What is Memphis.dev, what is Apache Kafka, and what are the strength and weaknesses of each framework

Let’s start!
The complete comparison table is at the bottom.
What is Memphis.dev?
A distributed message broker designed and constructed to make developers’ lives who work around event-driven software incredibly easier with event-level observability and troubleshooting tools. memphis.dev started as a fork of nats.io project (since 2011), written in GoLang, and creating its own stream on top.
Memphis.dev uses the same paradigm as Apache Kafka of produce-consume.
Memphis.dev Important objects
- Broker
- Factories
- Stations
- Producers
- Consumers / Consumer groups
- UI
- CLI
- Kubernetes
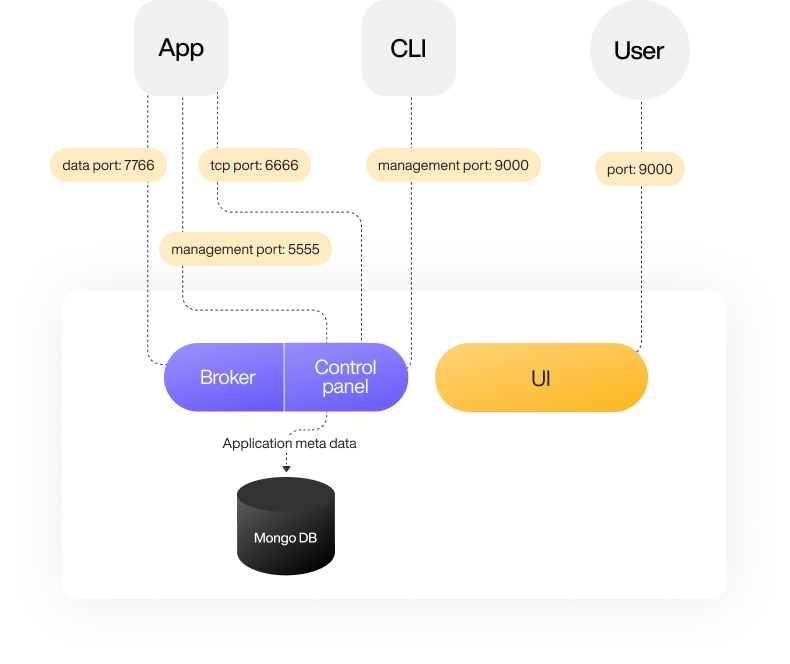
Memphis.dev flow
Memphis robust version deployed over Kubernetes using helm chart.
With Memphis deployment, also deployed is the UI, which provides the user with complete control over the entire Memphis cluster.
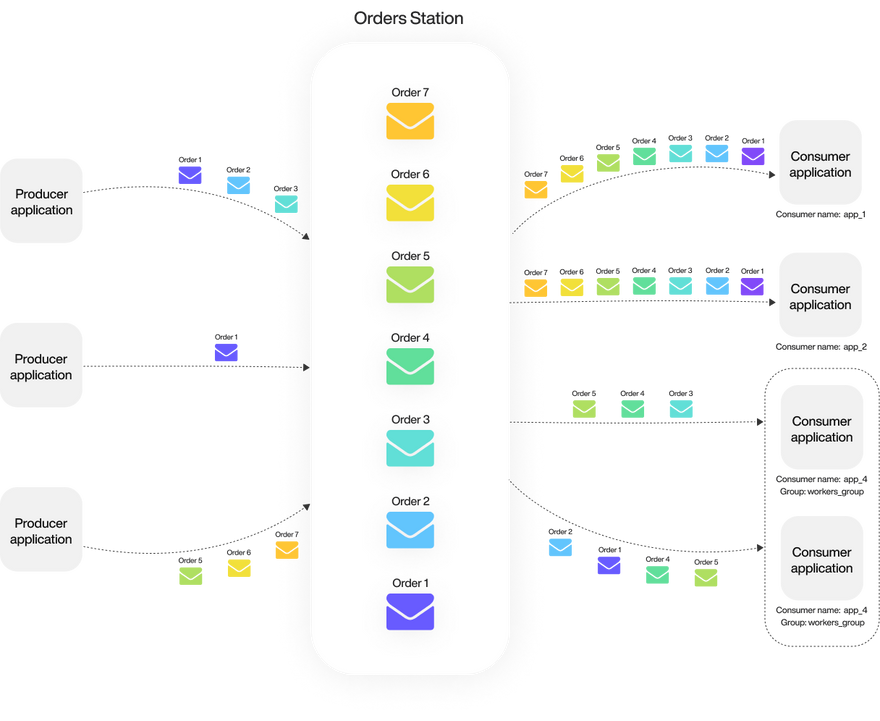
Compared to other terminologies like topics and queues, Memphis has stations that are grouped under factories.
Apps produce (write) and consume (read) data to and from stations.
To scale the performance and redundancy of consumers in a super easy manner, several consumers of the same kind can be grouped within the same consumer group.
Messages remain in the station until they hit the defined retention (defined at station creation), but will be consumed exactly once by the same consumer group.
Persistency (Where data is being saved)
- Memory — Higher performance, higher cost, redundant for up to two failed brokers.
- File — Lower performance, lower cost, redundant for an entire cluster breakdown.
Both are replicated across the brokers as defined by the user.
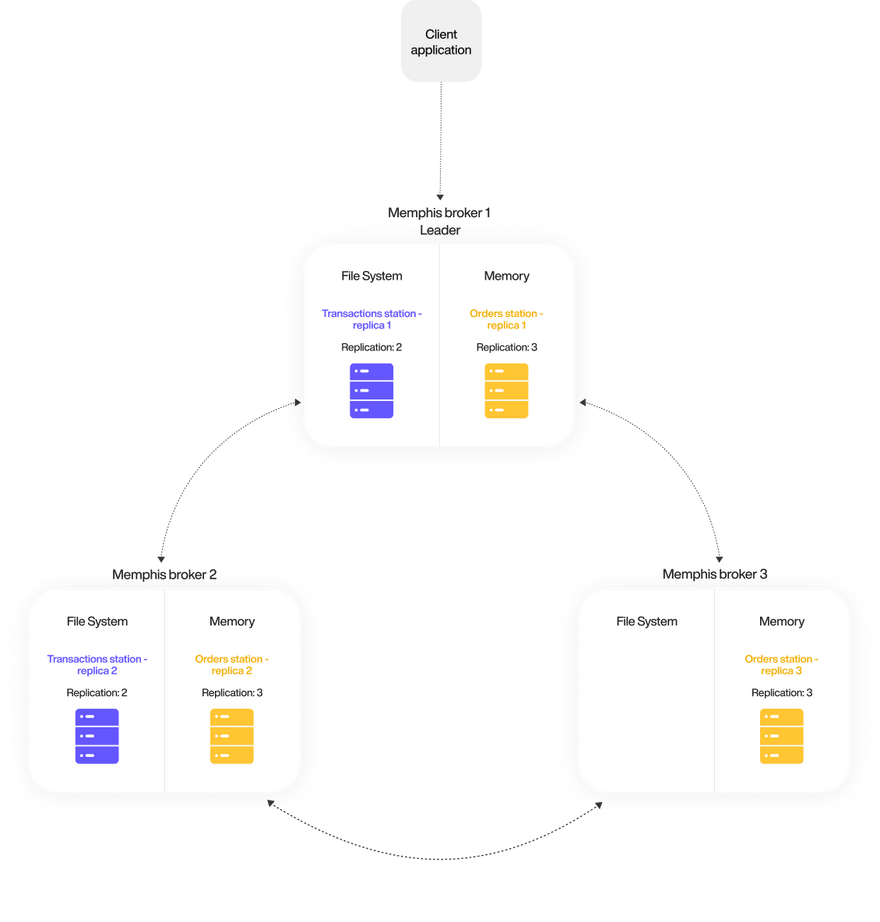
Redundancy / HA
- Cluster-mode — Made by multiple brokers (min. 3). Data is replicated across brokers. Redundant across AZs.
- Standalone — Made by a single broker.
What is Apache Kafka?
Apache Kafka is a distributed event store and stream-processing platform. It is an open-source system developed by the Apache Software Foundation written in Java and Scala. Well-known and 2nd most popular event store in the world after RabbitMQ.
Apache Kafka Important players
Consumer / Consumer groups
Producer
Kafka connect
Topic and topic partition
Kafka streams
Broker
Zookeeper (Will be moved soon)
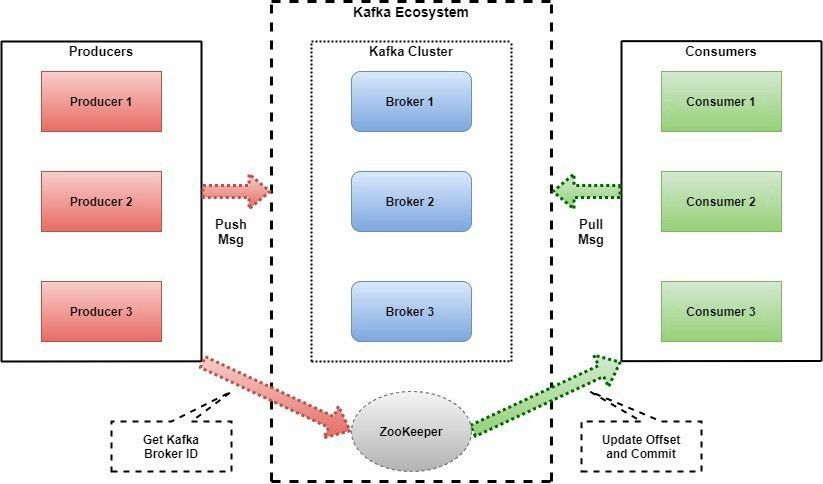
Apache Kafka flow
Apache Kafka is one of the most mature message brokers in the market.
Producers send a message record to a topic. A topic is a category or feed name to which records are published. Consumers subscribe to a topic and pull messages from it.
In Kafka, messages remain in the topic, also if they were consumed (limit time is defined by retention policy)
Heavy memory consumer for performance.
Persistency (Where data is being saved)
- Memory
- File (log files)
Redundancy / HA
Kafka does it by using Zookeeper to manage the state of the cluster.
In version 3.3, KRaft will be available for production use and remove the need for Zookeeper.
Bottom line
Apache Kafka has a strong maturity and large community, as well as battle-tested against large workloads and distributed environments, but it comprises multiple technical challenges in both ops, developer onboarding, troubleshooting, and cost.
Memphis.dev has a much smaller (yet a growing) community, and less documentation, but eliminates almost completely the need for operations and tunings, developers can onboard autonomously, run on any Kubernetes, and comes with observability and troubleshooting features that make it loveable by devs who are starting their way through the forests of event-driven and real-time.
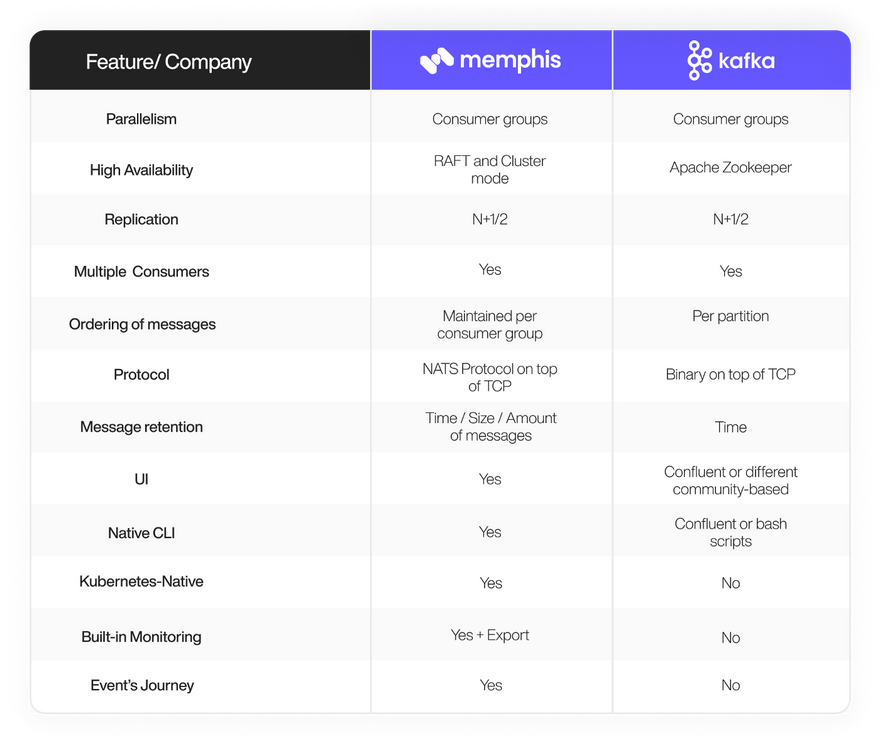
Comparison Table

Thanks for reading!

Latest comments (0)