
At JetBrains, we use a single TeamCity installation to build all of our products – including the giants like IntelliJ IDEA, PyCharm, Kotlin, as well as hundreds of plugins, and a lot of internal products and services, such as the website.
In total, it amounts to 7500 projects, 50,000+ build configurations (jobs), and around 65,000 builds per day on average. This is all handled by 2000+ build agents (although this number is not static as a lot of them are launched on demand and run builds in hosted environments, such as AWS).

All of that is handled by our internal CI/CD server called buildserver which is running as a multi-node setup orchestrated by TeamCity. It’s all part of the standard TeamCity functionality, except for that it receives its new features and updates on a daily basis, as we use it for internal dogfooding.
At some point, this scale started posing some difficulties for us, as we noticed that during peak hours, newly triggered builds were sitting in the queue for half an hour or more, and basically did not start at all unless you manually moved it to the top.
In this moment, messages from the JetBrains developers were piling up in the teamcity-buildserver Slack channel:
Folks, my build is already more than 2 hours in queue. I see that there are similar problems above with reaching limits but I don’t see such messages, just
No estimateyet.
-
Builds seem to keep piling up in queue and taking longer and longer, are we heading toward a reboot?
-
Why does TeamCity start new builds so slowly? 20 minutes already, agents are idle.
-
Hi! I’m waiting for my build to start for 20 minutes, is it intended? During this time I see the agent summary changes, but the configurations don’t start. What is wrong?
We felt this pain. It would not be an exaggeration to say that this issue was driving some of us crazy for quite some time.
The build queue bottleneck was so annoying that we’ve decided to dig deeply into the core code of the product. In the end, we solved it. Here is the rundown of how we approached the problem.
The waiting reasons
For TeamCity to start a build, a lot of conditions should be satisfied. For instance, cloud agents should be launched, fresh commits and settings should be fetched from VCS repositories. If the build depends on some shared resources, then these resources should become available. If there are snapshot dependencies, they should be finished too. Finally, when all the conditions are met, the queue optimization kicks in and checks whether the build should be started at all or whether an already finished build could be reused instead (if this finished build has the same revision).
Experience of analyzing issues reported by our users shows that their configuration can be quite tricky and sometimes it is relying on nuanced behavior of some of the TeamCity features. So when we get a complaint that a build does not start, it’s not immediately clear where the problem is. The problem can be caused by some misconfiguration or there can be a performance problem in TeamCity itself. In any case we have to check a lot of different things to find out why the build is not starting.
How much time was spent on checking for changes? Well, one can go to the build log and see this information there. How much time we spent waiting for a shared resource? Unfortunately, it’s impossible to see it anywhere in the UI, but one can go to the server logs and find it there. How much time was spent on the queue processing? Again, only one of the server logs has this information.
Overall this was a major time waster. Even though internally TeamCity had all the knowledge about duration of different stages of the queued build, this information was shown in the user interface only after the build had already finished and at this point it’s too late to look for a bottleneck.
When we realized that we’re wasting time, we did one relatively simple improvement that helped us a lot. We started showing the reasons why the queued build does not start on the queued build page:
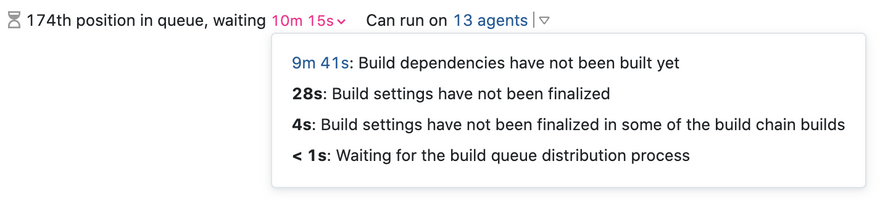
After that we finally started to see that with a large number of builds in the build queue the reason “Waiting for the build queue distribution process” was taking an unusually long time.
Build queue processing
In TeamCity, all the queued builds are being processed by a single thread in a loop. So the waiting reason “Waiting for the build queue distribution process” basically shows how much time TeamCity was processing other builds in the queue before it reached the current build.
In a bit simplified form the process is as follows:
- Run an optimization algorithm and remove all the obsolete build chains (a build chain is obsolete if a newer build chain with more recent set of changes is also in the queue).
- Enter the loop over the queued builds.
- For a queued build:
3.1. Schedule a checking for changes operation or obtain a fresh copy of settings from the version control.
3.2. Check preconditions: whether all dependencies are finished, or resources have become available, etc.
3.3. Find idle compatible agents and schedule start of the new cloud agents if necessary.
3.4. If an idle agent exists, check whether we really need to start the build, or maybe we can reuse an already running or a finished one.
3.5. If the build should be started: remove it from the queue, and schedule it’s start in a separate thread.
4.Go to Step 1.
Not all the parts of this process were visible as waiting reasons. Some parts were too low level to be shown in the user interface. But it made sense to add metrics for each of these operations so that we could show them on the Grafana dashboard.
It took some trial and error until we started to see how much time different stages were occupying.
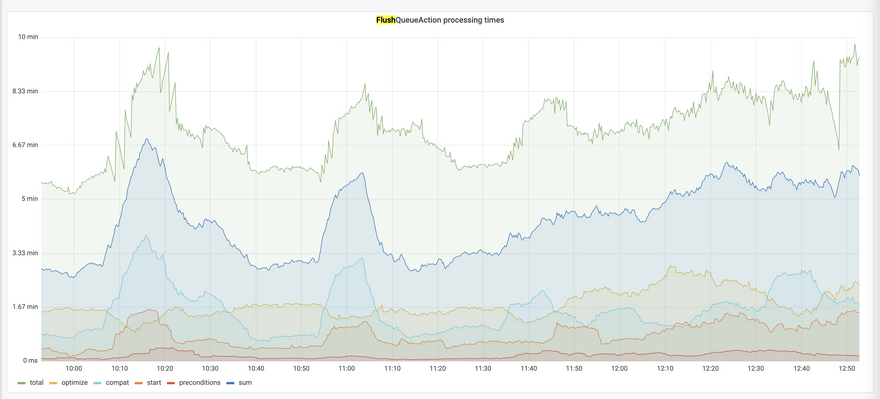
The “Move to top” issue
We already knew that the queue processing time was usually much smaller than the delays observed by the users. For instance, when they claimed that their build was in the queue for 40 minutes, the entire queue could be processed by the server for about 5 minutes (this is not fast at all, but it’s not 40 minutes either). Newly added metrics confirmed it once again: the delays are significantly smaller than those reported by the users. But why are the observed delays so high?
But then we figured out that there are many users who constantly use the "move to top" action in the build queue. Probably there are also automatic scripts which put builds to the top of the queue. So the builds of those who ended up complaining about huge delays were probably constantly overtaken by builds of their colleagues. These "moved to the top" builds were taking all the agents too. No wonder other builds could not start for much longer.
Fairness
Further analysis of the queue behavior showed that some builds could take a lot of time to process, while others were able to start immediately. It was not yet clear why, but given that the queue is processed by a single thread this raises a valid concern about fairness of the build queue. Why should some build wait for minutes just because some other project constantly triggers a lot of builds?
We were not able yet to pinpoint the root cause of the general slowness, but we still needed to provide a proper service to our users. As a temporary measure we decided to add a per-project limit for a number of queued builds to process by a single iteration.
For instance, we could say that the server processes not more than a 100 queued builds for a top level project such as IntelliJ IDEA per single iteration of the loop. This would allow us to limit the resources spent on a single project and make the process more fair.
Once implemented, some of the projects with lots of triggered builds started showing a new waiting reason:
Reached the limit for a number of simultaneously starting builds in this project: 50
With this workaround in place we’ve bought us some time to think about a proper fix as the delays now were at least bearable.
Build queue parallelization
There were extensive discussions about the possibility to parallelize the processing of the queue.
To clarify: processing of the queue is everything besides the actual start of the build on an agent. The start on an agent is where network communication happens and fortunately this part is already out of the main loop and is done in a separate pool of threads. However, it’s not so easy to parallelize the main loop because the builds have to be processed in the order. If a build was moved higher in the build queue then it should start before builds which are placed below. Otherwise this is no longer a queue but rather an unordered collection.
But what if we divide the build queue by agent pools? Within the same set of agents, the queued builds could be handled in the order, but the groups of builds using different sets of agents could be handled in parallel. Well, apparently many projects are residing in several pools. Some of these pools are common with other independent projects. So it was not clear if this division by agents could actually work.
It seems that the division by agent pools could still be implemented relatively easily. However, the “parallel processing” part of the task was not so easy. In TeamCity the build queue is a common resource, with optimized concurrent reads. But concurrent modifications are not fast. So there is a chance that with parallelized processing there will be a new bottleneck: modification and persisting of the build queue itself. Elimination of this bottleneck seemed like a task for months, but we needed a more short term solution.
A short term solution would be to make the main loop go through the queue and put the builds ready for the start into some other queue which could be handled by some separate thread working in parallel. In this case actual modification and persisting of the queue would happen in one thread only. This seemed like a more incremental approach which would also allow division by agent pools sometime later.
With this in mind, we’ve done a few refactorings towards this approach. We also had to improve the build queue optimization algorithm to ensure clear separation of the main loop thread and a thread which starts the builds marked for the start. And while changing the code we’ve found something interesting.
Compatible agents
With the newly published metrics, we’ve noticed that calculation of the compatible agents was taking a lot of time in some cases. To the point that this calculation was a dominating factor of the whole queue processing.
This seemed weird. First of all compatibility with an agent is cached inside a queued build, so it should not be a constant issue. Secondly, we only need to compute compatibility with a number of currently idle agents which is supposed to be small.
But the second part was not true apparently:
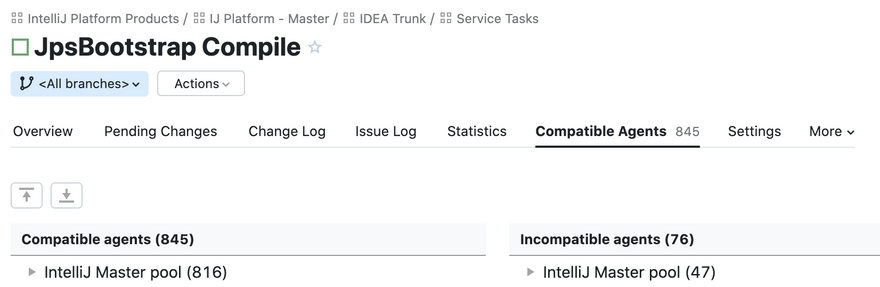
With mass adoption of AWS cloud agents it became possible to have several hundreds of idle agents in the same agent pool, all of them being compatible with a single queued build.
But why’d there be dozens or sometimes hundreds of “JpsBootstrap Compile” builds in the queue? Well, because it participates in many build chains: Safe push, Fleet project, Kotlin, etc. And these build chains are triggered quite often. Some of them are even triggered on every VCS commit.
Now it has become clear why compatibility calculation is a major bottleneck in projects with many hundreds of agents such as IntelliJ IDEA and why queued builds of this project delay the start of other builds.
Back to the queue processing algorithm
If we look at the queue processing algorithm again, then we’ll see something odd there:
…
3.3. Compute compatible agents and schedule start of the new cloud agents if necessary.
3.4. If an idle agent exists, check whether we really need to start the build, or maybe we can reuse an existing one.
…
So we first go through the hundreds of idle agents to find compatible agents among them, but then we decide whether we really need to run this build? This is odd. Why don’t we first decide if the queued build can be replaced with some other build, and only if there is no suitable build, and we really need to start a new one, then we’d compute compatible agents? The fix looked like a low hanging fruit.
Once implemented and deployed this simple optimization caused probably the most drastic effect on the build queue processing time. It turned out that it’s much cheaper to run the build queue optimization process rather than compute compatible agents, if the number of agents is quite high.
Conclusion
It took us a few months to finally resolve the issue. The path to the solution was not straightforward. Several small and not so small optimizations were implemented along the way.
The takeaway for us here is to not be shy to dig into the code and try something new. We found the problem with the compatible agents because we were changing the code, trying to prepare it for the parallelization. Without this refactoring, our chances to spot the real cause were quite low.
This is how the build queue processing looks now in our metrics:
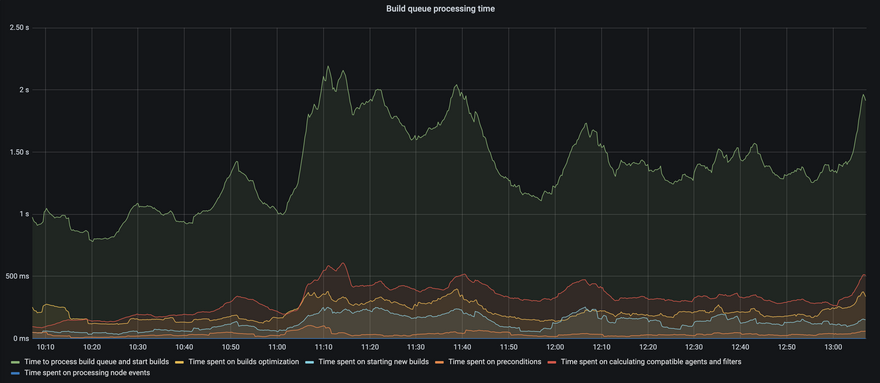
The delays are below 10 seconds most of the time, which seems acceptable for our buildserver and as far as we can see there are no more complaints on the Slack channel either.
All of the new optimizations became part of the TeamCity build that we distribute to our customers. Hopefully they felt these improvements too!

Top comments (3)
Whether you're a hardcore gamer or just looking for something fun on the go, Stickman Hook is a must-try. The game rewards precision and creativity with every perfectly timed swing.
Hi, optimization updates like that always feel satisfying because fewer complaints usually mean real progress, and during one late night reading tech threads I ended up opening duospin after noticing casino bonuses for players from Canada. I tried Gates of Olympus, had several losing spins in a row, then raised the bet a bit and landed a solid win that honestly reset my mood. Now a quick casino session helps me clear my head after long technical discussions.
Some comments may only be visible to logged-in visitors. Sign in to view all comments.