As AI systems become increasingly complex, efficient data management is crucial for success. Pinecone vector databases have emerged as a game-changer in this space, offering unparalleled speed and scalability. But where do they fit in the grand scheme of AI architecture?
In this post, we'll explore the role of Pinecone vector databases in modern AI systems, examining how they address data management challenges and enable faster, more accurate AI workflows.
Challenges of AI Data Management
The sheer amount and complexity of data that AI systems require has grown to be a significant bottleneck as they continue to develop. Relational databases and file systems are examples of traditional data storage technologies that are not designed to meet the specific needs of AI data. I think the main cause of these systems' shortcomings is their incapacity to effectively store and query massive volumes of unstructured data.
The requirement to balance data velocity, diversity, and volume is, in my opinion, the main difficulty in AI data management. To train AI models, enormous volumes of data must be ingested, processed, and stored in a manner that allows for quick access and querying. However, conventional data storage methods are frequently too inflexible, too sluggish, or too
Furthermore, AI data is often high-dimensional, sparse, and noisy, making it difficult to store and query using traditional methods. I think that this has led to a proliferation of ad-hoc data management solutions, which can be brittle, inefficient, and difficult to scale. As a result, AI practitioners are forced to spend an inordinate amount of time and resources on data management, rather than focusing on the development of AI models themselves. It's clear that a new approach to AI data management is needed, one that can efficiently handle the unique demands of AI data and enable faster, more accurate AI workflows.
Role of Pinecone Vector Databases
A possible answer to the problems associated with AI data management is the emergence of pinecone vector databases. Pinecone helps AI professionals store, analyze, and manage massive volumes of high-dimensional data effectively by utilizing the power of vector similarity search. This is especially crucial for AI applications like recommender systems, computer vision, and natural language processing that depend on dense vector representations.
Pinecone vector databases are superior to conventional data storage options in a number of important ways. In the first place, they provide speedy and effective similarity searches, which let AI models find pertinent data points and forecast outcomes with precision. Second, they provide a scalable and adaptable architecture that can accommodate enormous data sets and grow to meet the demands of extensive AI deployments.
In addition to these technical advantages, Pinecone vector databases also offer a number of practical benefits. By offloading data management tasks to a specialized database, AI practitioners can focus on developing and refining their AI models, rather than worrying about the underlying data infrastructure.
This can lead to faster development cycles, improved model accuracy, and reduced costs. Overall, Pinecone vector databases have the potential to revolutionize the field of AI data management, enabling faster, more accurate, and more scalable AI workflows.
Where Pinecone Vector Databases Fit in AI Architecture
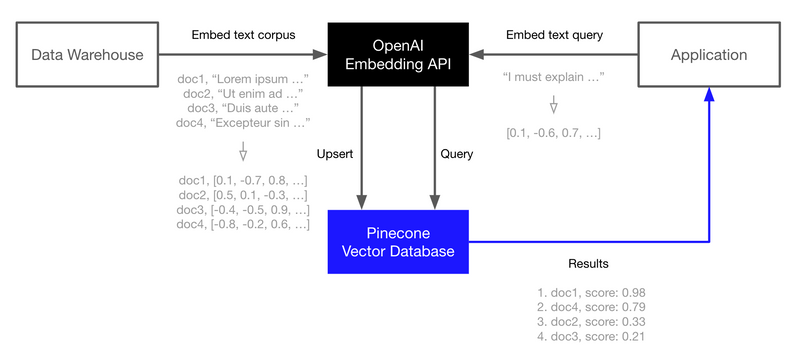
Pinecone vector databases occupy a critical position in the AI architecture, serving as a bridge between data ingestion and model training. They fit neatly between the data lake/repository and the AI model, enabling efficient and scalable management of high-dimensional data. By providing a dedicated layer for vector data management, Pinecone vector databases alleviate the burden on data lakes and repositories, which are often ill-equipped to handle the unique demands of AI data.
Within this architecture, data is first processed and converted into dense vector representations within a data lake or repository. From then on, the Pinecone vector database takes over, offering a quick and effective way to store, query, and retrieve these vectors. As a result, training and inference may be done more rapidly and accurately by AI models as they can acquire and interpret pertinent data quickly.
AI practitioners can tune each component individually with Pinecone vector databases, which decouples data management from model training, improving overall performance and efficiency. The ability to create and test new models and algorithms without compromising the underlying data infrastructure makes it easier to experiment and iterate thanks to this modular design.
Conclusion
In conclusion, Pinecone vector databases have emerged as a crucial component in AI architecture, enabling efficient and scalable management of high-dimensional data. By providing a dedicated layer for vector data management, Pinecone vector databases alleviate the burden on data lakes and repositories, facilitating faster and more accurate AI model training and inference. As the demand for AI applications continues to grow, the importance of Pinecone vector databases will only increase.
With innovative solutions like Vectorize.io, which provides a cloud-native Pinecone vector database, AI practitioners can now easily deploy and manage vector databases at scale, unlocking new possibilities for AI innovation and adoption.

Top comments (2)
the Lucky 91 app offers a variety of benefits that contribute to its widespread appeal, especially for those seeking both fun and a chance at financial rewards. One notable benefit is the app’s ease of access and low barrier to entry. Unlike many other gaming platforms that require players to have specialized knowledge or skills, the Lucky 91 app is designed for everyone, regardless of experience level. The simplicity of its game mechanics means that anyone can participate without feeling overwhelmed Lucky91 app. The app generally offers a range of beginner-friendly options, which helps new players learn and get involved without feeling lost or frustrated. As users progress, they can gradually explore more challenging game types, making it suitable for a diverse audience.
Great breakdown of where Pinecone fits into modern AI architecture—especially the focus on handling high-dimensional data efficiently. I like how you explained its role between data ingestion and model training in a practical way. Vector databases really are becoming essential for scalable AI workflows. For quick downtime between projects, you can also explore pak33apk.