Hopefully, by the end of this article, you will be able to understand the importance of using a message-driven architecture for building your next project.
Among the open-source projects, my college buddies (and my future co-founders of memphis.dev) and I built, you can find “Makhela”, a Hebrew word for choir.
For the sake of simplicity - We will use "Choir" 😅.
“Choir” was an open-source OSINT (Open-source intelligent) project focused on gathering context-based connections between social profiles using AI models like LDA and topic modeling, written in Python to explain what the world discusses over a specific domain and by high-ranking influencers in that domain and focus on what's going on at the margins. For proof-of-concept or MVP we used a single data source, fairly easy for integrations - Twitter.
The graph below was the “brain” behind “Choir”. The brain autonomously grows and analyzes new vertexes and edges based on incremental changes in the corpus and fresh ingested data.
Each vertex symbolizes a profile, a persona, and each edge emphasizes (a) who connects to who. (b) Similar color = Similar topic.
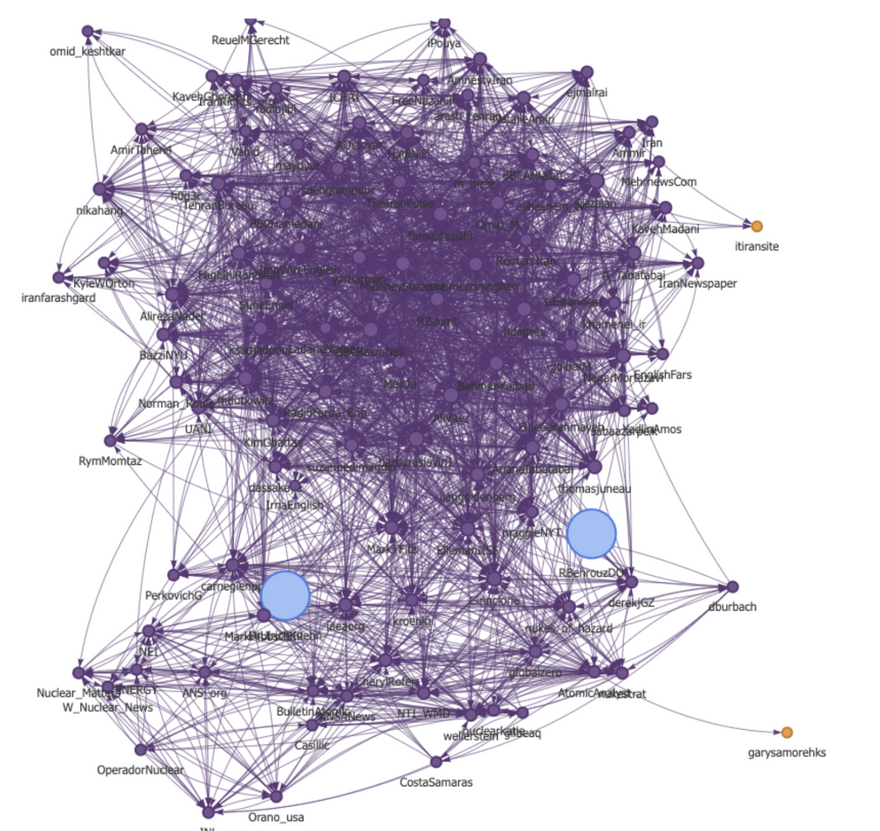
Purple = Topic 1
Blue = Topic 2
Yellow = Marginal topic
After a reasonable amount of research, dev time, and a lot of troubleshooting & debug, things started to look good.
Among the issues we needed to solve were:
- Understand the connection between profiles
- Build a ranking algorithm for adding more influencers
- Transform the schema of incoming data to a shape the analysis side knows how to handle
- Near real-time is crucial - Enrich each tweet with external data
- Adaptivity to "Twitter" rate limit
- Each upstream or schema change crashed the analysis functions
- Sync between collection and analysis, which were two different components
- Infrastructure
- Scale
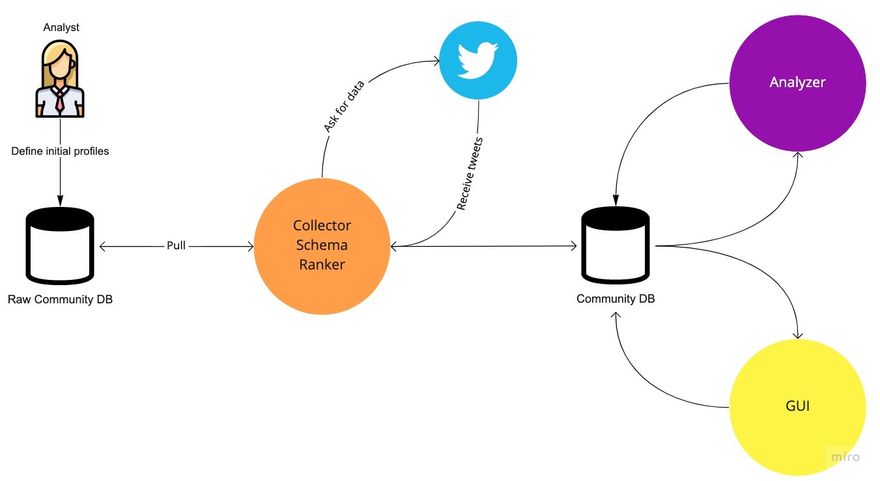
As with any startup or early-stage project, we built “Choir” as MVP, Working solely with “Twitter”, and it looked like this -
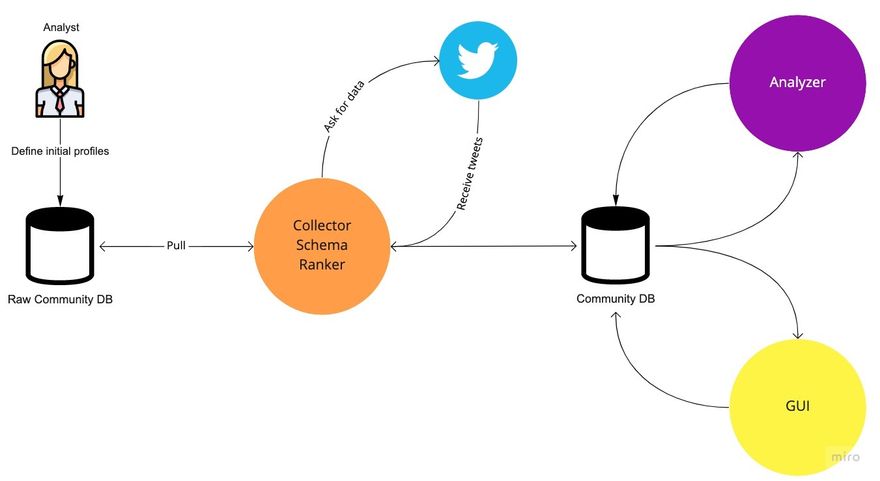

The “Collector” is a monolith, python-written application that basically collects and refines the data for analysis and visualization in batches and in a static timing every couple of hours.
Problems started to arise as the collected data and its complexity grew. The amount of processing cycle each batch processing took to be analyzed turned into hours for no good reason in terms of the capacity of the collected data (Hundreds of Megabytes at most!!). More on the rest of the challenges in the next sections.
Fast forward a few months later, users started to use “Choir”!!!
Not just using, but actually engaging, paying, and raising feature requests.
Any creator’s dream!
But then it hit us.
(a) "Twitter" is not the center of the universe, and we need to expand “Choir” to more sources.
(b) Any minor change in the code breaks the entire pipeline.
(c) Monolith is a death sentence to a data-driven app performance-wise.
As with every eager-to-run project that starting to get good traction, fueling that growth and user base is your number 1, 2, and 3 priority,
and the last thing you want to do at this point is to go back and rebuild your framework. You want to continue the momentum.
With that spirit in our mind, we said "Let's add more data sources and refactor in the future". Big Mistake.
Challenges in scaling a data-driven application
- Each new data source requires a different schema transformation
- Each schema change causes a chain of reaction downstream to the rest of the stages in the pipeline
- Incremental / climbing collection. While you can wait for an entire batch collection to finalize and then save it to the DB, applications often get crashed. Imagine you're doing a very slow collection and in the very last record, the collection process gets crashed
- In a monolith architecture, it's hard to scale out the specific functions which require more power
- Analysis functions often require modifications, upgrades, and algorithms to get better results, which are made by using or requiring different keys from the collectors. While there is no quick fix, what we can do is build a framework to support such requirements.
Solutions
Option 1 - Duplicate the entire existing process to another source, for example, “Facebook”.
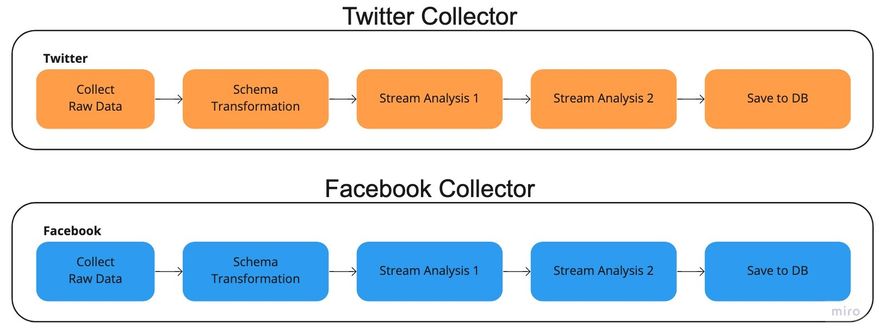
Besides duplicating the collector, we needed to -
- Maintain two different schemas (Nightmare)
- Entirely different analysis functions. The connections between profiles on Facebook and "Twitter" are different and require different objective relationships.
- The analyzer should be able to analyze the data in a joined manner, not individually; therefore, any minor change in source X directly affects the analyzer and often crashes it down.
- Double maintenance
And the list goes on…
Long story short, it cant scale.
Option 2 - Here it comes. Using a message broker!
I want to draw a baseline. A message broker is not the solution but a supporting framework or a tool to enable branched, growing data-driven architectures.
What is a message broker?
“A message broker is an architectural pattern for message validation, transformation, and routing. It mediates communication among applications[vague], minimizing the mutual awareness that applications should have of each other in order to be able to exchange messages, effectively implementing decoupling.[4]”. Wikipedia.
Let’s translate it to something we can grasp better.
A message broker is a temporary data store. Why temporary? Because each piece of data within it will be removed after a certain time, defined by the user. The pieces of data within the message broker are called “messages.” Each message usually weighs a few bytes to a few megabytes.
Around the message broker, we can find producers and consumers.
Producer = The “thing” that pushes the messages into the message broker.
Consumer = The “thing” that consumes the messages from the message broker.
“Thing” means system/service/application/IoT/some objective that connects with the message broker and exchanges data.
Small note the same service/system/app can act as a producer and consumer at the same time.
Messaging queues derive from the same family, but there is a crucial difference between a broker and a queue.
- MQ uses the term publish and subscribe. The MQ itself pushes the data to the consumers and not the other way (consumer pulls data from the broker)
- Ordering is promised. Messages will be pushed in the order they receive. Some systems require it.
- The ratio between a publisher (producers) and subscribers is 1:1. Having said it, modern versions can achieve it by some features like exchange and more.
Famous message brokers/queues are Apache Kafka, RabbitMQ, Apache Pulsar, and our own Memphis.dev
Still with me? Awesome!
Let’s understand how using a message broker helped “Choir” to scale.
Instead of doing things like this -
By decoupling the app to smaller microservices, and orchestrating the flow using a message broker, it turned into this -
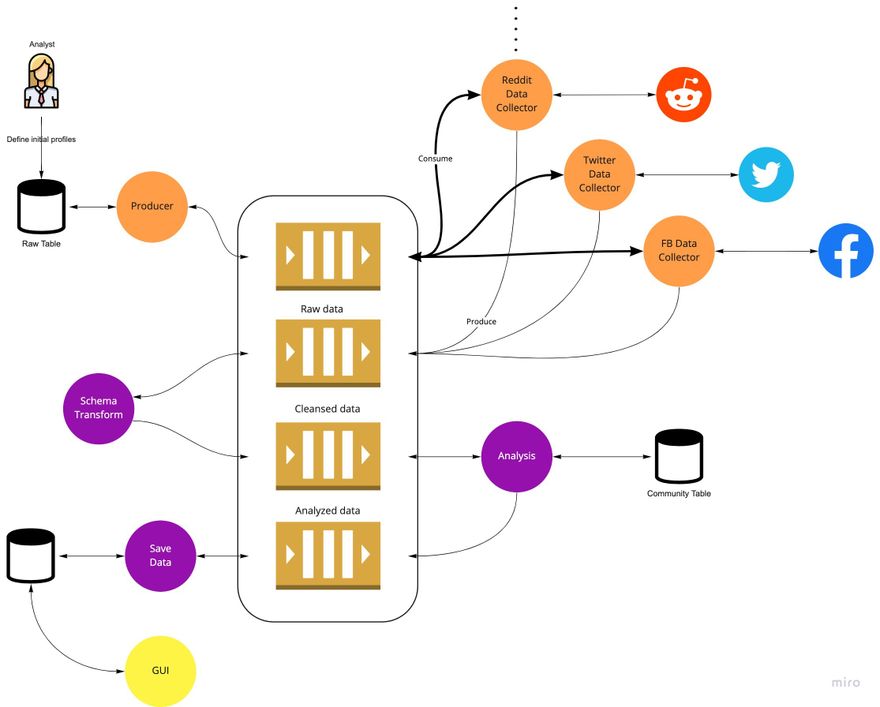
Starting from the top-left corner, each piece of data (tweet/post) inserted into the system automatically triggers the entire process and flows between the different stages.
- Collection. The three collectors search each new profile added to the community in parallel. If any more data source/social network is needed - it's been developed on the side, and once ready, start listening for incoming events. Allows infinite scale of sources, ability to work on the specific source without disrupting the others, micro-scaling for better performance of each source individually, and more.
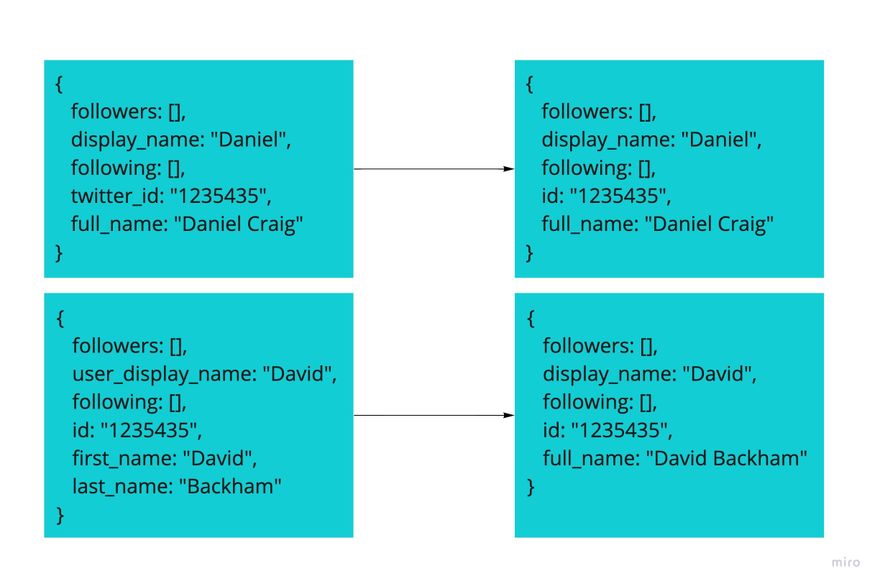
- Transformation. Once the collection is complete, results will be pushed to the next stage, “Schema transformation,” where the schema transformation service will transform the events’ schemas into a shape the analysis function can interpret. It enables a “single source of truth” regarding schema management, so in case of upstream change, all is needed to reach out to this service and debug the issue. In a more robust design, it can also integrate with an external schema registry to make maintenance even more effortless.
- Analysis. Each piece of event is sent to the analysis function transformed, and in a shape the analysis function can interpret. In “Choir” we used different AI models. Scaling it was impossible, so moving to analysis per event definitely helped.
- Save. Creates an abstraction between “Choir” and the type of database + ability to batch several insertions to a single batch instead of request per event.
The main reason behind my writing is to emphasize the importance of implementing a message broker pattern and a technology as early as possible to avoid painful refactoring in the future.
Yes, your roadmap and added features are important, Yes it will take a learning curve, yes it might look like an overkill solution for your stage, but when it comes to a data-driven use case, the need for scale will reveal quickly in performance, agility, feature additions, modifications, and more. Bad design decisions or a lack of proper framework will burn out your resources. It is better to build agile foundations, not necessarily enterprise-grade, before reaching the phase you are overwhelmed by users and feature requests.
To conclude, the entry barrier for a message broker is definitely worth your time.
Special thanks to Yaniv Ben-Hemo for the writing

Oldest comments (2)
Thanks a lot for sharing!
Hope it will help someone out there.
Thanks for the cool writing!