Never lose a message again, and reduce your troubleshooting time with events with Memphis.dev real-time tracing
Have you ever got a call in the middle of the night saying “Infrastructure looks ok, but some service is not consuming data / messages get redelivered. Please figure it out”
Redelivered messages are also called “Poison messages”.
Poison messages = Messages that cause a consumer to repeatedly require a delivery (possibly due to a consumer failure) such that the message is never processed completely and acknowledged so that it can be stopped being sent again to the same consumer.
Example: Some message on an arbitrary queue pushed/pulled to or by a consumer. That consumer, for some reason, doesn't succeed in handling it. It can be due to a bug, an unknown schema, resources issue, etc…
In RabbitMQ, for example, quorum queues keep track of the number of unsuccessful delivery attempts and expose it in the "x-delivery-count" header that is included with any redelivered message. It is possible to set a delivery limit for a queue using a policy argument, delivery-limit. When a message has been returned more times than the limit the message will be dropped or dead-lettered (if a DLX is configured).
It is known to any developer that uses a queue / messaging bus that poison messages should be taken care of, and it's the developer's responsibility to do so.
In RabbitMQ, the most common, simple solution would be to enable DLX (dead-lettered queue), but it doesn't end there.
Recovering a poison message is just the first part, and the developer must also understand what causes this behavior and mitigate the issue.
Solutions
While there is the classic solution of committing/acknowledging a message as soon as possible, it’s not the best option for use cases requiring ensuring messages are acknowledged only when finished being handled.
Other approaches -
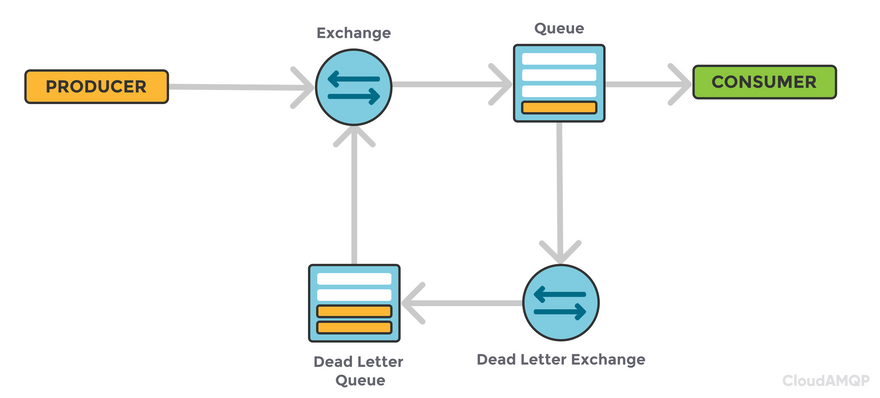
How to handle unacknowledged messages in RabbitMQ
- Turn on DLX
- Configure the DLX
- Place a routing key
- Build a dedicated consumer pointed to the DLX
- Consume the unacknowledged messages
- Fix the code/events
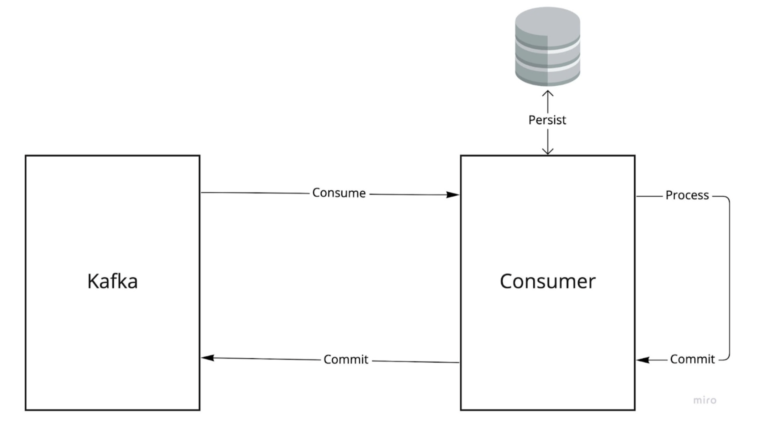
How to handle unacknowledged messages in Apache Kafka
There is no out-of-the-box redelivery/recovery of such messages.
Ensure there are logs within the code, tracking exceptions, and export to pagerduty/datadog/new relic/etc…
If the retention of a message is too small, it will be gone before the developer gets the chance to debug it. In most cases, the message will not be unique and can the loss, but in other, like transactions / atomic requests, it is. To mitigate this, a wrapper that provides this functionality should be made. A great example of such that provides that ability, and more is Wix’s GreyHound https://github.com/wix/greyhound. Definitely worth taking a look.
There are other use cases that utilize cache DB of some kind to persist the message while being processed before being getting committed.
Unacknowledged messages in Memphis.dev
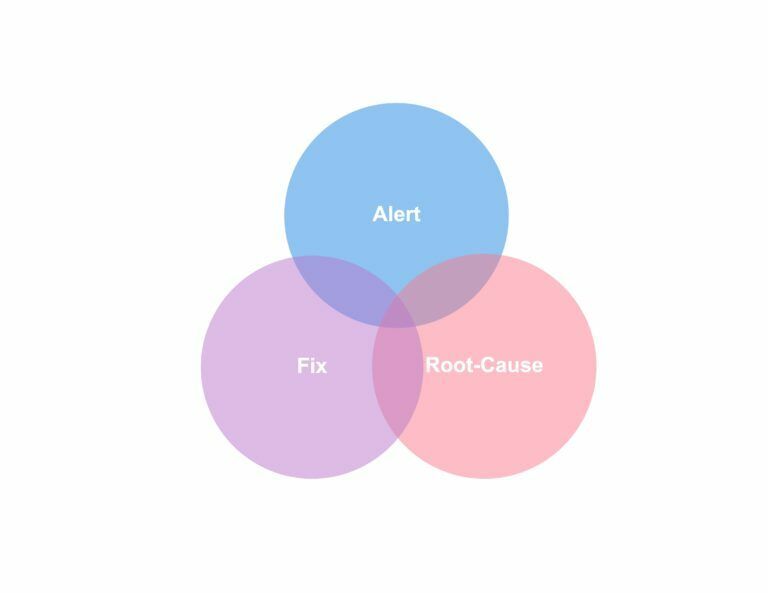
When we started to refine our approach, understand the needs, validate the experience, and craft the value it will bring to our users - three key objectives led our process -
- The entry point of a user to the issue.
- Quickly understand the problematic consumer and the root cause of the issue.
- Code gets fixed. The developer must debug the fix with a similar message to ensure it works.
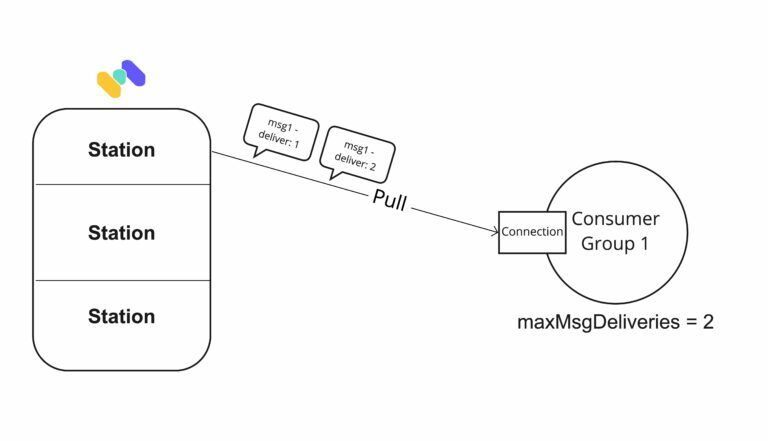
1 - Define the trigger
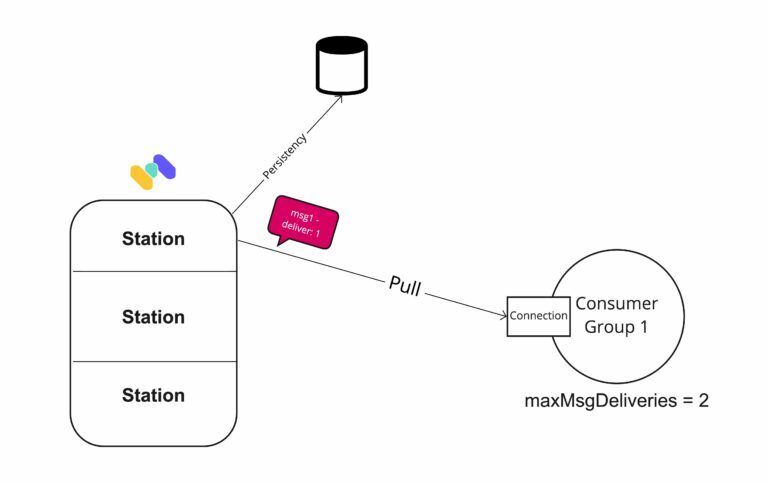
In Memphis broker, at the SDK level, we use a parameter called “maxMsgDeliveries.”
Once this threshold is reached, the broker will not repeatedly send the “failed-to-ack” message to the same consumer group.
2 - Notification
- Memphis broker senses the event of crossing the “maxMsgDeliveries = 2” per station, per consumer group.
- Persist the time_sent, and payload of the redelivered message to the Memphis file-based store for 3 hours.
- Mark the message as poisoned by a specific consumer.
- Create an alert.
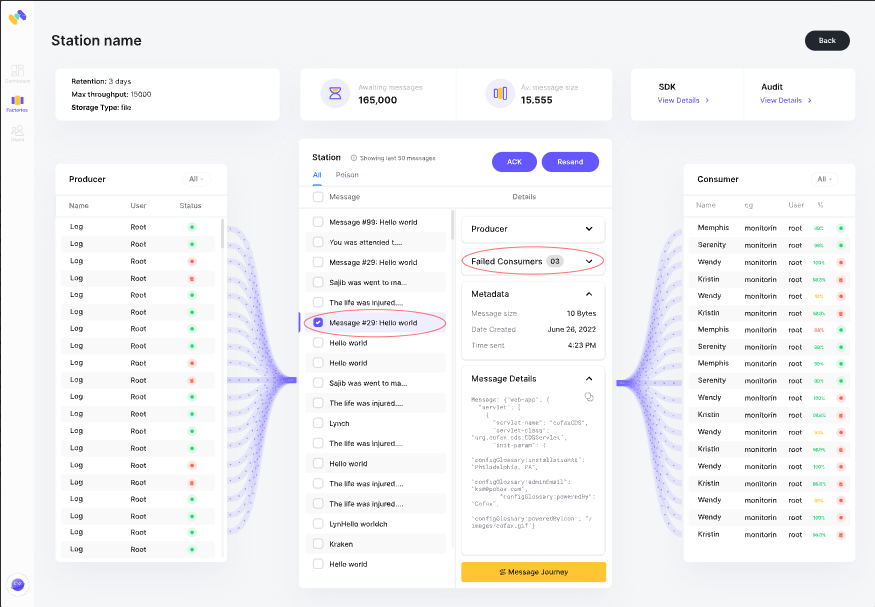
3 - Identify the consumer group which didn't acknowledge the message
Instead of going around through logs and multiple consumer groups, we wanted to narrow the finding to the minimum, so a simple click on the “real-time tracing” will lead to a graph screen showing the CGs which passed the redelivery threshold.
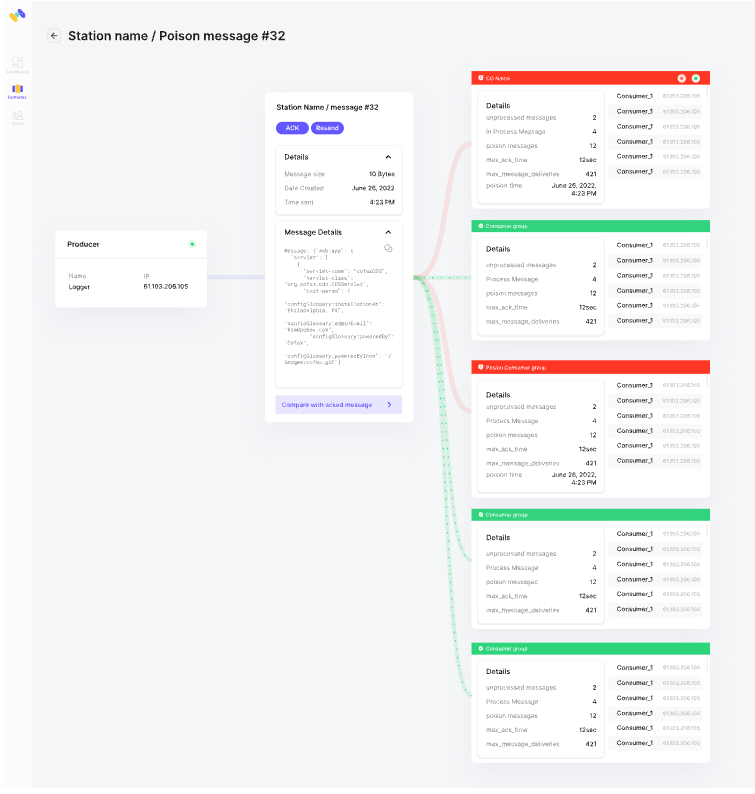
4 - Fix and Debug
After the developer understand what went wrong and creates a fix, before pushing the code which will lead to probably more adjustments when new messages will arrive, we have created the “Resend” mechanism which will push the unacknowledged message as many times as needed (Until ACK) to the consumer group that was not able to acknowledge the message in the first place.
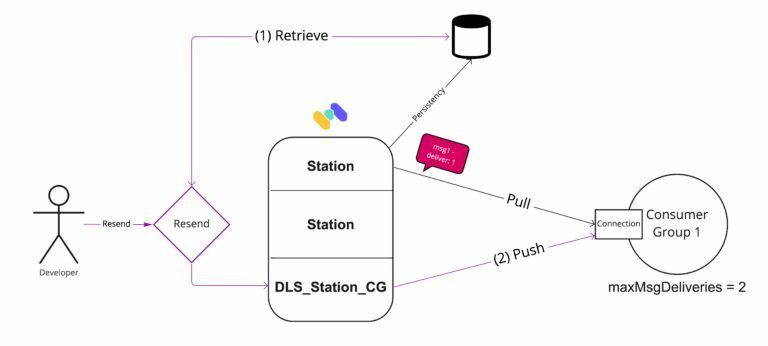
The unacknowledged message will be retrieved from Memphis internal DB, ingested into a dedicated station per station, per CG, and only upon request. Next, it will be pushed to the unacknowledged CG - WITHOUT ANY CODE CHANGE, using the same already-configured emit.
That’s it. No need to create a persistency process, cache DB, DLQ, or massy logic. You can be sure no message is lost.
Still under construction, but if you're interested - sandbox.memphis.dev
This article is written by Avraham Neeman

Top comments (8)
Hey @saar_ryan and @avraham_neeman thanks for sharing this post! I really appreciate you taking the time to share attribution to the original author. 😎
Did you know that you can create an organization page for Memphis.dev on The Ops Community, where you'll be able to share content by all your team members and attribute it to them directly? 🙌
Any content published by any member of your team will be displayed on a dedicated organization page where you can share a unique CTA and additional branding. Check out the info page here if you're curious to learn more!
I'm always on hand to answer any questions you might have about this or other features of this community!
Will surely do so! thanks for the advice :)
I see it!!
If you're the org admin, @saar_ryan, you can go to your personal dashboard to edit any posts you'd like to switch to the Memphis.dev organization. Let me know if you'd like a walkthrough.
Thanks for sharing
El tema de los mensajes tóxicos en comunidades tech es más común de lo que parece. Afecta la motivación y la forma en que compartimos ideas. Por eso valoro espacios donde puedo desconectar un poco y cambiar el chip. En mis pausas suelo alternar lectura con algo ligero, como mirar estadísticas deportivas en felixspins.es/app/
, sin dramas ni discusiones. Ese equilibrio ayuda a volver a las conversaciones con mejor ánimo, más paciencia y ganas reales de aportar algo útil al debate diario para mantener conversaciones sanas y respetuosas entre todos siempre.
To quickly identify which consumer group didn’t acknowledge the message, we used real-time tracing. Instead of checking logs and multiple groups manually, bodil udsen dødsårsag one click displayed a graph highlighting the consumer groups that exceeded the redelivery threshold, pinpointing the issue instantly.
Nice breakdown, I agree that removing poison messages makes systems more reliable and easier to maintain. After reading, it really helped me out while playing mobile game.
Nice breakdown, I agree that removing poison messages makes systems more reliable and easier to maintain. It also helped me out while playing mobile game.