the cluster. Do not do such things in Production — it all should be done with a Terraform/CDK/Pulumi/etc automation code:
Check that access has not been broken — let’s look at the Nodes:
$ kk get node
NAME STATUS ROLES AGE VERSION
ip-10–0–2–173.ec2.internal Ready <none> 28d v1.26.4-eks-0a21954
ip-10–0–2–220.ec2.internal Ready <none> 38d v1.26.4-eks-0a21954
…
Works? OK.
Installing the Karpenter Helm chart
In the How do I install Karpenter in my Amazon EKS cluster? mentioned above they suggest using the helm template to build values. A weird solution, as for me, but anyway it's working.
We will simply create our own values.yaml - this will be useful for future automation, and we will set the nodeAffinity and other parameters for the chart.
The default values of the chart itself are here>>>.
Check the labels of our WorkerNode:
$ kk get node ip-10–0–2–173.ec2.internal -o json | jq -r '.metadata.labels."eks.amazonaws.com/nodegroup"'
EKSClusterNodegroupNodegrou-zUKXsgSLIy6y
In our values.yaml file add an affinity - do not change the first part, but in the second set the key=eks.amazonaws.com/nodegroup with the name of the Node Group, the EKSClusterNodegroupNodegrou-zUKXsgSLIy6y:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/provisioner-name
operator: DoesNotExist
- matchExpressions:
- key: eks.amazonaws.com/nodegroup
operator: In
values:
- EKSClusterNodegroupNodegrou-zUKXsgSLIy6y
In the serviceAccount add an annotation with the ARN of our KarpenterControllerRole IAM role :
...
serviceAccount:
create: true
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::492***148:role/KarpenterControllerRole
Add a settings block. Actually, everything is clear from the names of the parameter.
The only thing to note is that in the defaultInstanceProfile field do not specify the full ARN of the role, but only its name:
...
settings:
aws:
clusterName: eks-dev-1-26-cluster
clusterEndpoint: [https://2DC\*\*\*124.gr7.us-east-1.eks.amazonaws.com](https://2DC***124.gr7.us-east-1.eks.amazonaws.com)
defaultInstanceProfile: KarpenterInstanceNodeRole
Now we are ready to deploy.
Find the current version of Karpenter on the releases page.
Since we are deploying for the test, you can take the latest one for today — v0.30.0-rc.0.
Let’s deploy from the Helm OCI registry:
$ helm upgrade --install --namespace dev-karpenter-system-ns --create-namespace -f values.yaml karpenter oci://public.ecr.aws/karpenter/karpenter --version v0.30.0-rc.0 --wait
Check Pods:
$ kk -n dev-karpenter-system-ns get pod
NAME READY STATUS RESTARTS AGE
karpenter-78f4869696-cnlbh 1/1 Running 0 44s
karpenter-78f4869696-vrmrg 1/1 Running 0 44s
Okay, all good here.
Creating a Default Provisioner
Now we can begin to configure autoscaling.
For this, we first need to add a Provisioner, see Create Provisioner.
In the Provisioner resource, we describe what types of EC2 instances to use, in the providerRef set a value of the resource name AWSNodeTemplate, in the consolidation - enable moving Pods between Nodes to optimize the use of WorkerNodes.
All parameters are in Provisioners — it is very useful to look at them.
Ready-made examples are available in the repository — examples/provisioner.
The resource AWSNodeTemplate describes exactly where to create new nodes - according to the tag karpenter.sh/discovery=eks-dev-1-26-cluster that we set earlier on SecurityGroups and Subnets.
All parameters for the AWSNodeTemplate can be found on the Node Templates page.
So, what do we need:
- use only T3 small, medium, or large instances
- place new Nodes only in AvailabilityZone us-east-1a or us-east-1b
Create a manifest:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
requirements:
- key: karpenter.k8s.aws/instance-family
operator: In
values: [t3]
- key: karpenter.k8s.aws/instance-size
operator: In
values: [small, medium, large]
- key: topology.kubernetes.io/zone
operator: In
values: [us-east-1a, us-east-1b]
providerRef:
name: default
consolidation:
enabled: true
ttlSecondsUntilExpired: 2592000
ttlSecondsAfterEmpty: 30
---
apiVersion: karpenter.k8s.aws/v1alpha1
kind: AWSNodeTemplate
metadata:
name: default
spec:
subnetSelector:
karpenter.sh/discovery: eks-dev-1-26-cluster
securityGroupSelector:
karpenter.sh/discovery: eks-dev-1-26-cluster
Create resources:
$ kk -n dev-karpenter-system-ns apply -f provisioner.yaml
provisioner.karpenter.sh/default created
awsnodetemplate.karpenter.k8s.aws/default created
Testing autoscaling with Karpenter
To check that everything is working, you can scale the existing NodeGroup by removing some of the EC2 instances from it.
In my Kubernetes cluster, we have our monitoring running — let’s break it down a bit ;-)
Change the AutoScale Group parameters:
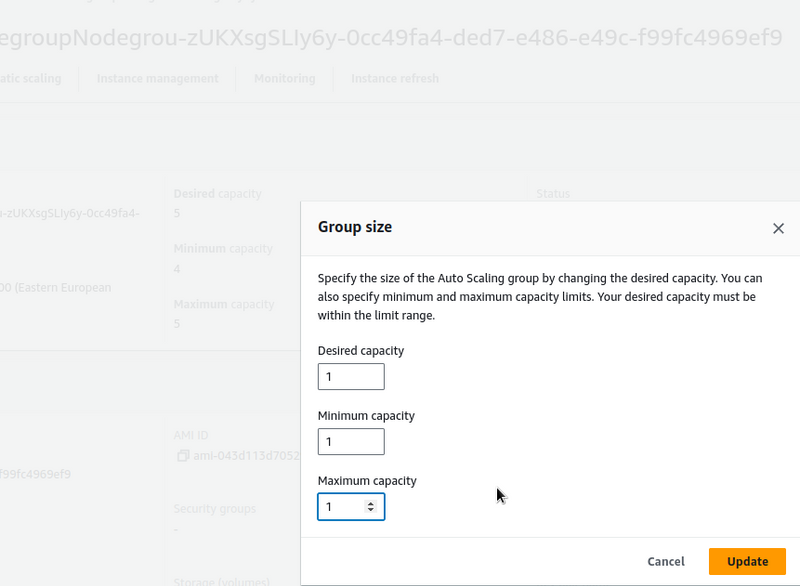
Or create a Deployment with the big requests and the number of replicas:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
replicas: 50
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: nginx
resources:
requests:
memory: "2048Mi"
cpu: "1000m"
limits:
memory: "2048Mi"
cpu: "1000m"
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: my-app
Watch the Karpenter logs — a new instance has been created:
2023–08–18T10:42:11.488Z INFO controller.provisioner computed 4 unready node(s) will fit 21 pod(s) {“commit”: “f013f7b”}
2023–08–18T10:42:11.497Z INFO controller.provisioner created machine {“commit”: “f013f7b”, “provisioner”: “default”, “machine”: “default-p7mnx”, “requests”: {“cpu”:”275m”,”memory”:”360Mi”,”pods”:”9"}, “instance-types”: “t3.large, t3.medium, t3.small”}
2023–08–18T10:42:12.335Z DEBUG controller.machine.lifecycle created launch template {“commit”: “f013f7b”, “machine”: “default-p7mnx”, “provisioner”: “default”, “launch-template-name”: “karpenter.k8s.aws/15949964056112399691”, “id”: “lt-0288ed1deab8c37a7”}
2023–08–18T10:42:12.368Z DEBUG controller.machine.lifecycle discovered launch template {“commit”: “f013f7b”, “machine”: “default-p7mnx”, “provisioner”: “default”, “launch-template-name”: “karpenter.k8s.aws/10536660432211978551”}
2023–08–18T10:42:12.402Z DEBUG controller.machine.lifecycle discovered launch template {“commit”: “f013f7b”, “machine”: “default-p7mnx”, “provisioner”: “default”, “launch-template-name”: “karpenter.k8s.aws/15491520123601971661”}
2023–08–18T10:42:14.524Z INFO controller.machine.lifecycle launched machine {“commit”: “f013f7b”, “machine”: “default-p7mnx”, “provisioner”: “default”, “provider-id”: “aws:///us-east-1b/i-060bca40394a24a62”, “instance-type”: “t3.small”, “zone”: “us-east-1b”, “capacity-type”: “on-demand”, “allocatable”: {“cpu”:”1930m”,”ephemeral-storage”:”17Gi”,”memory”:”1418Mi”,”pods”:”11"}}
And in a minute check the Nodes in the cluster:
$ kk get node
NAME STATUS ROLES AGE VERSION
ip-10–0–2–183.ec2.internal Ready <none> 6m34s v1.26.6-eks-a5565ad
ip-10–0–2–194.ec2.internal Ready <none> 19m v1.26.4-eks-0a21954
ip-10–0–2–212.ec2.internal Ready <none> 6m38s v1.26.6-eks-a5565ad
ip-10–0–3–210.ec2.internal Ready <none> 6m38s v1.26.6-eks-a5565ad
ip-10–0–3–84.ec2.internal Ready <none> 6m36s v1.26.6-eks-a5565ad
ip-10–0–3–95.ec2.internal Ready <none> 6m35s v1.26.6-eks-a5565ad
Or in the AWS Console by the karpenter.sh/managed-by tag:
Done.
What is left to be done:
- for the default Node Group, which is created with a cluster from the AWS CDK, add the
critical-addons=truetag andtainswithNoExecuteandNoSchedulerules - this will be a dedicated group for all controllers (see Kubernetes: Pods and WorkerNodes – control the placement of the Pods on the Nodes) - add tag
Key=karpenter.sh/discovery,Value=${CLUSTER\_NAME}in the cluster's automation for WorkerNodes, SecurityGroups, and Private Subnets - in the chart values for AWS ALB Controller deployment, ExternalDNS, and Karpenter itself, add tolerations with the
critical-addons=truetag, andNoExecutewithNoSchedule
That’s all for now.
All Pods are up, everything is working.
And a couple of useful commands to check Pod/Nod status.
Output the number of Pods on each Node:
$ kubectl get pods -A -o jsonpath='{range .items[?(@.spec.nodeName)]}{.spec.nodeName}{"\n"}{end}' | sort | uniq -c | sort -rn
Display Pods on a Node:
$ kubectl get pods --all-namespaces -o wide --field-selector spec.nodeName=ip-10–0–2–212.ec2.internal
Also, you can add plugins for kubectl to check used resources on Nodes - see Kubernetes: Krew plugin manager and useful plugins for kubectl.
Oh, and will be good to play around with the Vertical Pod Autoscaler — how Karpenter will deal with it.
Useful links
- Getting Started with Karpenter
- Karpenter Best Practices
- Control Pod Density
- Deprovisioning Controller
- How do I install Karpenter in my Amazon EKS cluster?
Originally published at RTFM: Linux, DevOps, and system administration.

Top comments (1)
Karpenter is a tool that helps your EKS clusters scale automatically based on your needs. This post explains how to install it using Helm. It’s a great way to save time and resources while managing your workloads in the cloud!