
Following the series of posts about preparing to use Terraform on a project.
So, in the first part, we thought about how to organize the preparation of the backend for the project, that is, to perform its bootstrap, and a bit — how to manage the Dev/Prod environments in general, see Terraform: Getting started and planning a new project — Dev/Prod and bootsrap. In the second part — how to configure State Lock and about remote state in general, see Terraform: remote state with AWS S3 and state locking with DynamoDB .
For now, I’ll left aside such solutions as Terraform Cloud, Terragrunt, Spacelift, Atlantis, and Cluster.dev — our project is still small, and I do not want to add additional complexity yet. Let’s start with a simple one, and when it fly, we’ll think about such tools.
Now, let’s try to put everything together and outline a plan for future automation.
So, what need to think about:
- backend management, or project bootstrap: bucket(s) for state files and DynamoDB table(s) for state lock:
- can be created by hand for each project
- you can create a separate project/repository and manage all backends in it
- can be created within each project at the beginning of work in the code of the project itself
- isolation by Dev/Prod environment:
- Terraform Workspaces: built-in Terraform feature, minimum code duplication, but there may be difficulties with navigation, can use only one backend (however with separate directories in it), more complex work with modules
- Git branches: built-in Git feature, ease of code navigation, the ability to have separate backends, but a lot of code duplication, possible troubles with transferring code between environments, difficulties in working with modules
- Separate Directories: maximum isolation and the ability to have separate backends and providers, but code duplication is possible
- Third-party tools: Terragrunt, Spacelif, Atlantis, etc. are great, but require additional time for engineering study and implementation
Today we will try an approach with bucket management for the backend from the code of the project itself, and Dev/Prod through separate directories.
Backend management, or project bootstrap
Here we will use the approach of creating a backend within each project at the start.
That is:
- first, we describe the creation of the Dynamo bucket and table
- then create resources
- configure the terraform.backend{} block
- import the local state to that S3
- describe and create all other resources
Dev/Prod environment by separate directories
How can things look with individual directories?
We can create a structure:
global-
main.tf: creation of resources for the backend – S3, Dynamo environmentsdev-
main.tf: here we include the necessary modules (duplicated with Prod, but different during development and testing of a new module) -
variables.tf: declare variables, common (duplicated with Prod), and specific to the environment -
terraform.tfvars: variable values, common (duplicated with Prod), and specific to the environment -
providers.tf: specific to the environment AWS/Kubernetes connection settings (especially useful when Dev/Prod are different AWS accounts) -
backend.tf: specific to the environment state file storage settings prodmodulesvpc-
main.tf– here, we’ll describe the modules -
backend.hcl– common parameters for state backend
Then we can deploy separate environments either by executing cd environments/dev && terraform apply or terraform apply -chdir=environments/dev. The backend configuration can be passed via terraform init -backend-config=backend.hcl.
Well, let’s try it and see how it can look like at work.
Creating a backend
Here we will make the backend from the code of the project itself, but I still think it is better to manage AWS resources for backends as a separate project in a separate repository, because with the scheme below, creating a new project looks a bit complecated: if the developers themselves will do it, then they will have to do additional steps, and for this you will need to write a separate doc. Better let them give a name of a project at the start to a devops team, who will create a bucket and a DynamoDB table, and then the developers will simply hardcode their names into project’s configs.
Create directories:
$ mkdir -p envs_management_test/{global,environments/{dev,prod},modules/vpc}
We are getting the following structure:
$ tree envs_management_test/
envs_management_test/
├── environments
│ ├── dev
│ └── prod
├── global
└── modules
└── vpc
In the envs_management_test/global directory, we need to describe the creation of a bucket and a table for locks.
But here is a question: what is better — have one basket for each env, or an only one, and keep states there dedicated by keys?
Multiple S3 buckets
If create a bucket for each env, then you can do it as follows:
- create a variable with the type
list, enter the names of the environments in this list - then when creating resources — use this list to cycle through each index in it
That is, our variables.tf can be like this:
variable "environments" {
description = "Environments names"
type = list(string)
default = ["dev", "prod", "global"]
}
In the file main.tf create resources as follows:
resource "aws_kms_key" "state_backend_kms_key" {
description = "This key is used to encrypt bucket objects"
deletion_window_in_days = 10
}
# create state-files S3 buket
resource "aws_s3_bucket" "state_backend_bucket" {
for_each = var.project_names
bucket = "tf-state-backend-${each.value}"
# to drop a bucket, set to `true`
force_destroy = false
lifecycle {
# to drop a bucket, set to `false`
prevent_destroy = true
}
tags = {
environment = var.environment
}
}
# enable S3 bucket versioning
resource "aws_s3_bucket_versioning" "state_backend_versioning" {
for_each = aws_s3_bucket.state_backend_bucket
bucket = each.value.id
versioning_configuration {
status = "Enabled"
}
}
Actually, it’s better to use [for_each
A single S3 for environments state files
But in order not to complicate the code, for now, we will make one bucket, and then for each environment, we will set its own key in its backend.
Let’s use a variable for the name:
variable "project_name" {
description = "The project name to be used in global resources names"
type = string
default = "envs-management-test"
}
And in the main.tf describe the resources themselves – here the code is the same as used in the previous post:
resource "aws_kms_key" "state_backend_bucket_kms_key" {
description = "Encrypt the state bucket objects"
deletion_window_in_days = 10
}
# create state-files S3 bukets per each Env
resource "aws_s3_bucket" "state_backend_bucket" {
bucket = "tf-state-bucket-${var.project_name}"
lifecycle {
prevent_destroy = true
}
}
# enable S3 bucket versioning per each Env's bucket
resource "aws_s3_bucket_versioning" "state_backend_bucket_versioning" {
bucket = aws_s3_bucket.state_backend_bucket.id
versioning_configuration {
status = "Enabled"
}
}
# enable S3 bucket encryption per each Env's bucket
resource "aws_s3_bucket_server_side_encryption_configuration" "state_backend_bucket_encryption" {
bucket = aws_s3_bucket.state_backend_bucket.id
rule {
apply_server_side_encryption_by_default {
kms_master_key_id = aws_kms_key.state_backend_bucket_kms_key.arn
sse_algorithm = "aws:kms"
}
bucket_key_enabled = true
}
}
# block S3 bucket public access per each Env's bucket
resource "aws_s3_bucket_public_access_block" "state_backend_bucket_acl" {
bucket = aws_s3_bucket.state_backend_bucket.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
# create DynamoDB table per each Env
resource "aws_dynamodb_table" "state_dynamo_table" {
name = "tf-state-lock-${var.project_name}"
billing_mode = "PAY_PER_REQUEST"
hash_key = "LockID"
attribute {
name = "LockID"
type = "S"
}
}
Create resources:
$ terraform init && terraform apply
Dynamic State Backend configuration
Next, we need to configure the backend for the global.
But in order not to repeat the same config for Dev && Prod later, we will export the common parameters of the backend in a separate file.
Create a backend.hcl file at the root of the project :
bucket = "tf-state-bucket-envs-management-test"
region = "us-east-1"
dynamodb_table = "tf-state-lock-envs-management-test"
encrypt = true
In the global directory create a backend.tf file:
terraform {
backend "s3" {
key = "global/terraform.tfstate"
}
}
Perform the initialization again, and in the -backend-config pass the path to the file with the backend parameters:
$ terraform init -backend-config=../backend.hcl
Initializing the backend...
Acquiring state lock. This may take a few moments...
Do you want to copy existing state to the new backend?
...
Enter a value: yes
...
Successfully configured the backend "s3"! Terraform will automatically
use this backend unless the backend configuration changes.
Initializing provider plugins...
- Reusing previous version of hashicorp/aws from the dependency lock file
- Using previously-installed hashicorp/aws v5.14.0
Terraform has been successfully initialized!
Check the bucket:
$ aws s3 ls tf-state-bucket-envs-management-test/global/
2023-08-30 16:57:10 8662 terraform.tfstate
The first state file is created.
Creating and using Terraform modules
Let’s add our own module for VPC. Here describe it manually, but for the Production, we will use the AWS VPC Terraform module.
In the modules/vpc/main.tf file describe the VPC itself:
resource "aws_vpc" "vpc" {
cidr_block = var.vpc_cidr
tags = {
environment = var.environment
created-by = "terraform"
}
}
Add a modules/vpc/variables.tf file with variables definitions:
variable "vpc_cidr" {
description = "VPC CIDR"
type = string
}
variable "environment" {
type = string
}
Next, add the vpc_cidr and environment variables in the environments/dev/variables.tf and environments/prod/variables.tf files:
variable "vpc_cidr" {
description = "VPC CIDR"
type = string
}
variable "environment" {
type = string
}
In the environments/dev/terraform.tfvars set values for these variables for the Dev:
vpc_cidr = "10.0.1.0/24"
environment = "dev"
And in the environments/prod/terraform.tfvars values for the Prod:
vpc_cidr = "10.0.2.0/24"
environment = "prod"
In both environments create a main.tf file with the VPC module included:
module "vpc" {
source = "../../modules/vpc"
vpc_cidr = var.vpc_cidr
environment = var.environment
}
Add providers.tf similar to the providers file in the global:
$ cp global/providers.tf environments/dev/
$ cp global/providers.tf environments/prod/
And in each create own backend.tf but with a different value in the key.
Dev:
terraform {
backend "s3" {
key = "dev/terraform.tfstate"
}
}
And Prod:
terraform {
backend "s3" {
key = "prod/terraform.tfstate"
}
}
Now we have the following structure of directories and files:
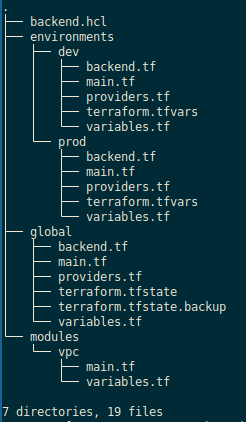
And we can deploy resources.
First Dev:
$ cd environments/dev/
$ terraform init -backend-config=../../backend.hcl
$ terraform apply
And repeat for the Prod:
$ cd ../prod/
$ terraform init -backend-config=../../backend.hcl
$ terraform apply
Check S3 states bucket:
$ aws s3 ls tf-state-bucket-envs-management-test/
PRE dev/
PRE global/
PRE prod/
And a state file:
$ aws s3 ls tf-state-bucket-envs-management-test/dev/
2023-08-30 17:32:07 1840 terraform.tfstate
Check if VPCs were created:
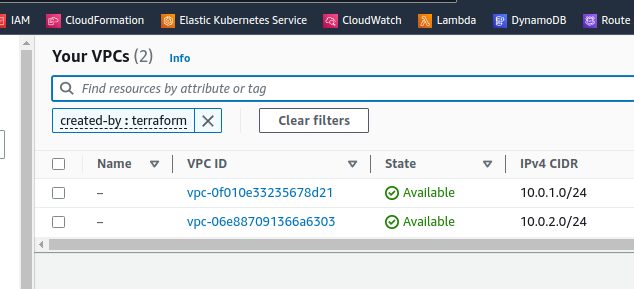
Dynamic environments
Good — the idea with the dedicated directories for Dev/Prod seems to work.
But what about dynamic environments, that is, when we want to create the infrastructure of the project during the creation of a Pull Request in Git, for tests?
Here we can use the following flow:
- create a brunch from the master brunch
- make our changes in the code of the
environments/dev/directory - initialize the new backend
- and deploy with
terraform apply -varand new variable values
Let’s check.
Initialize a new state. Add -reconfigure because we are doing it locally, and there is the .terraform directory. In the case when it will be performed with GitHub Actions the directory will be clean, and you can just run init.
In the second parameter -backend-config pass the new key for the state – where in the bucket save the new state file:
$ terraform init -reconfigure -backend-config=../../backend.hcl -backend-config="key=pr1111/terraform.tfstate"
Now deploy with the -var or pass values with variables as TF_VAR_vpc_cidr, see Environment Variables – in a pipeline, this can be done quite easily:
$ terraform apply -var vpc_cidr=10.0.3.0/24 -var environment=pr1111
Check the states in the bucket — and we must have a new directory called pr1111:
$ aws s3 ls tf-state-bucket-envs-management-test/
PRE dev/
PRE global/
PRE pr1111/
Done.
Useful links
- How to manage Terraform state
- Terraform manage multiple environments
- How to Manage Multiple Terraform Environments Efficiently
- How to manage multiple environments with Terraform using workspaces
- How to manage multiple environments with Terraform using branches
- How to manage multiple environments with Terraform using Terragrunt
- and a bit off topic, but might be useful too — Terraform: Destroy / Replace Buckets
Originally published at RTFM: Linux, DevOps, and system administration

Top comments (0)