This article was originally posted on Everything DevOps.
When you deploy Kubernetes, you get a cluster. And the cluster you get upon deployment would consist of one or more worker machines (virtual or physical) called nodes for you to run your containerized applications in pods.
For each worker node to run containerized applications, it must contain a container runtime for running the containers, a kubelet to ensure everything runs, and the kube-proxy for handling networking.
In this article, you will learn more about what each of the above components does to enable the running of containerized applications in a Kubernetes cluster.
Prerequisites
To properly understand this article, you should have an understanding of the Kubernetes control plane.
Container runtime
The container runtime in a worker node is responsible for running containers. The container runtime is also responsible for pulling container images from a repository, monitoring local system resources, isolating system resources for the use of a container, and managing the container lifecycle.
In Kubernetes, there is support for container runtimes such as:
- containerd: An industry-standard container runtime with an emphasis on simplicity, robustness, and portability.
- CRI-O: A lightweight container runtime specifically built for Kubernetes.
- And any other implementation of the Kubernetes Container Runtime Interface (CRI) — a plugin enabling the kubelet to use other container runtimes without recompiling.
You may wonder why you didn’t see Docker (a major container runtime) in the list above. Docker isn’t there because of the removal of dockershim — the component that allows use of Docker as a container runtime — in Kubernetes release v1.24.
But not to worry, you can still use Docker as a container runtime in Kubernetes using the cri-dockerd adapter. cri-dockerd provides a shim for Docker Engine that lets you control Docker via the Kubernetes CRI. ****
kubelet
The kubelet is the primary Kubernetes node agent. The kubelet is responsible for running the containers for the pods scheduled to its node. The kubelet runs on every machine (control plane, too) in the cluster.
The kubelet for each node keeps a watch on pod resources in the control plane’s kube-apiserver. Whenever the kube-scheduler assigns a pod to a node, the kubelet for that node reads the PodSpec (a YAML or JSON object that describes a pod) and instructs the container runtime using the CRI to spin up containers to satisfy that spec. The container runtime will then pull the container images if they aren’t present in the node and start them.
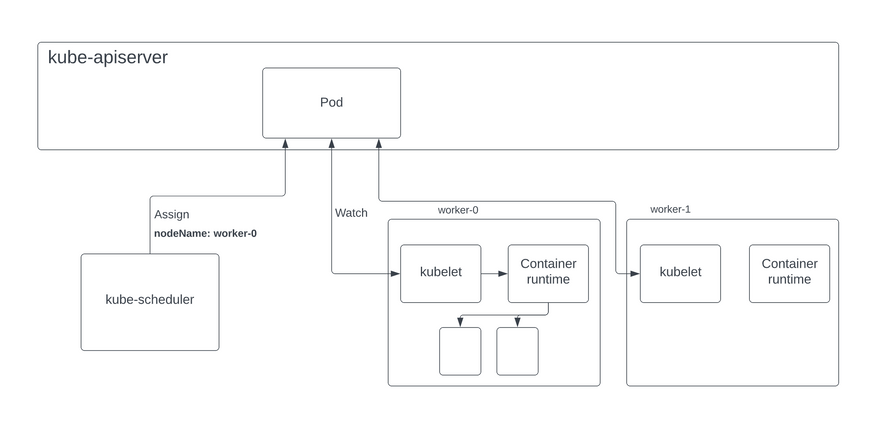
It is important to note that the kubelet is a Kubernetes component that does not run in a container. The kubelet, along with the container runtime, are installed and run directly on the machine that forms the node in the cluster, and that’s why they are responsible for managing the containerized workloads.
kube-proxy
Like the kubelet, kube-proxy runs on every node in the cluster, but unlike the kubelet, kube-proxy typically runs in a Kubernetes pod as a part of a Kubernetes DaemonSet.
kube-proxy implements essential functionalities for Kubernetes services. kube-proxy maintains network rules that allow communication to your Pods from network sessions inside or outside your cluster.
To dig deep into kube-proxy’s role, you must understand how Service resources work in Kubernetes.
Service in Kubernetes
A Service provides a stable IP address for connecting to pods. There are Service resources in Kubernetes because without them:
- When a client application needs to connect to server pods in a cluster, it would need to retrieve and maintain a list of each pod’s IP address, which will burden the client.
- And also, it will be hard to maintain those connections, seeing that in Kubernetes, pods will come and go due to scaling, update or hardware failure.
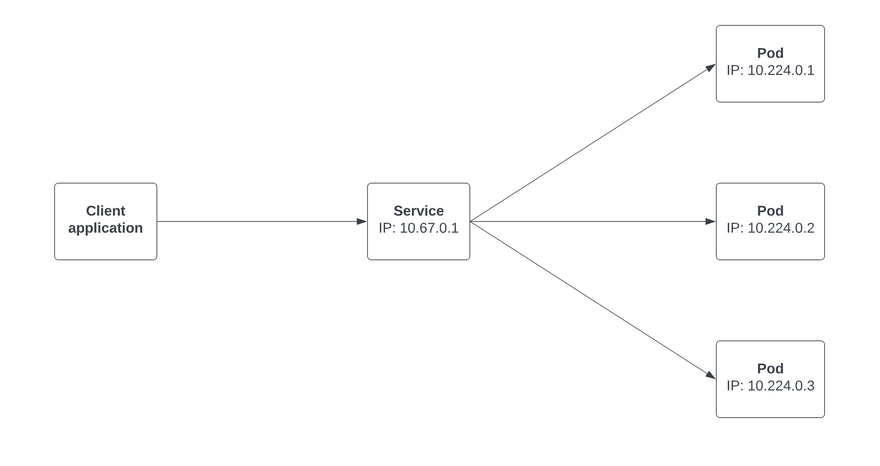
With the above setup using a Service resource, the client will just need the address of the Service, and the rest is taken care of for you automatically.
And how that’s taken care of automatically is that when you create a Service with a selector that references a label applied to a set of pods, the Endpoints controller in the kube-controller-manager will create an Endpoints resource with the pods IP addresses. In the Endpoints resource, the addresses are maintained and if they change, they will be updated automatically and the client’s requests routed accordingly.
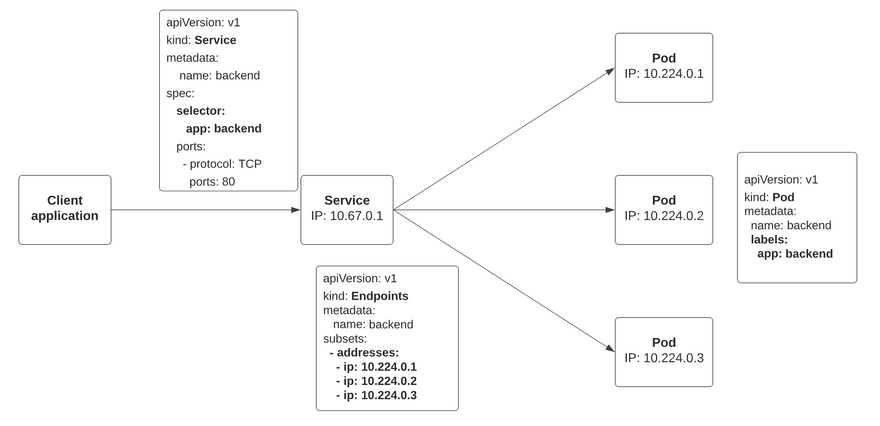
In the above image, you might get the impression that a Service is a literal proxy that load balances requests to backends like Nginx. But that’s almost not the case in modern Kubernetes clusters.
Now with your understanding of Service resources, let’s dig into how kube-proxy implements essential functionalities for Kubernetes services.
How kube-proxy implements functionalities for Kubernetes Service resources.
There is an Endpoints controller in the kube-controller-manager that manages the endpoint resources. The Endpoints controller also manages the associations between services and pods.
With the kube-proxy running on each node in the cluster, it watches Service and Endpoint resources. So when a change that needs updating occurs, the kube-proxy will update the rules in iptables. iptables is a network packet filtering utility that allows rules to be set in the network stack of the Linux kernel.
Now, when a client pod sends a request to a Service’s IP, the Linux kernel routes the request to one of the pod’s IP according to the rule kube-proxy sets.
Note: kube-proxy supports alternatives to using iptables to manage network packet routing. But iptables is the most common and suitable for the majority of installations.
Also, note that with iptables, the pod selection will be random. It would not be round robin or other common load balancing strategies. For load balancing, you will need to use IPVS (IP Virtual Server), an alternative to iptables that implements a layer for load balancing in the Linux kernel.
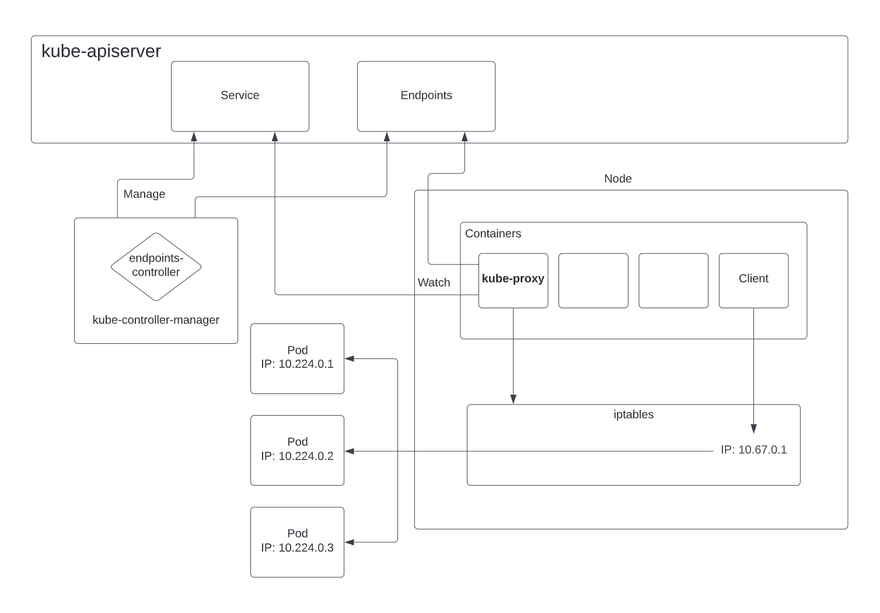
Also, It is important to point out that a Service’s IP is a “virtual IP”, so if you try to ping that IP, you won’t get a response the way you usually would if you ping a pod’s IP, which is an actual endpoint on the network.
A Service’s IP is essentially a key in the rules set by iptables that gives network packet routing instructions to the host’s kernel. But the important part is that a client pod can use the Service IP like it usually would and get the expected behavior as if it were calling an actual pod IP.
Conclusion
This article explained the roles of the container runtime, kubelet, and kube-proxy components in a Kubernetes worker node. There is so much more to learn about these three node components.
To learn more, check out the following resources:

Oldest comments (0)