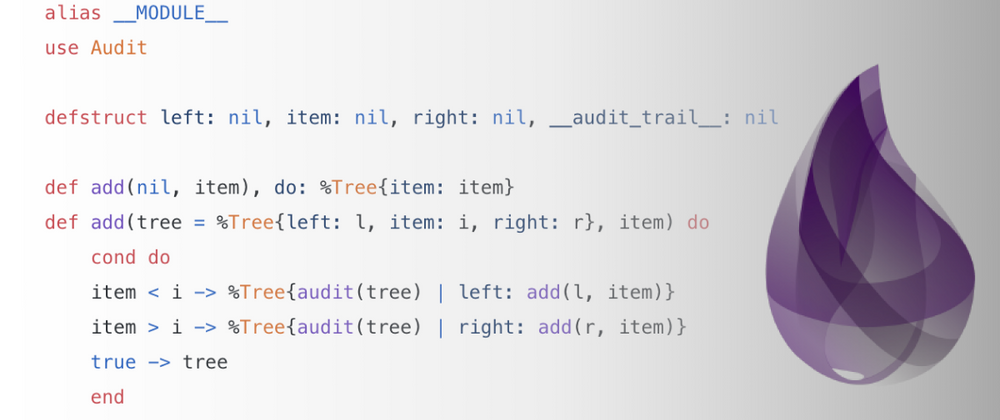
Part of my work with Lob as a Staff Engineer is to implement various USPS standards pertaining to address autocorrection (aka CASS Cycle ‘N’ and ‘O’). These standards have a lot of subtle details, so the Elixir code that implements them can be intimidating. It is difficult to get this complex code to do what you want, so I started to investigate techniques that would help me track how my changes impacted the results. Before we dive into my solution, let’s first give a quick recap on how functional data structures differ from their imperative counterparts.
A recap on Functional Data Structures
One of the counterintuitive aspects of writing functional code is the constructive nature of data structures. You cannot mutate an existing data structure — if you want to make a change, you must create new elements containing the change that you desire without altering the existing structure. Essentially you make a new version of the data structure that embodies your change that will share common parts of the previous version that stayed the same.
Let’s take the concrete example of a binary tree. The tree, T1, has six nodes: A, B, C, D, E, and F:
Destructive vs constructive binary tree insertion
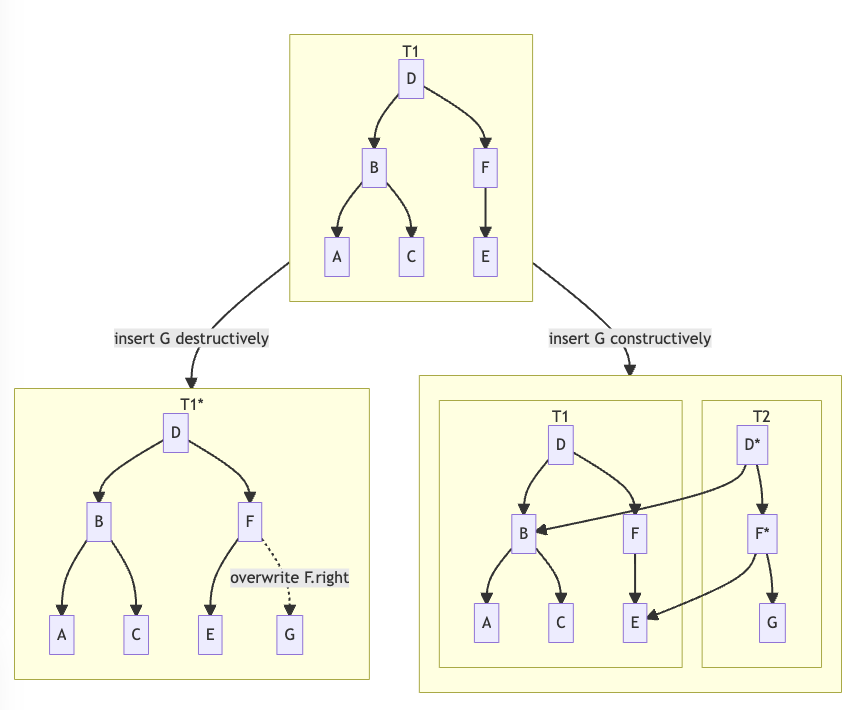
The traditional imperative way to add G to this tree would be to overwrite the right field of the parent node containing F to point to a newly created node containing G as illustrated by the left side of the diagram. But in a functional language like Elixir, we don’t have the ability to overwrite fields. Instead, we must create a new spine for the tree containing the nodes leading to the newly created G node while sharing the unchanged nodes from the original tree, T1.
At first, this seems terribly inefficient — after all the imperative counterpart just needed to perform one (destructive) update. But it’s not all bad news in the functional world; although in the tree example we create log₂(n) extra nodes, our old version and new version can happily co-exist. In fact, by merely keeping a pointer to old versions of the tree, we can trivially implement an infinite undo facility (space permitting). In the imperative world, this is a bit trickier — we would need to record the changes via a list of deltas and rerun those deltas if we wanted to access an earlier state. In the functional world, all these versions can simultaneously coexist for a small investment in space. Neat! In the imperative world? Not so much…
This also illustrates why it’s easier to reason about functional code versus imperative code — in the functional code, everything stays constant. In the imperative code, a pointer to a structure is no guarantee that structure will remain intact. This is also the reason that imperative concurrent programming is fraught with difficulty whereas functional programming lends itself quite naturally to working in parallel. No need for critical sections, semaphores, monitors, etc. Those constructs are all about protecting some piece of code that side effects from being executed simultaneously in different threads/processes. No side effects — no problem!
Implementing data structures functionally is actually a fascinating area of study — I highly recommend Chris Osaki’s Ph.D. thesis on the topic: Purely Functional Data Structures.
The problem
Now that we’ve refreshed our understanding of functional techniques for implementing data structures, we can move forward with an explanation of the basic idea. The core of our program doing address correction manipulates a very large %Address{} struct. The program works in phases and in each phase a different set of fields are populated with new metadata either deduced from machine learning sub-systems, or extracted from various USPS- supplied metadata. The final Address struct will have the answer we seek (we hope) and a whole lot of additional metadata that might help us understand how it came to that conclusion. But with a data structure as large as Address with over a hundred fields, IO.inspect at some strategic locations isn’t going to cut it — the amount of information printed to the screen is just too overwhelming. We need something a little bit more precise.
Making a difference
A key component of our library is the difference engine. This takes two objects and computes a list of the differences between them which makes it easier for us to visualize the evolution of our data structures over time. First, let’s decide how to represent a difference. A delta has three possibilities:
- update, replace one item with another
- delete, remove an item
- add, add an item
With our representation settled, we need to figure out our implementation strategy. We simultaneously recurse over the two objects we wish to compare until we find a point where they diverge and we return the difference. So our main function will look like this:
This delegates to a three-argument version that takes the current path as the first argument. We flatten the result, reverse the paths (because they’re call stacks) and then order the results by length of path.
So now we tackle the major cases for delta: struct, map, list, tuple, and everything else:
Let’s tackle these one at a time. For structs, if they are the same kind of struct, convert them into a map and carry on; otherwise, they’re already different.
For maps, we want to compute the overlap of keys: a_only, only in a; b_only, only in b; and common, appears in both. With that information, it’s simply a matter of computing the difference of the values of the common keys:
For lists, I take a simplistic approach of zipping them together to compare the elements pairwise. (I think computing the Levenshtein edits would be overkill).
For tuples, if they are the same size convert them to lists and let delta_list process them, otherwise, they’re different.
This just leaves the base case and we’re done.
Ok, I suppose we should define empty?
And that wraps up our description of our difference engine.
Elixir’s macro magic
A lot of folks don’t realize that Elixir is actually quite a small language; most of the features that you know and love are implemented via the powerful macro languages. Don’t believe me? Check out all the language features implemented inside the Kernel module: @variables, def, defdelegate, defexception, defguard, defimpl, defmacro, |> etc., etc. This also explains why the syntax feels is a little clunky in places — it’s likely implemented as a macro!
The basic idea
Our basic idea is to define a macro, audit, which embeds a paper trail inside an audittrail field. It needs to be a macro because we want to capture the file and line number from where the macro was called. Basically, this field will contain a triple of: the last version of the data structure, the filename, and the line number.
Let’s get started by defining some types:
So our audit consists of a snapshot of the struct, a filename, and a line number. It’s considered good macro design practice to isolate as much of the functionality as possible in a function. So here’s our audit_fun:
So now our macro is extremely simple:
To put it to use, we want to be able to generate a changelist given a struct that has our magic audit_trail field:
Now we just need some helper functions to turn that changelist into a human-readable string:
There are two nuances in this code. Firstly, as we’ll be looking up our sources files a lot, it behooves us to cache them. So we implement a simple Agent to accomplish that:
Secondly, by their very nature source files are subject to change. So for this information to be useful at a later point in time, we should use git SHAs to specify the version of the file that we’re looking at. To accomplish this, we have a module to do all the GitHub URL wrangling:
The final result
With all these components in place, we’re finally in a position to demonstrate our library in action.
This is a somewhat trivial example. The ideal use case is for much larger struct where it becomes hard to see the wood from the trees when you IO.inspect results. The use of the difference engine shines in these scenarios.
For extremely large %Address structs in our Address Verification code, this library has saved my bacon on several occasions. I hope you find it equally useful.
Conclusion
We’ve described a simple library to track changes to data structures. If you’d like to kick the tires and try it out, you can find it in hex.pm under audit.

Top comments (1)
Biblioteca Audit din Elixir este un instrument valoros pentru urmărirea modificărilor în cod, permițând dezvoltatorilor să monitorizeze acțiunile și actualizările datelor într-un mod transparent. Aceasta oferă o evidență clară a modificărilor efectuate, contribuind la o mai bună securitate și trasabilitate în aplicații complexe. În forum lucrare licență, folosirea unei astfel de biblioteci poate fi analizată ca exemplu de implementare practică a controlului versiunilor și a gestionării datelor, evidențiind importanța integrității codului și a responsabilității în dezvoltarea software modern.