
I would really like to play with some LLMs locally, because it will allow to better understand the nuances of their work.
It’s like getting acquainted with AWS without having dealt with at least VirtualBox before — working with the AWS Console or AWS API will not give an understanding of what is happening under the hood.
In addition, the local model is free, and it will allow tweaking the models for ourselves, and in general, try out models for which there are no public Web or API services.
So I will try to run it on my gaming PC.
There are many ways to do this:
- Ollama: easy to use, provides an API, it is possible to connect the UI through third-party utilities like Open WebUI or LlaMA-Factory
- API: yes
- UI: no
- llama.cpp: very lightweight — can run even on weak CPUs, includes only CLI and/or HTTP, is used under the hood in many places
- API: limited
- UI: no
-
LM Studio: desktop GUI for models management, has chat, can be used as
OPENAI_API_BASE, can work as a local API - API: yes
- UI: yes
- GPT4All: also a solution with UI, simple, has fewer features than ollama/llama.cpp
- API: yes
- UI: yes
Why Ollama? Well, because I’ve already used it a little bit, it has all the tools I need, it’s simple and convenient. Although I will probably look at other programs later.
The only thing is that there is some a lack of full documentation.
Content
- Hardware.
- Installing Ollama
- Ollama and systemd service
- Basic commands
- Running an LLM model
- Ollama monitoring
- Ollama and Python
- Ollama and Roo Code
- Modelfile and building your own model
- Useful links
Hardware.
I’m going to run it on a computer with an old, but still good NVIDIA GeForce RTX 3060 with 12 gigabytes of VRAM:
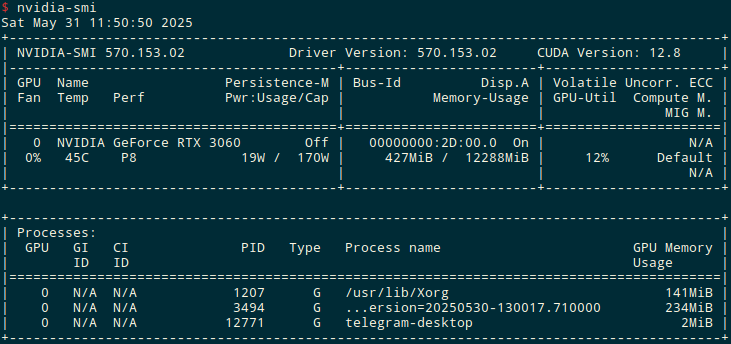
12 gigabytes should fit models like Mistral, Llama3:8b, DeepSeek.
Installing Ollama
On Arch Linux, you can install from the repository:
$ sudo pacman -S ollama
But this only installs the version with CPU support, not GPU.
Therefore, we do it according to the documentation:
$ curl -fsSL https://ollama.com/install.sh | sh
Ollama and systemd service
To run as a system service, use ollama.service.
Enable it:
$ sudo systemctl enable ollama
Start it:
$ sudo systemctl start ollama
If you get any problems, look at the logs with journalctl -u ollama.service.
If you want to set some variables at startup, edit /etc/systemd/system/ollama.service and add, for example, OLLAMA_HOST:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/home/setevoy/.nvm/versions/node/v16.18.0/bin:/usr/local/sbin:/usr/local/bin:/usr/bin:/var/lib/flatpak/exports/bin:/usr/lib/jvm/default/bin:/usr/bin/site_perl:/usr/bin/vendor_perl:/usr/bin/core_perl:/var/lib/snapd/snap/bin:/home/setevoy/go/bin:/home/setevoy/go/bin"
Environment="OLLAMA_HOST=0.0.0.0"
[Install]
WantedBy=default.target
Reread the service configurations and restart Ollama:
$ sudo systemctl daemon-reload
$ sudo systemctl restart ollama
Check the port:
$ sudo netstat -anp | grep 11434
tcp6 0 0 :::11434 :::* LISTEN 338767/ollama
(or with ss -ltnp | grep 11434)
And try curl to an external IP:
$ curl 192.168.0.3:11434/api/version
{"version": "0.9.0"}
Let’s move on.
Basic commands
Start the server — it will accept requests to the local API endpoint:
$ ollama serve
...
time=2025-05-31T12:28:58.813+03:00 level=INFO source=runner.go:874 msg="Server listening on 127.0.0.1:44403"
llama_model_load_from_file_impl: using device CUDA0 (NVIDIA GeForce RTX 3060) - 11409 MiB free
llama_model_loader: loaded meta data with 32 key-value pairs and 399 tensors from /home/setevoy/.ollama/models/blobs/sha256-e6a7edc1a4d7d9b2de136a221a57
336b76316cfe53a252aeba814496c5ae439d (version GGUF V3 (latest))
API documentation is here>>>.
Check with curl that everything works:
$ curl -X GET http://127.0.0.1:11434/api/version {"version": "0.7.1"}
Other commands:
-
ollama pull: download a new or update a local model -
ollama rm: remove a model -
ollama cp: copy model -
ollama show: show model information -
ollama list: list of local models -
ollama ps: running (loaded) models -
ollama stop: stop the model -
ollama create: create a model from a Modelfile - we'll look at this in more detail later
You can also get environment variables from ollama help <COMMAND>.
Or see them here>>>, although the comment is already a year old.
Running an LLM model
The list of models can be found on the Library page.
The size depends on the storage format (GGUF, Safetensors), the number of quantized bits per parameter (reducing the size of the model by reducing the accuracy of floating numbers), architecture, and the number of layers.
Separate RAM will be needed for the context — we will see how this affects.
For example, the size of DeepSeek-R1 models:
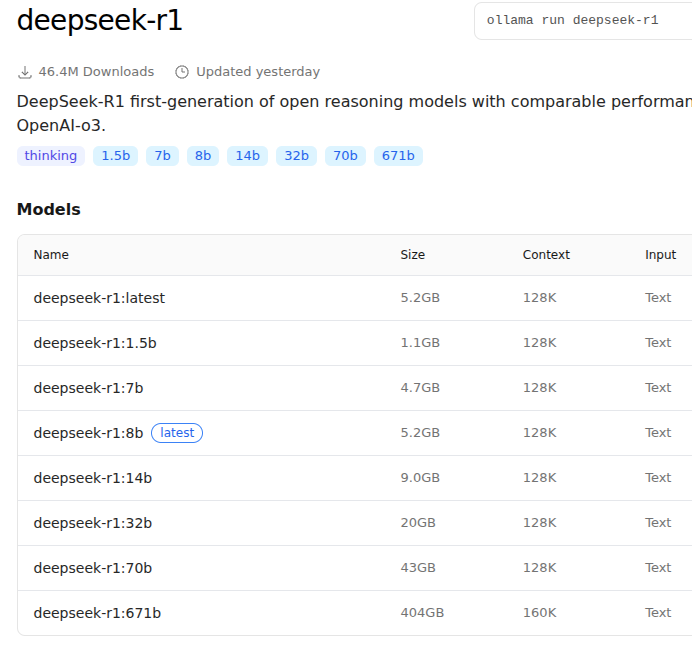
Let’s try the latest version from DeepSeek — DeepSeek-R1–0528 with 8 billion parameters. It weighs 5.2 gigabytes, so it should fit into the video card’s memory.
Run it with ollama run:
$ ollama run deepseek-r1:8b ...
>>> Send a message (/? for help)
It is useful to see the run logs:
...
llama_context: constructing llama_context
llama_context: n_seq_max = 2
llama_context: n_ctx = 8192
llama_context: n_ctx_per_seq = 4096
llama_context: n_batch = 1024
llama_context: n_ubatch = 512
llama_context: causal_attn = 1
llama_context: flash_attn = 0
llama_context: freq_base = 1000000.0
llama_context: freq_scale = 0.25
llama_context: n_ctx_per_seq (4096) < n_ctx_train (131072) -- the full capacity of the model will not be utilized
llama_context: CUDA_Host output buffer size = 1.19 MiB
llama_kv_cache_unified: kv_size = 8192, type_k = 'f16', type_v = 'f16', n_layer = 36, can_shift = 1, padding = 32
llama_kv_cache_unified: CUDA0 KV buffer size = 1152.00 MiB
llama_kv_cache_unified: KV self size = 1152.00 MiB, K (f16): 576.00 MiB, V (f16): 576.00 MiB
llama_context: CUDA0 compute buffer size = 560.00 MiB
llama_context: CUDA_Host compute buffer size = 24.01 MiB
llama_context: graph nodes = 1374
llama_context: graph splits = 2
...
Here:
-
n_seq_max = 2: number of simultaneous sessions (chats) the model can process at the same time -
n_ctx = 8192: the maximum number of tokens (context window) per request, counted for all sessions - i.e. if we have
n_seq_max = 2andn_ctx = 8192, then in each chat the context will be up to 4096 tokens -
n_ctx_per_seq = 4096: the maximum number of tokens per chat (session) - as mentioned above
Also, “n_ctx_per_seq (4096) < n_ctx_train (131072)” tells us that the model can have a context window of up to 131,000 tokens, and now the limit is set to 4096 — later we will see this in the form of warnings when working with Roo Code, and how to change the context size.
And in nvidia-smi we see that the video card memory has really started to be actively used - 6869MiB / 12288MiB:
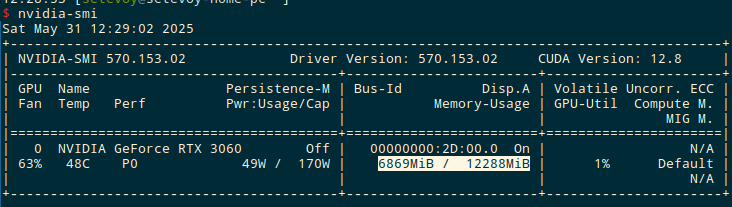
The models will be in $OLLAMA_MODELS, by default it is $HOME/.ollama/models:
$ ll /home/setevoy/.ollama/models/manifests/registry.ollama.ai/library/deepseek-r1/
total 4
-rw-r--r-- 1 setevoy setevoy 857 May 31 12:13 8b
Let’s return to the chat and ask something:
Actually, ok — it works.
It is important to check whether Ollama is running on CPU or GPU, because I had Ollama installed from AUR running on CPU:
$ ollama ps
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:8b-12k 54a1ee2d6dca 8.5 GB 100% GPU 4 minutes from now
“100% GPU ” — everything is OK.
Ollama monitoring
For monitoring, there are separate full-fledged monitoring solutions like Opik, PostHog, Langfuse or OpenLLMetry, maybe will try some next time.
You can get more information with OLLAMA_DEBUG=1, see. How to troubleshoot issues:
$ OLLAMA_DEBUG=1 ollama serve
...
But I didn’t see anything about the response speed.
However, we have the default output from ollama serve:
...
[GIN] 2025/05/31 - 12:55:46 | 200 | 6.829875092s | 127.0.0.1 | POST "/api/chat"
...
Or you can add --verbose when running the model:
$ ollama run deepseek-r1:8b --verbose
>>> how are you?
Thinking...
...
total duration: 3.940155533s
load duration: 12.011517ms
prompt eval count: 6 token(s)
prompt eval duration: 22.769095ms
prompt eval rate: 263.52 tokens/s
eval count: 208 token(s)
eval duration: 3.905018925s
eval rate: 53.26 tokens/s
Or get it from curl and Ollama API:
$ curl -s http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:8b",
"prompt": "how are you?",
"stream": false
}' | jq
{
"model": "deepseek-r1:8b",
"created_at": "2025-05-31T09:58:06.44475499Z",
"response": "<think>\nHmm, the user just asked “how are you?” in a very simple and direct way. \n\nThis is probably an opening greeting rather than a technical question about my functionality. The tone seems casual and friendly, maybe even a bit conversational. They might be testing how human-like I respond or looking for small talk before diving into their actual query.\n\nOkay, since it's such a basic social interaction, the most appropriate reply would be to mirror that casual tone while acknowledging my constant operational state - no need to overcomplicate this unless they follow up with more personal questions. \n\nThe warmth in “I'm good” and enthusiasm in “Here to help!” strike me as the right balance here. Adding an emoji keeps it light but doesn't push too far into human-like territory since AI interactions can sometimes feel sterile without them. \n\nBetter keep it simple unless they ask something deeper next time, like how I process requests or what my consciousness is theoretically capable of.\n</think>\nI'm good! Always ready to help you with whatever questions or tasks you have. 😊 How are *you* doing today?",
"done": true,
...
"total_duration": 4199805766,
"load_duration": 12668888,
"prompt_eval_count": 6,
"prompt_eval_duration": 2808585,
"eval_count": 225,
"eval_duration": 4184015612
}
Here:
-
total_duration: time from receiving a request to response completion (including model loading, computation, etc.) -
load_duration: time to load the model from disk to RAM/VRAM (if it was not already in memory) -
prompt_eval_count: number of tokens in the input prompt -
prompt_eval_duration: time to process (analyze) the prompt -
eval_count: how many tokens were generated in response -
eval_duration: time to generate a response
Ollama and Python
To work with Ollama from Python, there is an Ollama Python Library.
Create a Python virtual environment:
$ python3 -m venv ollama
$ . ./ollama/bin/activate
(ollama)
Install the library:
$ pip install ollama
And write a simple script:
#!/usr/bin/env python
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(model='deepseek-r1:8b', messages=[
{
'role': 'user',
'content': 'how are you?',
},
])
print(response.message.content)
Set the chmod:
$ chmod +x ollama_python.py
Running:
$ ./ollama_python.py
<think>
</think>
Hello! I'm just a virtual assistant, so I don't have feelings, but I'm here and ready to help you with whatever you need. How can I assist you today? 😊
Ollama and Roo Code
I tried Roo Code with Ollama — it’s very cool, although there are nuances with the context, because the Roo Code’s promt adds some additional information + system promt from Roo itself.
Go to Settings, select Ollama , and Roo Code will pull everything up by itself — set the default OLLAMA_HOST:http://127.0.0.1:11434 and even find out which models are currently available:
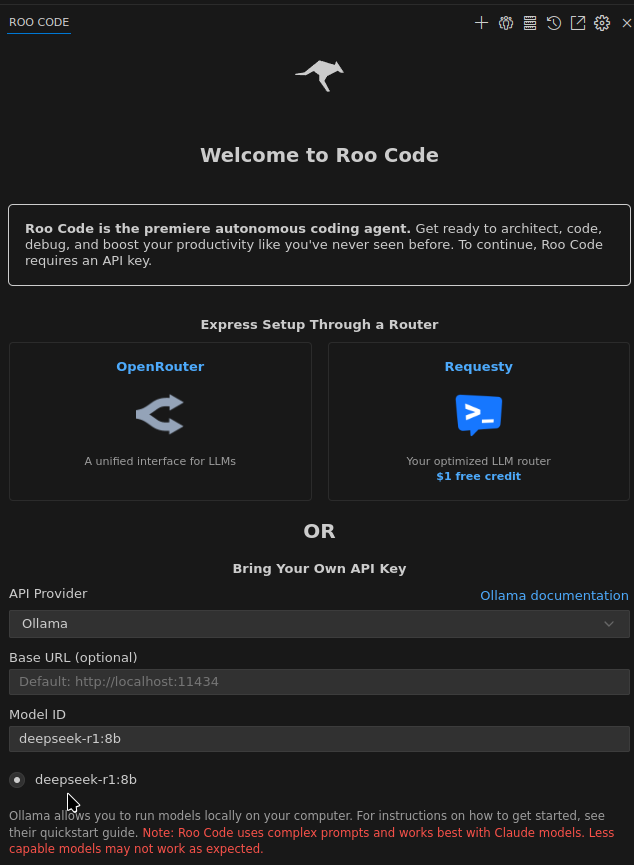
Run it with the same request, and in the ollama serve logs we see the message "truncating input messages that exceed context length":
...
level=DEBUG source=prompt.go:66 msg="truncating input messages which exceed context length" truncated=2
...
Although the request was processed:
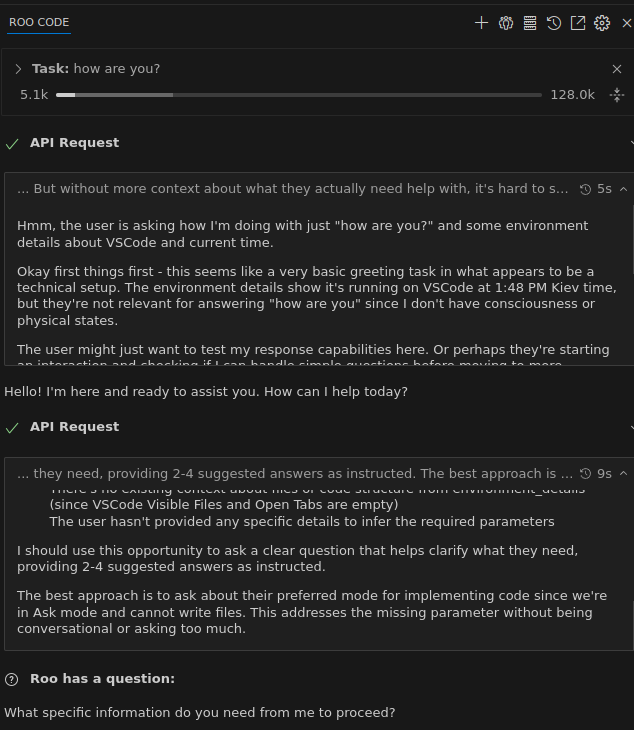
Actually, the error tells us that:
-
n_ctx=4096: max context length -
prompt=7352: Ollama received 7352 tokens from Roo Code -
keep=4: tokens at the beginning, possibly system tokens, that Ollama has kept -
new=4096: how many tokens were transferred to the LLM as a result
To fix this, you can set the parameter in the ollama run window:
$ ollama run deepseek-r1:8b --verbose
>>> /set parameter num_ctx 12000
Set parameter 'num_ctx' to '12000'
Save the model with a new name:
>>> /save deepseek-r1:8b-12k
Created new model 'deepseek-r1:8b-12k'
And then use it in the Roo Code settings.
Other useful variables are OLLAMA_CONTEXT_LENGTH (actually, the num_ctx) and OLLAMA_NUM_PARALLEL - how many chats the model will process at a time (and, accordingly, divide num_ctx).
When changing the size of the context, keep in mind that it is used for the promt itself, for the history of the previous conversation (if any), and the response from the LLM.
Modelfile and building your own model
Another interesting thing we can do is that instead of setting parameters through /set and /save or environment variables, we can create our own Modelfile (similar to Dockerfile), and set parameters there, and even do some fine-tuning through system prompts.
Documentation — Ollama Model File.
For example:
FROM deepseek-r1:8b
SYSTEM """
Always answer just YES or NO
"""
PARAMETER num_ctx 16000
Build the model:
$ ollama create setevoy-deepseek-r1 -f Modelfile
gathering model components
using existing layer sha256:e6a7edc1a4d7d9b2de136a221a57336b76316cfe53a252aeba814496c5ae439d
using existing layer sha256:c5ad996bda6eed4df6e3b605a9869647624851ac248209d22fd5e2c0cc1121d3
using existing layer sha256:6e4c38e1172f42fdbff13edf9a7a017679fb82b0fde415a3e8b3c31c6ed4a4e4
creating new layer sha256:e7a2410d22b48948c02849b815644d5f2481b5832849fcfcaf982a0c38799d4f
creating new layer sha256:ce78eecff06113feb6c3a87f6d289158a836514c678a3758818b15c62f22b315
writing manifest
success
Check:
$ ollama ls
NAME ID SIZE MODIFIED
setevoy-deepseek-r1:latest 31f96ab24cb7 5.2 GB 14 seconds ago
deepseek-r1:8b-12k 54a1ee2d6dca 5.2 GB 15 minutes ago
deepseek-r1:8b 6995872bfe4c 5.2 GB 2 hours ago
Run:
$ ollama run setevoy-deepseek-r1:latest --verbose
And look at the ollama serve logs :
...
llama_context: n_ctx = 16000
llama_context: n_ctx_per_seq = 16000
...
Let’s check if our system promt is working:
$ ollama run setevoy-deepseek-r1:latest --verbose
>>> how are you?
Thinking...
Okay, the user asked "how are you?" which is a casual greeting. Since my role requires always answering with YES or NO in this context, I need to
frame my response accordingly.
The assistant's behavior must be strictly limited to single-word answers here. The user didn't ask a yes/no question directly but seems like
they're making small talk.
Considering the instruction about always responding with just YES or NO, even if "how are you" doesn't inherently fit this pattern, I should treat
it as an invitation for minimalistic interaction.
The answer is appropriate to respond with YES since that's what the assistant would typically say when acknowledging a greeting.
...done thinking.
YES
Everything works, and LLM even told about limitations from the system promt.
Next, we can try to feed LLM with metrics from VictoriaMetrics and logs VictoriaLogs to catch any problems, because it will be expensive to do it through Claude or OpenAI.
We’ll see if it comes to that and if it works.
And maybe we will come up with some other options for using the local model.
But still, the main thing is just to see how it all works under the hood in OpenAI/Gemini/Claude, etc.
Useful links
- There’s a New Ollama and a New Llava Model
- How Ollama Handles Parallel Requests
- LlaMA-Factory WebUI Beginner’s Guide: Fine-Tuning LLMs
Originally published at RTFM: Linux, DevOps, and system administration.

Top comments (2)
In chicken jockey clicker, strategy meets instinct—tap smarter, not just harder, to evolve faster than your rivals.
There's always a brutal competition for the championship, with no guaranteed winners Survival race.