
We are all familiar with drifting in-app configuration and IaC. We’re starting with a specific configuration, backed with IaC files. Soon after, we are facing a “drift” or a change between what is actually configured in our infrastructure and our files. The same behavior happens in data. Schema starts in a certain shape. As data ingestion grows and scales to different sources, we get a schema drift, a messy, unstructured database with UI crashes, and an analytical layer that keeps failing due to a bad schema.
We will learn how to deal with the scenario and how to work with dynamic schemas.
Schemas are a major struggle.
A schema defines the structure of the data format.
Keys/Values/Formats/Types, a combination of all, results in a defined structure or simply – schema.
Developers and data engineers, have you ever needed to recreate a NoSQL collection or recreate an object layout on a bucket because of different documents with different keys or structures?
You probably did.
An unaligned record structure across your data ingestion will crash your visualization, analysis jobs, and backend, and it is an ever-ending chase to fix it.
Schema drift
Schema drift is the case where your sources often change metadata. Fields, keys, columns, and types can be added, removed, or altered on the fly.
Your data flow becomes vulnerable to upstream data source changes without handling schema drift. Typical ETL patterns fail when incoming columns and fields change because they tend to be tied to those sources. Stream requires a different toolset.
The following article will explain the existing solutions and strategies to mitigate the challenge and avoid schema drift, including data versioning using lakeFS.
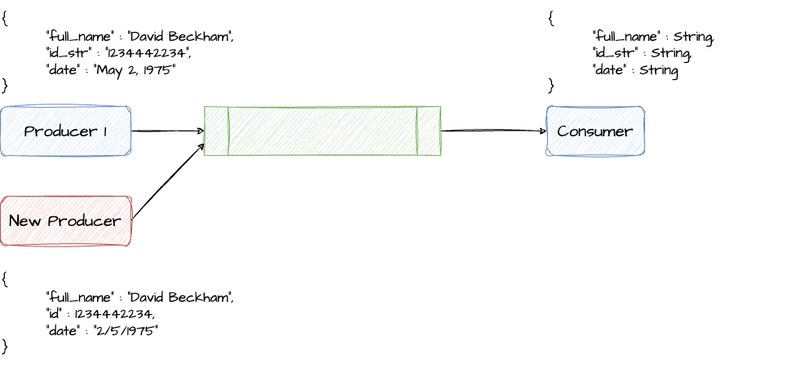
Comparison between Confluent Schema Registry and Memphis Schemaverse
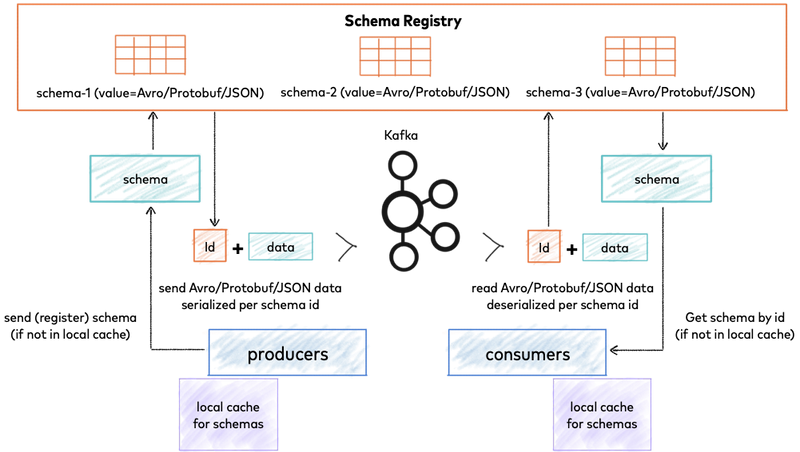
Confluent — Schema Registry
Confluent Schema Registry provides a serving layer for your metadata. It provides a RESTful interface for storing and retrieving your Avro®, JSON Schema, and Protobuf schemas. It stores a versioned history of all schemas based on a specified subject name strategy, provides multiple compatibility settings, and allows the evolution of schemas according to the configured compatibility settings and expanded support for these schema types. It provides serializers that plug into Apache Kafka® clients. They handle schema storage and retrieval for Kafka messages that are sent in any of the supported formats.
The good
- UI
- Support Avro, JSON Schema, and protobuf
- Enhanced security
- Schema Enforcement
- Schema Evolution
The bad
- Hard to configure
- No external backup
- Manual serialization
- Can be bypassed
- Requires maintenance and monitoring
- Mainly supports in java
- No validation
Schema registry overview. Confluent Documentation
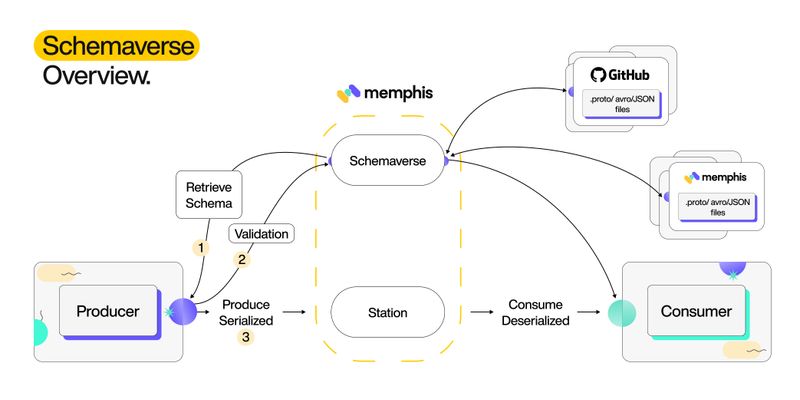
Memphis — Schemaverse
Memphis Schemaverse provides a robust schema store and schema management layer on top of the memphis broker without a standalone compute or dedicated resources. With a unique and modern UI and programmatic approach, technical and non-technical users can create and define different schemas, attach the schema to multiple stations and choose if the schema should be enforced or not.
Memphis’ low-code approach removes the serialization part as it is embedded within the producer library.
Schema Verse supports versioning, GitOps methodologies, and schema evolution.
The good
- Great UI and programmatic approach
- Embed within the broker
- Zero-trust enforcement
- Versioning
- Out-of-the-box monitoring
- GitOps. Working with files
- Low/no-code validation and serialization
- No configuration
- Native support in Python, Go, Node.js
The bad
- Not supporting all formats yet. Protobuf and JSON only. GraphQL and Avro are next.
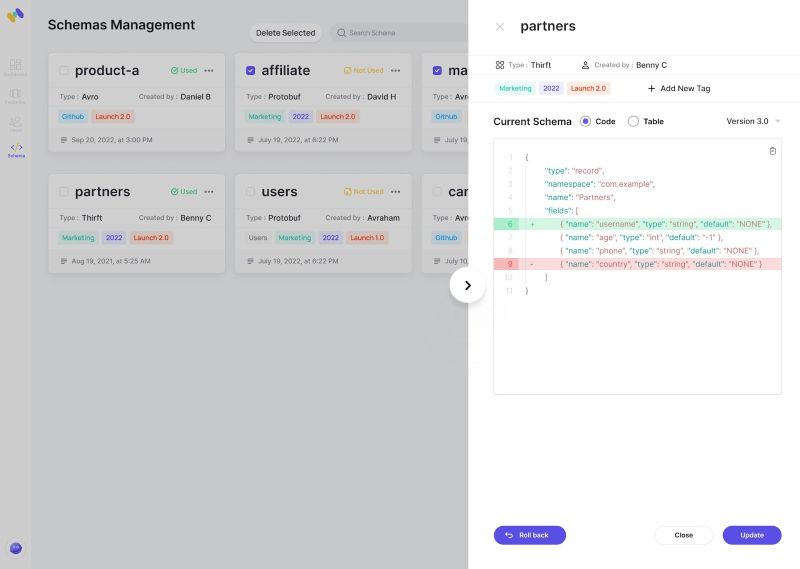
How to avoid schema drifting using Confluent Schema Registry
Avoid schema drifting means that you want to enforce a particular schema on a topic or station and validate each produced data. This tutorial assumes that you are using Confluent cloud with registry configured. If not, here is a Confluent article on how to install the self-managed version (without enhanced features).
To make sure you are not drifting and maintaining a single standard or schema structure in our topic, you will need to
- Copy ccloud-stack config file to $HOME/.confluent/java.config.
- Create a topic.
- Define a schema. For example-
{
"namespace": "io.confluent.examples.clients.basicavro",
"type": "record",
"name": "Payment",
"fields": [
{"name": "id", "type": "string"},
{"name": "amount", "type": "double"}
]
}
Enable schema validation over the newly created topic.
Configure Avro/Protobuf both in the app and with the registry.
Example producer code in Maven
...
import io.confluent.kafka.serializers.KafkaAvroSerializer;
...
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
...
KafkaProducer<String, Payment> producer = new KafkaProducer<String, Payment>(props));
final Payment payment = new Payment(orderId, 1000.00d);
final ProducerRecord<String, Payment> record = new ProducerRecord<String, Payment>(TOPIC, payment.getId().toString(), payment);
producer.send(record);
Because the pom.xml includes avro-maven-plugin, the Payment class is automatically generated during compile.
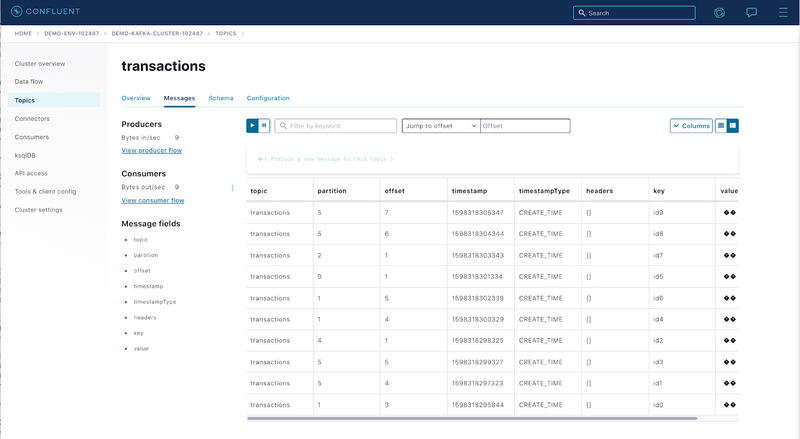
In case a producer will try to produce a message that is not struct according to the defined schema, the message will not get ingested.
How to avoid schema drift using Memphis Schemaverse
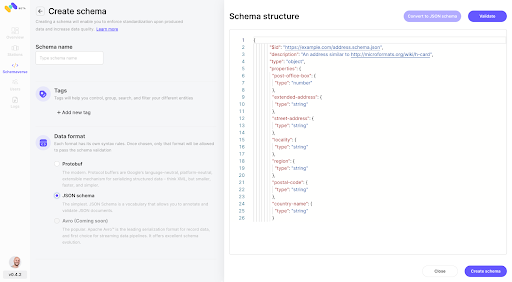
Step 1: Create a new schema (Currently only available through Memphis GUI)
Step 2: Attach Schema
Head to your station, and on the top-left corner, click on “+ Attach schema”
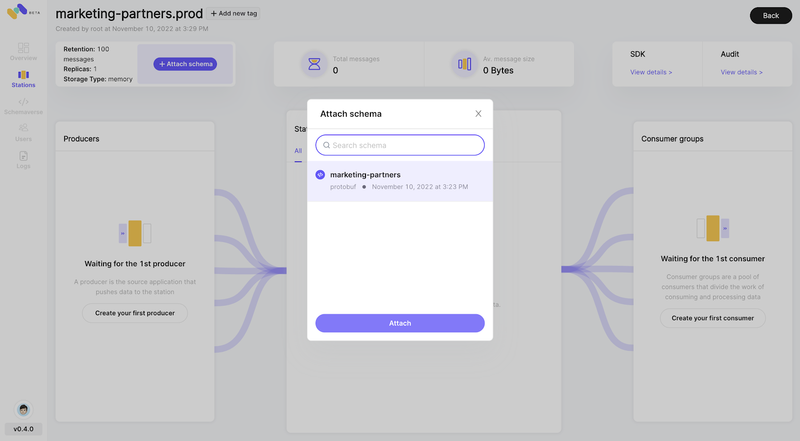
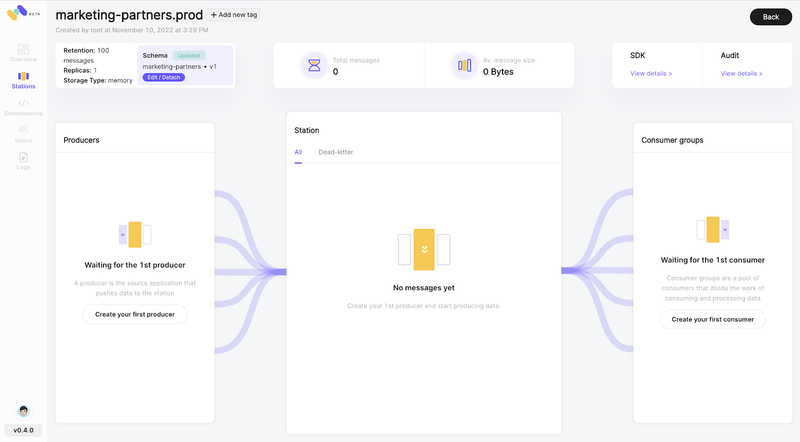
Step 3: Code example in node.js
Memphis abstracts the need for external serialization functions and embeds them within the SDK.
Producer (Protobuf example)
const memphis = require("memphis-dev");
var protobuf = require("protobufjs");
(async function () {
try {
await memphis.connect({
host: "localhost",
username: "root",
connectionToken: "*****"
});
const producer = await memphis.producer({
stationName: "marketing-partners.prod",
producerName: "prod.1"
});
var payload = {
fname: "AwesomeString",
lname: "AwesomeString",
id: 54,
};
try {
await producer.produce({
message: payload
});
} catch (ex) {
console.log(ex.message)
}
} catch (ex) {
console.log(ex);
memphis.close();
}
})();
Consumer (Requires .proto file to decode messages)
const memphis = require("memphis-dev");
var protobuf = require("protobufjs");
(async function () {
try {
await memphis.connect({
host: "localhost",
username: "root",
connectionToken: "*****"
});
const consumer = await memphis.consumer({
stationName: "marketing",
consumerName: "cons1",
consumerGroup: "cg_cons1",
maxMsgDeliveries: 3,
maxAckTimeMs: 2000,
genUniqueSuffix: true
});
const root = await protobuf.load("schema.proto");
var TestMessage = root.lookupType("Test");
consumer.on("message", message => {
const x = message.getData()
var msg = TestMessage.decode(x);
console.log(msg)
message.ack();
});
consumer.on("error", error => {
console.log(error);
});
} catch (ex) {
console.log(ex);
memphis.close();
}
})();
Schema enforcement with data versioning.
Now that we know the many ways to enforce schema using Confluent Or Memphis, let us understand how a versioning tool like lakeFS can seal the deal for you.
What is lakeFS?
lakeFS is a data versioning engine that allows you to manage data, like code. Through the Git-like branching, committing, merging, and reverting operations, managing the data and in turn the schema over the entire data life cycle is made simpler.
How to achieve schema enforcement with lakeFS?
By leveraging the lakeFS branching feature and webhooks, you can implement a robust schema enforcement mechanism on your data lake.
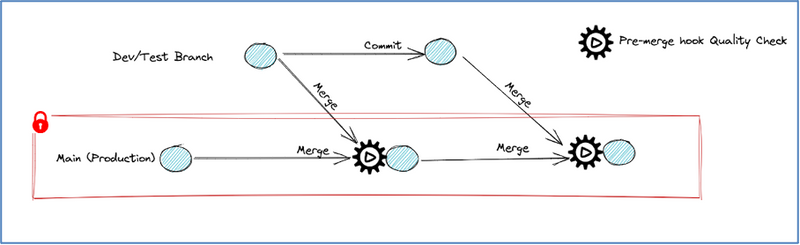
lakeFS hooks allow automating and ensuring a given set of checks and validations run before important life-cycle events. They are similar conceptually to Git Hooks, but unlike Git, lakeFS hooks trigger a remote server which runs tests and so it is guaranteed to happen.
You can configure lakeFS hooks to check for specific table schema while merging data from development or test data branches to production. That is, a pre-merge hook can be configured on the production branch for schema validation. If the hook run fails, it causes lakeFS to block the merge operation from happening.
This extremely powerful guarantee can help implement schema enforcement and automate the rules and practices that all data sources and producers should adhere to.
Implementing schema enforcement using lakeFS:
Start by creating a lakeFS data repository on top of your object store (say, AWS S3 bucket for example).
All the production data (single source of truth) can live on the
mainbranch orproductionbranch in this repository.You can then create a
devor a ‘staging’ branch to persist the incoming data from the data sources.Configure a lakeFS webhooks server. For example, a simple python flask app that can serve http requests can be a webhooks server. Refer to sample flask app that lakeFS team has put together to get started.
Once you have the webhooks server running, enable webhooks on a specific branch by adding
actions.yamlfile under_lakefs_actionsdirectory.
Here is a sample actions.yaml file for schema enforcement on master branch:
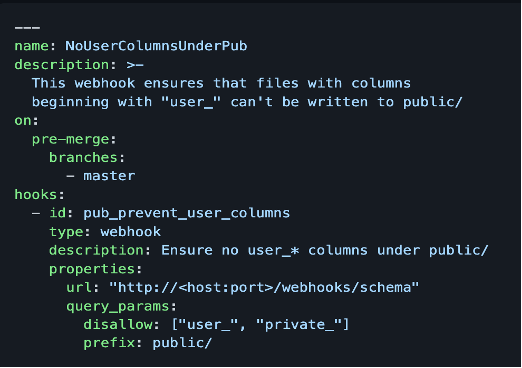
- Suppose the schema of incoming data is different from that of production data, the configured lakeFS hooks will be triggered on pre-merge condition, and hooks will fail the merge operation to master branch.
This way, you can use lakeFS hooks to enforce the schema, validate your data to avoid PII columns leakage in your environment, and add data quality checks as required.
To understand more about configuring hooks and effectively using them, refer to our lakeFS, git for data — documentation.
Article by Yaniv Ben Hemo Co-Founder & CEO @Memphis.dev
ֿ
Follow Us to get the latest updates!
Github • Docs • Discord
Join 4500+ others and sign up for our data engineering newsletter.

Top comments (0)