
A hackathon is the perfect embodiment of several of Lob’s core values including Be bold, Move fast, take action, and Level up! It’s an opportunity to step outside the daily hustle, collaborate, innovate, and problem-solve. The only thing more fun than a hackathon is a themed hackathon—especially when the theme is Halloween!

We want to acknowledge the hard work our Product and Engineering teams put in by highlighting their projects; the following is a technical recap of Lob’s Halloween Hackathon 2023.
SQS-consumer gets a glow up
Many of our projects focused on improving the developer experience at Lob, but a few innovative Lobsters created a new open-source library that also benefits our community as well.
AWS SQS, or Simple Queue Service, is a piece of infrastructure offered by Amazon; it’s a powerful tool processing data in a controlled manner. “Sqs-consumer” is an existing open-source library for working with SQS.
Though it’s a very popular library—we use it in Lob API and other services—it is not being maintained (major issues and suggested features are not getting attention) and perhaps most importantly, it’s not been upgraded to the new version of AWS SDK (V3). This prohibits us from upgrading many of our workers, and Lob API as a whole, to V3 of the SDK.
Solution: A new repo for working with SQS @lob/sqs-consumer! It's an open fork of the previous package, but it makes a few key changes:
Upgrade underlying AWS SDK to V3
Upgraded all dependencies
Converted test suite from an outdated version of Mocha to Jest
Fixed challenges with FIFO queues
Even though we now offer a low-code solution to automate direct mail (via our Campaigns product), we will always be a developer-first company. This library is a big win for our engineers, and we look forward to feedback and contribution from the developer community.
Software Engineer, Sishaar Rao (with help from Staff Software Engineer, Landon Barnickle, and Senior Software Engineer, Hanqing Chen) tied for second place for this ingenious project.
o11y is the bee’s knees
Another hackathon project focused on increasing our understanding of the services at play at Lob. Staff Software Engineer Rich Sevoria and Senior Software Engineer Benny Kitchell teamed up to tackle observability.
Lob’s rendering engine transforms HTML templates into print-ready PDFs, at scale. Every so often, we’ll encounter a glitch, and debugging can be a very manual—and painful—process. Most of the logging is contained within an internal service so any one individual lacks full visibility into all the services that are connected to each other and where they are failing. Ideally, you could visualize what's taking place, how long it takes, and in what order.
Sevoria proposed a two-part solution.
First, utilizing Open Telemetry, or OTel, ”a vendor-neutral open-source Observability framework for instrumenting, generating, collecting, and exporting telemetry data such as traces, metrics, logs.” Using traces and spans, we can get detail and visualization of all the events that took place across multiple services that aren't connected in any way outside of that they're all our services.
Then we can use Honeycomb for a deep-dive analysis of this information.
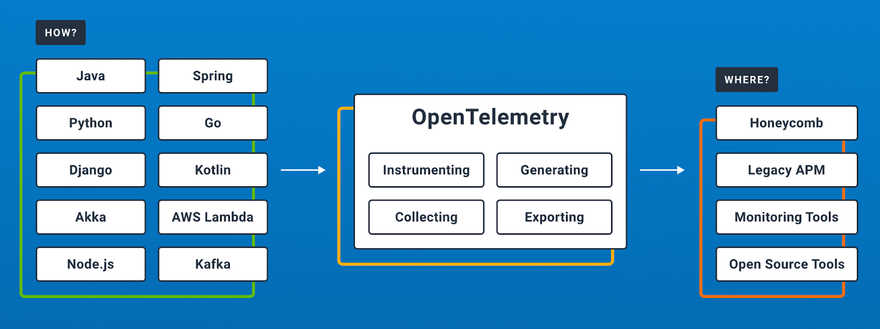
Unlike Datadog (which we use at Lob quite a bit), you don't need to know what axis you want to analyze in advance. (Anybody who spends enough time with Datadog knows that if you wanted to, for example, search aggregate information by a given data set, you better have known that already and have created a facet for it; if you haven't, you're not going to be able to get an accurate read off of it.) You can aggregate on any dimension at any time you want, which is fantastic for analysis.
Sevoria noted two other benefits of exploring Honeycomb for data analysis:
using industry-standard typically results in less technical debt (in form of a really tightly coupled adherence to a specific vendor's implementation), and
Honeycomb has a very transparent and easy-to-understand pricing model.
Simplifying local development
In addition to hops along the way to delivery, during creation, each mailpiece takes a trip through a network of distributed services. This means Lob services are difficult to stitch together when developing locally. We've historically called staging instances from our local environments to simulate the production behavior. Unfortunately, this process breaks down when the interaction is asynchronous or when multiple services need to be updated simultaneously.
This problem was introduced with ominous music and masterful editing. Remember the scene from “Saw” when Jigsaw says there is only one key? Masterful editing had Jigsaw following up with, “to find the key, you must integrate services in Docker.”

The team identified three reasons why it’s so difficult to integrate in Docker: differences in naming conventions, port bindings, and overlapping resources. Lob uses AWS so we communicate with each other through queues. This can get quite complex, (previously queue messages are problematic for example), but the team uncovered a way to simplify it.
They proposed standardizing starting conventions, staggering our ports, and sticking with one version (or one running container) for joint resources like one AWS stack and Redis. Before vs. After:
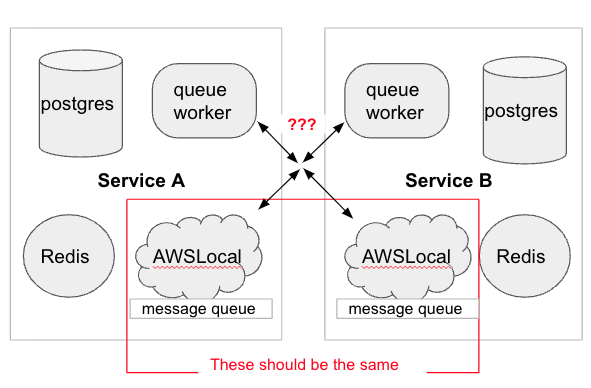
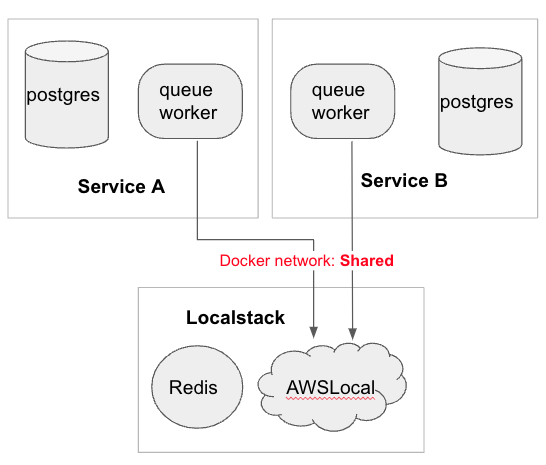
Each service can be started separately via a new startup script. This ensures shared localstack resources are started, adds the queues/buckets, etc., to the shared AWS localstack that is needed, and starts up only needed services in the Docker network: shared. Port binding conflicts can be avoided by referring to the new (very high-tech) shared Google spreadsheet.
This has the potential to standardize how Lob’s apps communicate with each other. This aligns with similar initiatives within Lob architecture and a continued push towards operating as a unit or as a whole ecosystem, not just individual teams.
Major kudos to Staff Software Engineers Krys Flores, Ken Pflum, and Adrian Fallerio, Senior Software Engineer David Nutting, and Software Engineer Nick Perri—their efforts resulted in a tie for second place.
GitHub productivity hack
Easily winning the best costume award was Senior Software Engineer, David Nutting, for his “Lob” Zombie getup.

Nutting kicked off our presentations with a GitHub productivity hack. He outlined the frustrating and time-consuming scenario where you are waiting on your code to be approved, then manually executing a merge, only to be served with the “This branch is out-of-date with the base branch” message (sometimes not just once, but twice).
As it turns out, automatically merging a pull request is a feature that's built right into GitHub. To turn it on, you just have to open up the repo settings and check two boxes. That's it!

Though not a feature of GitHub proper, there are also Github Actions that will essentially press that “Update branch” button for you. So when any other merge happens to main, a "push" event will trigger some code to tickle your branch and pull new changes. (If you are concerned about future conflicts, you can set up as many notifications as you want in GitHub.)
While better for some use cases than others, this certainly is a time-saver.
Changing of the guard
Karmbir (KC) Chima was on-call for a portion of the hackathon; this ended up being the inspiration for his project. He too was interested in saving time. At the end of each on-call shift, the primary engineer—or “goalie”—is responsible for a comprehensive handoff. This involves documenting all issues (resolved and ongoing) and other detail; essentially duplicating all the info captured in the tickets. But let’s be honest, at the end of two weeks, not everyone has the time/energy/memory to do this at a high level. Realizing that Notion can natively sync with Jira, the solution was obvious: Add an “on-call” label to the request form (a Slack Workflow that creates a Jira ticket); this automatically syncs into the Notion document, eliminating the need for recall and duplicate data entry.

Run, Dora, run
Staff Engineer Guy Argo also had efficiency on the brain. Lob’s address verification software, affectionately named “Dora,” is CASS-certified, which is a huge benefit to our customers, but does require quite a bit of work to maintain. For the latest round of certification, we have about 150,000 tests to run.

To get things running a bit quicker, he persisted all the data for the tests in the database but was still looking to shortcut the endless send/retrieve in Elasticsearch. So why not Redis? 20 lines of code and 1 cached index later, he saw a 20% improvement in runtime on the large test dataset—a perfect productivity hack! Correr, Dora, Correr!
Show me what you’re working with
The Partner Management & Tools engineering team has the unofficial mission to make life easier for Lob’s partners and our internal Partner Operations group; both have expressed the need for greater inventory visibility. Together the team built two new UIs that allow visibility of inventory by partner, and inventory change by day. Previously only available in Datadog; this information is now displayed in an easy-to-digest way; areas of concern can be quickly identified, as well as trends.
This was a huge win for both our partners and Lob, and for their efforts, the team took home the gold ribbon. Congratulations to Engineering Managers Adam Stodgill and Andrew Jorczak, Senior Software Engineers Martin Han, Tim Bright, and Zac Leids, and Software Engineers James Cho and Jessica Ho.
Filter what you’re working with
Up next, to make a case for “there's no small PRs, only small teams” was solo artist Staff Software Engineer, Landon Barnickle. Our Partner Ops team has also expressed a pain point around filtering. To make their lives easier, Landon added an admin route for managing filtered partners using a wrapper for our Redis cache, or as he put it: List, Add, Remove, WIN! He reminded our engineers of the importance of working closely with the end users; often little changes can make a big impact.
See the future, I can
Our Routing and Delivery engineering team (more commonly known by the awesome acronym RAD) also supports our partners. For example, we currently have a tool for our team to create dynamic rulesets around routing to our print partners. To use a very simple example, let’s say we wanted to route all mailpieces from a customer to a specific print partner. Using GitHub Actions, our team can create this rule quickly and easily—but they do so in production.

The downside of such agility is we don't have a good way of predicting the effect of any given change. Should the print partner in the above example be at capacity, or if there is a conflict with another ruleset (more common), we must make another adjustment.
Ken Pflum, Staff Engineer, developed a way to allow us to A/B test; in short, we can now work off a particular branch to test rule sets, then merge that branch into main. This predictive ability reduces risk and still allows us to adapt quickly.
A picture is worth a thousand words
Visibility was a common theme in this year’s hackathon. Lob sends millions upon millions of mailpieces each year which results in a lot of data. For those within the company, there's no easy way to digest that data. Looker dashboards have limitations and even those with SQL chops may run into difficulties writing queries.

Engineers on the RAD team aimed to provide a couple of visualizations depicting mail volume and our routing approach. Why visualizations? They are easier to digest and more descriptive than code and they help surface patterns and anomalies.
Sample data was used to showcase mail density over the last month across the US:
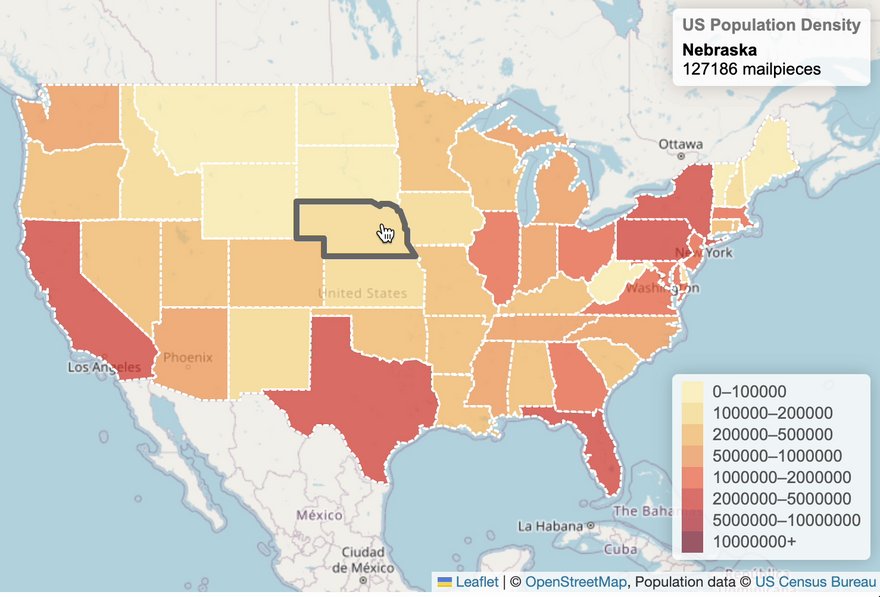
Using data from a sample postcard campaign, they also presented a simulation of what a routing profile could look like on the US map. It follows the campaign getting routed through Lob: The bigger bubbles represent Lob’s print partner facilities and the smaller bubbles represent the USPS facilities; the links showcase the USPS facilities where our partners sent our mail.
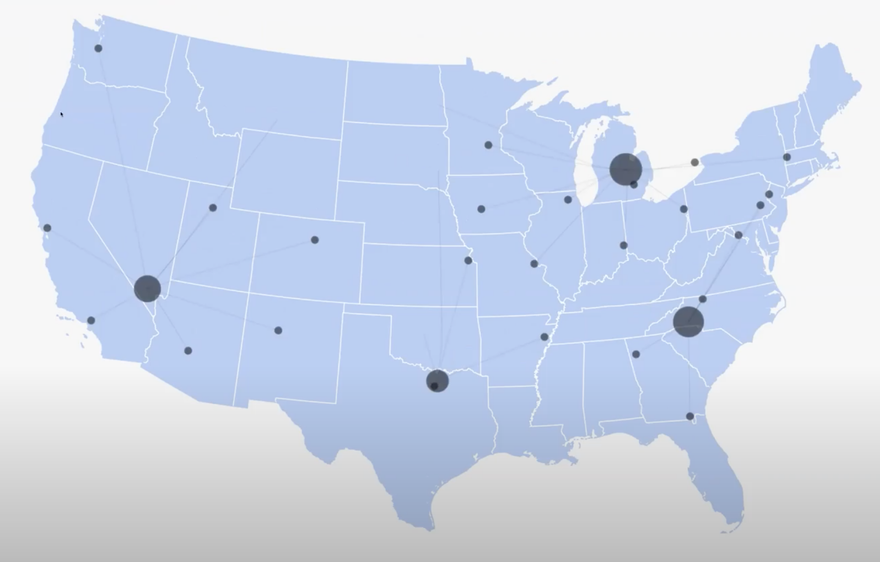
Props to Senior Software Engineer Sachin Muralidhara and Software Engineer Joseph Villanueva, with nods to Staff Software Engineer Landon Branickle and Engineering Manager Adam Stodgill. The team at large is excited to build on this work.
The coolest traffic cop
In another effort to standardize development and operations, Lob has just wrapped up our container orchestration migration from Convox to HashiCorp’s Nomad, led by Senior Platform Engineer Elijah Voigt. In this new ecosystem, one feature available to us is Consul Service Mesh (a feature of Consul, which is part of our Lob Nomad stack).
With Consul Service Mesh, we can have each of our services declare what their dependencies are, and enforce only traffic from those services. So you can tell your container orchestrator: this service should only accept traffic from this other service, and anything else should be blocked (and that service is encrypted). As we scale up, this offers us the same zero trust security much larger enterprises typically employ.

In addition to setting us up for a better security posture, Service Mesh also provides a greater understanding of how our services work together. Topologies allow you to quickly identify dependencies and interactions, and details are available for a deep dive.
A journey of a thousand miles starts with a single step
Senior Director, of Strategic Business Development, Tyler Dorenburg, and Senior Product Manager, Andrew Reagan are passionate about bringing new functionality to our customers. Working closely with our engineering team they continue to drive innovation.
Informed Delivery by USPS is a free daily digest email with digital scans of each mailpiece you will receive each day. Additionally, mailers can add a clickable advertisement underneath each mailpiece scan.

As of September 1st, USPS adjusted the requirements making it possible for Lob to support this functionality for our customers and their mail campaigns in the near future! The technical details of how we plan to implement this are both mindboggling and proprietary so we won’t share that here, but Staff Software Engineer, Landon Barnickle, and Software Engineer, Gage Guzman, used the hackathon as an opportunity to dive into some of the prework (like digesting a 92-page PDF with XML specs—sounds terrifying!).
Go big or go home
Arguably the most frightening moment of the hackathon demos was when Senior Infrastructure Engineer, James Douglas, showed the group our AWS bill. Ek! We are storing over 5 petabytes of data in the form of billions of objects. Our tables have grown so big that we're timing out on a lot of queries.
We developed a service called “Expunge” which deletes expired data on an ongoing basis but has a hard time working through our current backlog. It’s like using a lawn mower when a feller buncher is what’s needed. (You are not alone if you had to look up “petabyte” and/or “feller buncher.”)
True to the Lob value Be Bold, James went in search of the tsar bomba, that is, a one-time big-bang approach to clear all the old data.

He initially explored Amazon S3 Lifecycle which is a built-in wipe but came across a number of limitations.
For example, why not just delete everything that's X days old, right? Wrong. There are special circumstances where we want/need to keep data for longer.
What if we tagged them, then have S3 delete the rest? Wrong again; turns out you cannot exclude a tag in the filters.
Move them to a different storage class? Nope. Can't target only a storage class.
How about we evacuate the files, then copy them back in so it updates the date (to fall within the “keep” period)? Nope. Innocent bystanders would be caught in the slaughter, like templates, which are timeless.
Alas, the tsar bomba approach would be too indiscriminate. Since the goal is to target each S3 individually, James landed on the following instead:
He attacked the database first by carefully moving everything that qualifies for deletion into a new table and indexing it; this took about 19 hours. From there, you can use Expunge’s core functionality to attack this new table to delete resources. Testing proved this process would take mere minutes; minutes that will save us major moola. This is a huge win for Lob.
With S3, an ounce of prevention is worth a pound of cure" —Douglas.
Stripe Upgrade
Proactive upgrades are also worth their weight in gold. Software Engineers Sage Farrenholz and Patrick Thulen on our Billing team tackled an upgrade to Stripe, the system we use to automate and process payments. True to theme, Sage noted our legacy Stripe integration was pretty “scary”: we were using an older version, and we wanted to move from Charges API to the newer Payment Intents.
The work was fairly straightforward: They bumped Stripe (Node) Client package to 10.15.0, bumped Stripe API to the latest version 2022-10-0, and moved over to Payment Intents, but this involved multiple breaking changes and an awful lot of testing.
While not the sexiest of projects (although an accidental dropping of the “e” from “Stripe” on one of the presentation slides would suggest otherwise), this brings tremendous value to our Lob and our customers.
Wrap Up
After 48+ hours of non-stop hacking, our Lobsters looked a little more like ghouls. That said, each and every participant, and all those who got to witness the final presentations, had smiles on their faces when all was said and done. Hopefully, they were sincere…
“No matter the situation, always wear a smile.” –The Joker

Want more?
We love a good theme; read more about our spring hackathon, inspired by a favorite 80's movie: Hack to the Future.



Top comments (1)
Hackathons are collaborative tech events where developers rapidly prototype and innovate solutions — often strengthening skills like problem‑solving, teamwork, and creativity — and many successful tools have emerged from them.⁴⁁(turn0search22) Lob’s Halloween Hackathon update on modernizing the sqs‑consumer library to support the latest AWS SQS (Amazon Simple Queue Service, a managed message‑queuing service that helps decouple distributed systems) shows how internal challenges can turn into community‑beneficial improvements.⁴⁁(turn0search0)(turn0search1) It’s inspiring to see such innovation because reliable tech foundations matter not just in software but also in real‑world experiences like Shopping & Reliable Parcel Delivery where dependable systems keep everything running smoothly for customers.”