
It's best practice to use multiple accounts to follow the least privilige principle. Each account should have different security & compliance controls and access patterns. Development accounts have security and compliance controls, they are typically less restrictive that a production account. Production accounts should never be accessed from a user or just with Read-Only access - each resource of these accounts should be created automatically using codepipelines. Whereas specific global management accounts like a security or central-logging account are limited to users which are part of a security or compliance team. The following post will show you how to create and manage accounts using best practices.
1. Automate account creation
Automate the process of setting up Accounts that are secure, well-architected, and ready to use. If you use the Control Tower for your Landing Zone it's coming already with an Account Factory - there's also already existent solutions to customize the Account Factory to your needs. Even if you use the official landing zone solution there are some examples of Account vending machines on github.
Followed you can see an example architecture of an Account Factory with examples on what kind of customization you can/should do.
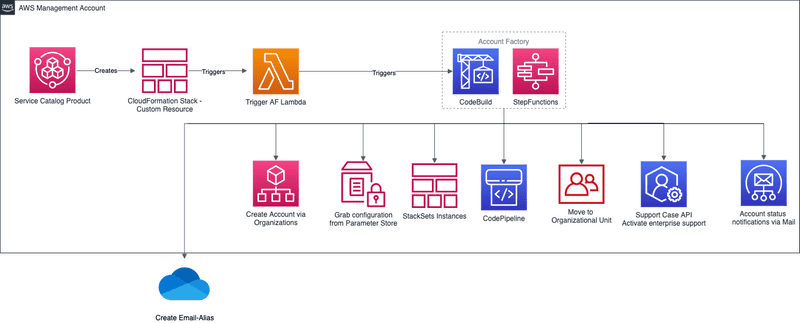
2. Track and inspect your costs
Following FinOps principles is a must these days and will persist for a long time. So be aware and track/inspect your costs to be able to save some in the end.
If you want to learn more about FinOps take a look at this post.
2.1 Budget notification
Define and use budgets. Set up notifications using Slack, Teams or Email to warn you if you're about to exceed your allocated amount for cost or usage budgets. Additionally you should use cost allocation tags. When you tag your AWS resources, it’s much easier to organize, categorize and track your AWS costs. Cost allocation tags are useful for tracking expenditure on exploratory workloads in your accounts.
2.2 Inspect cost and usage
To inspect your cost and usage you should create dashboards or use the Cost Explorer to display your past usage & cost and forecast expected spend.
Here is an example workshop on how to create cost intelligence dashoards. You should always check your usage spending for cost optimization as well - Cost Explorer or OHTRU will help you to save some cost.
3. Implement SCPs
Prevent unwanted actions, save costs and apply appropriate SCPs to your accounts. When you design and implement SCPs be sure to put those accounts in specific organizational units. If you want to learn more about SCPs take a look at this blog post: SCP best practices.
4. Use an auditing tool
It is best practice to use CloudTrail as an auditing tool to continuously monitor API calls in your AWS environment. Those CloudTrail logs should be forwarded to your central SIEM - if you don't use a central SIEM you can use EventBridge to create rules that trigger on the information captured by CloudTrail eg.: if someone use the S3 API - PutBucketPublicAccessBlock. Those rule can trigger a Lambda to do automated remediation or send a notification to Slack, Teams or an Email.
5. Check your resources for compliance
Use automated and continuous checks against rules in a set of security standards to identify non-compliant resources in your account. You can use Config & Config Rules or Security Hub for that.
5.1 Config
Config is a continous management and monitoring service for your whole infrastructure. It captures snapshots of your configuration of resources and is able to check using Config Rules to detect for non-compliant resources.
As a prerequisite we need to ensure that Config is activated in your AWS Region.
Config Aggregators with advanced queries will help you to gain visibility about the compliance status of your whole organization.
Config has already some manged rules which are easy to activate. Here is an example for a managed config rule activation using CloudFormation.
# Author: David Krohn
AWSTemplateFormatVersion: 2010-09-09
#-----------------------------------------------------------------------------
#Resources
#-----------------------------------------------------------------------------
Resources:
CheckForS3BucketServerSideEncryption:
Type: AWS::Config::ConfigRule
Properties:
ConfigRuleName: AWS-s3-bucket-server-side-encryption-enabled
Description: Checks that your Amazon S3 bucket either has S3 default encryption enabled or that the S3 bucket policy explicitly denies put-object requests without server side encryption.
Source:
Owner: AWS
SourceIdentifier: S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED
5.2 Security Hub
Security Hub continuously monitors your environment using automated security checks based on the best practices and industry standards that you want to follow. Security Hub provides controls for the following standards:
- CIS AWS Foundations
- Payment Card Industry Data Security Standard (PCI DSS)
- AWS Foundational Security Best Practices
When you enable a standard, all of the controls for that standard are enabled by default. To adjust a standard to your needs (own compliancy requirements) you can then disable and enable specific controls within an enabled standard.
To disable a control, you can use this API call:
aws securityhub update-standards-control --standards-control-arn <CONTROL_ARN> --control-status "DISABLED" --disabled-reason <DESCRIPTION>
To enable a control, use the following API call:
aws securityhub update-standards-control--standards-control-arn <CONTROL_ARN> --control-status "ENABLED"
6. Access control
Create individual identities to access AWS. As we all know we should create credentials for all users and resources on the one hand but also avoid creating long-term credentials in AWS on the other hand. In the following subsections I have two ideas how to tackle the problems to use AWS best practices for access control.
6.1 Federated access for users
Use federated access to avoid long-term credentials to access the Management Console, call APIs, and access resources, without the need to create an IAM user for each identity. You can use Active Directory, any other identity provider with SAML2.0 and configure an IDP in each account, or you can use the AWS SSO service.
6.2 Do not use access keys
Long-term access keys, such as those associated with IAM users remain valid until you manually revoke them. In many scenarios you dont need to create access keys that never expire. You can create IAM roles and generate temporary security credentials using Security Token Service (STS) instead. IAM roles can be associated and comsumed by almost every resources such as EC2 Instances, Fargate, Lambdas or a mobile app etc. Even if you need to do a cross-account access, you can use an IAM role to establish trust between accounts. However when there is no way around to create access keys, you should think of creating a lambda which is taking care of keys being automatically rotated. In any case, try to avoid that credentials are not accidentally exposed to the whole world.
6.3 Secure root user credentials
Do not use the root user for daily work. In times of a global pandemic like right now - you may think about using a vault to mange the access to the root user credentials and MFA. Additionally you should use root activity monitor to get notified if someone is using the root user for activity. If you want to learn when you need to use the root user take a look at this blog post: Tasks that require root user
8. Resource lifecycle management
Defining a lifecycle for your resources will help you to control costs, keep your resources up to date and saves it from being undocumented and unsupportable.
8.1 Development accounts
In development accounts you should consider to define lifecycle policies for all resoures eg. delete S3 buckets or delete old instances. If you use CloudFormation to deploy all resources you could think of using automatic deletion of your stacks after a defined time. If you want to learn more about that - take a look at this post: Scheduling automatic deletion of AWS CloudFormation stacks. As we all know that in development accounts you sometimes just do some testing using manuall deployment via Console or CLI. You should take a look at aws-nuke. aws-nuke is a tool that delete AWS resources automatically. In addition the tool is supporting filters which helps you to preserve some baseline resources. One idea would be to implement aws-nuke on a codebuild task which is triggered via Cloudwatch event. 💡 The Codebuild could also be deployed in a central mangement account and just assumes a role in the target account.
9. Data lifecycle management
Defining a lifecycle for your data will help you lower the operational costs without losing and reduce the complexity of managing your backup operations.
9.1 Development accounts
Since development accounts should not contain any production data its very easy to define a lifecycle for all data in development accounts. I would suggest to decide a specific timerange after all data will be deleted regularly.
9.2 Production accounts
The decision for production accounts is a little more difficult than for development accounts, but it is also feasible. Here you only have to decide how long you need, which data to restore the application in the event of an error and which log files are needed for how long. Whether it is data on S3, instance snapshots or log files on CloudWatch, all services support mechanisms that either delete the data or move it to cheaper storage after a certain period of time. In the case of log files, I would prefer to keep the data in their place for a longer time than too short. Especially if there are holidays in between and you want to analyze an error and the data is then no longer there, that's bad 😉. Below you can find some posts regarding backup handling:
- Automate AWS Backups with AWS Service Catalog
- Automating Amazon EBS snapshots management using Data Lifecycle Manager
- Building data lakes and implementing data retention policies with Amazon RDS snapshot export to Amazon S3
10. Tagging
Tagging of resources is one of the most important things when it comes to accounts - it helps you to identity who created resources, who is responsible for them, how costs should be allocated and even with lifecycle policies. Therefore you should tag every resource to simplify administration. If you want to learn more about Tagging read the following whtepaper: Tagging Best Practices.
11. Network connectivity
If you ask me: the topic of network connectivity could be completely eliminated nowadays, as the first motto should be API first and applications should only talk to each other via secure APIs, but there are still applications today that do not have corresponding APIs whicb have large amounts of data to be transferred or certain regulations ensure that communication has to take place via dedicated connections. So how to handle them? In organizations where you need dedicated connections or every other VPN connectivity to on-prem, I would choose the Transit Gateway. Transit Gateway connects VPCs and on-premise networks through a central hub. You can create datadomains to restrict and control your complete dataflow of your organization on one hand and on the other hand you expand globally with inter-region peering. Plus your data is automatically encrypted and never travels over the public internet.

Top comments (0)