
In the past couple of years, we hear the term "Chaos Engineering" in the context of cloud.
Mature organizations have already begun to embrace the concepts of chaos engineering, and perhaps the most famous use of chaos engineering began at Netflix when they developed Chaos Monkey.
To quote Werner Vogels, Amazon CTO: "Everything fails, all the time".
What is chaos engineering and what are the benefits of using chaos engineering for increasing the resiliency and reliability of workloads in the public cloud?
What is Chaos Engineering?
"Chaos Engineering is the discipline of experimenting on a system to build confidence in the system’s capability to withstand turbulent conditions in production." (Source: https://principlesofchaos.org)
Production workloads on large scale, are built from multiple services, creating distributed systems.
When we design large-scale workloads, we think about things such as:
- Creating high-available systems
- Creating disaster recovery plans
- Decreasing single point of failure
- Having the ability to scale up and down quickly according to the load on our application
One thing we usually do not stop to think about is the connectivity between various components of our application and what will happen in case of failure in one of the components of our application.
What will happen if, for example, a web server tries to access a backend database, and it will not be able to do so, due to network latency on the way to the backend database?
How will this affect our application and our customers?
What if we could test such scenarios on a live production environment, regularly?
Do we trust our application or workloads infrastructure so much, that we are willing to randomly take down parts of our infrastructure, just so we will know the effect on our application?
How will this affect the reliability of our application, and how will it allow us to build better applications?
History of Chaos Engineering
In 2010 Netflix developed a tool called "Chaos Monkey", whose goal was to randomly take down compute services (such as virtual machines or containers), part of the Netflix production environment, and test the impact on the overall Netflix service experience.
In 2011 Netflix released a toolset called "The Simian Army", which added more capabilities to the Chaos Monkey, from reliability, security, and resiliency (i.e., Chaos Kong which simulates an entire AWS region going down).
In 2012, Chaos Monkey became an open-source project (under Apache 2.0 license).
In 2016, a company called Gremlin released the first "Failure-as-a-Service" platform.
In 2017, the LitmusChaos project was announced, which provides chaos jobs in Kubernetes.
In 2019, Alibaba Cloud announced ChaosBlade, an open-source Chaos Engineering tool.
In 2020, Chaos Mesh 1.0 was announced as generally available, an open-source cloud-native chaos engineering platform.
In 2021, AWS announced the general availability of AWS Fault Injection Simulator, a fully managed service to run controlled experiments.
In 2021, Azure announced the public preview of Azure Chaos Studio.
What exactly is Chaos Engineering?
Chaos Engineering is about experimentation based on real-world hypotheses.
Think about Chaos Engineering, as one of the tests you run as part of a CI/CD pipeline, but instead of a unit test or user acceptance test, you inject controlled faults into the system to measure its resiliency.
Chaos Engineering can be used for both modern cloud-native applications (built on top of Kubernetes) and for the legacy monolith, to achieve the same result – answering the question – will my system or application survive a failure?
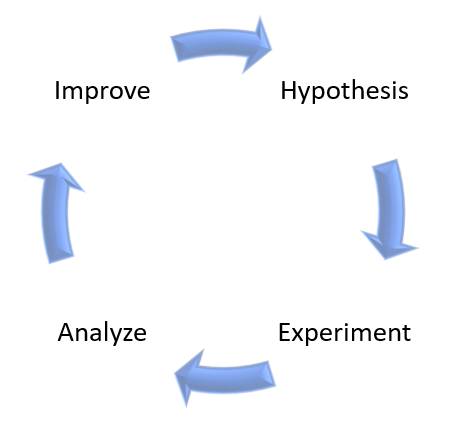
On high-level, Chaos Engineering is made of the following steps:
- Create a hypothesis
- Run an experiment
- Analyze the results
- Improve system resiliency
As an example, here is AWS’s point of view regarding the shared responsibility model, in the context of resiliency:
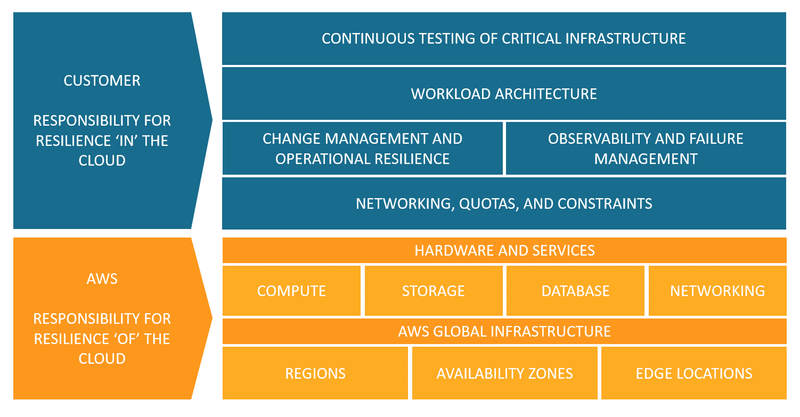
Source: https://aws.amazon.com/blogs/architecture/chaos-engineering-in-the-cloud
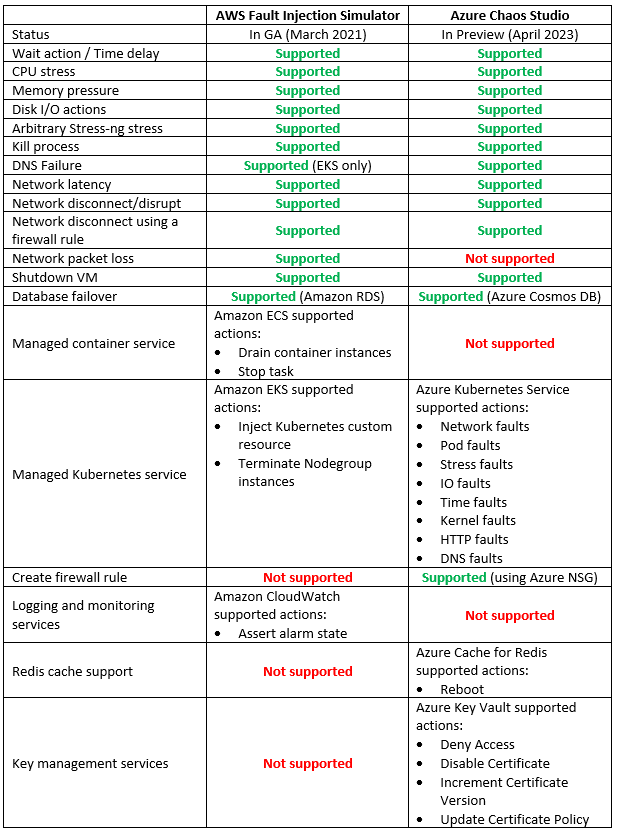
Chaos Engineering managed platform comparison
In the table below we can see a comparison between AWS and Azure-managed services for running Chaos Engineering experiments:
Additional References:
Summary
In this post, I have explained the concept of Chaos Engineering and compared alternatives to cloud-managed services.
Using Chaos Engineering as part of a regular development process will allow you to increase the resiliency of your applications, by studying the effect of failures and designing recovery processes.
Chaos Engineering can also be used as part of a disaster recovery and business continuity process, by testing the resiliency of your systems.
Additional References
- Chaos engineering (Wikipedia)
- Principles of Chaos Engineering
- Chaos Engineering in the Cloud
- What Chaos Engineering Is (and is not)
- AWS re:Invent 2022 - The evolution of chaos engineering at Netflix (NFX303)
- What is AWS Fault Injection Simulator?
- What is Azure Chaos Studio?
- Public Chaos Engineering Stories / Implementations
About the Author
Eyal Estrin is a cloud and information security architect, the owner of the blog Security & Cloud 24/7 and the author of the book Cloud Security Handbook, with more than 20 years in the IT industry.
Eyal is an AWS Community Builder since 2020.
You can connect with him on Twitter and LinkedIn.

Top comments (1)
Chaos Engineering is all about putting systems to the test by deliberately causing failures to see how they handle it. This way, you can spot issues before they turn into real problems. The main aim is to keep systems strong and dependable, even when things don’t go as planned.