Vector indexes transform how data is searched and retrieved, bringing contextual depth to AI models. You might be wondering how does this innovative indexing differs from traditional database methods in AI applications. This blog will guide you through the ins and outs of vector Databases indexing.
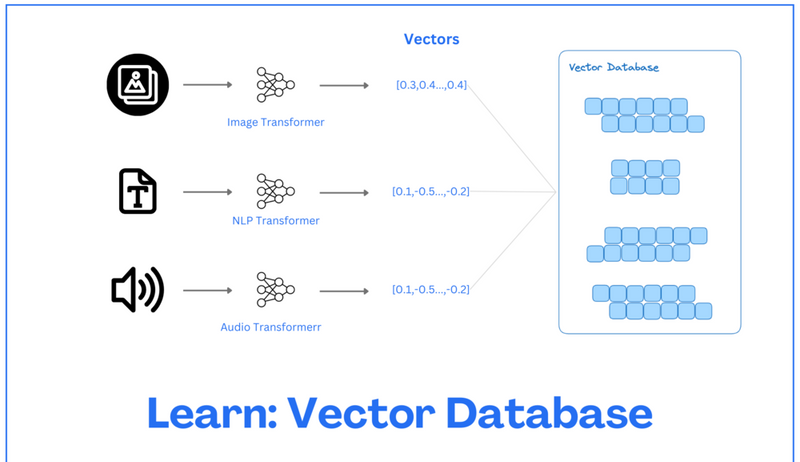
What is a Vector Database
A vector database is a type of database specifically designed to store and manage vector data efficiently. In simple terms, vector data represents information in the form of vectors, which are mathematical constructs composed of ordered sets of values.
The significance of vector databases lies in their ability to capture and represent semantic relationships within the data. By transforming data points into vectors and mathematical representations in a multi-dimensional space, vector databases empower AI models to efficiently analyze, manipulate, and generate content.
These vectors are derived from diverse datasets, including textual collections, image repositories, and user interaction logs. With an exponential growth of available data, vector databases have become indispensable, with approximately 90% of generative AI applications relying on vector databases for data storage and retrieval. Vector database works in the following way:
- Vector databases take your data, including text data, convert it into vectors using an embedding algorithm, and store it. For text data, embeddings capture the semantic meaning of words, phrases, sentences, or documents. Deep learning models like Word2Vec, FastText, or BERT usually generate these embeddings.
- When a user asks for a query, it is converted to a vector using the same embedding algorithm. The vector representation of the user’s query is then compared to the vectors to find the closest matches. This means we can query the vector database for similar vector embeddings.
What is vector indexing?
Vector indexing is more than just storing data; it is also about intelligently structuring the vector embeddings to improve retrieval performance. This technique uses complex algorithms to arrange high-dimensional vectors in a searchable and efficient manner.
This arrangement is not random; it is done in such a way that comparable vectors are clustered together, allowing vector indexing to perform quick and accurate similarity searches and pattern recognition, particularly when scanning big and complicated datasets.
Common Vector Indexing Techniques
Different indexing techniques are used based on specific requirements. Let’s discuss some of these.
Inverted File (IVF)
The Inverted File (IVF) is a fundamental indexing technique that organizes data into clusters using methods like K-means clustering. Each vector in the database is assigned to a specific cluster. This structured arrangement significantly speeds up search queries.
When a new query arrives, the system identifies the nearest or most similar clusters instead of scanning the entire dataset, thus enhancing search efficiency.
Advantages
- Faster Search: By focusing on relevant clusters, the search is quicker.
- Reduced Query Time: Only a subset of the data is examined, reducing the time required.
- Variants of IVF: IVFFLAT, IVFPQ, and IVFSQ
- There are different variants of IVF, tailored to specific application requirements. Let's explore them in detail.
IVFFLAT
IVFFLAT is a simpler variant of IVF. It divides the dataset into clusters, and within each cluster, it employs a flat structure for storing vectors. This method strikes a balance between search speed and accuracy.
Implementation
- Storage: Vectors are stored in a straightforward list or array within each cluster.
- Search: When a query vector is assigned to a cluster, a brute-force search is conducted within that cluster to find the nearest neighbor.
IVFPQ
IVFPQ stands for Inverted File with Product Quantization. It also splits the data into clusters, but within each cluster, vectors are further divided into smaller components and compressed using product quantization.
Advantages
- Compact Storage: Vectors are stored in a compressed form, saving space.
- Faster Query: The search process is expedited by comparing quantized representations rather than raw vectors.
Implementation
- Quantization: Each vector is broken down into smaller vectors, and each part is encoded into a limited number of bits.
- Search: The quantized representation of the query is compared with those of vectors within the relevant cluster.
IVFSQ
IVFSQ, or Inverted File with Scalar Quantization, also segments data into clusters but uses scalar quantization. Here, each dimension of a vector is quantized separately.
Implementation
- Quantization: Each dimension is assigned predefined values or ranges to determine cluster membership.
- Search: Each component of the vector is matched against these predefined values.
Use Case
IVFSQ is particularly useful for lower-dimensional data, simplifying encoding and reducing storage space.
Hierarchical Navigable Small World (HNSW) Algorithm
The HNSW algorithm uses a sophisticated graph-like structure inspired by the probability skip list and Navigable Small World (NSW) techniques to store and fetch data efficiently.
HNSW Implementation
- Graph Structure: HNSW creates a multi-layer graph where each node (vector) is connected to a limited number of nearest neighbors.
- Search Efficiency: The algorithm navigates through these layers to quickly locate the nearest neighbors of a query vector.
Skip List
A skip list is an advanced data structure combining the quick insertion of a linked list with the rapid retrieval of an array. It organizes data across multiple layers, with each higher layer containing fewer data points.
- Layers: The bottom layer contains all data points, while each subsequent layer contains a subset.
- Search: Starting from the highest layer, the search progresses from left to right, moving down layers as necessary until the target data point is found.
Final Thoughts
Vector databases are crucial in generative AI, enabling advanced content generation and recommendation systems. An estimated 85% of generative AI models rely on these databases for data storage and retrieval. Vector databases enable advanced content generation and recommendation systems with an average improvement of 40% in accuracy and efficiency.
Their unique ability to transform complex data into high-dimensional vectors and efficiently search for semantic similarity has opened new doors for applications spanning recommendation systems, content moderation, knowledge bases, and more. As technology advances, the influence of vector databases is poised to grow, shaping how we harness and understand data in the digital era.

Top comments (1)
Shop high quality Corteiz at a sale price. Get up to 30% off online from uk store. crtzxyz.fr/cargo/