
TLDR
Virtual machines and containers have improved backends in a lot of ways, but over time they have also created a lot of problems. We believe it's time to rethink how we use virtualization for backend development.We're building a backend framework that shifts the scope of virtualization from processes down to service components.
In web applications nowadays, you can sort any component somewhere in a broad spectrum from client-side to server-side.
On the client-side, there's everything that runs on people's devices, most likely a browser or an app. On the server-side, there's everything that runs in the cloud. That includes databases, authentication management, batch jobs, events handling etc.
Each web framework squarely fits somewhere on that line. React, the most popular front-end web framework out there, is wholly client-side. Express, one of the most popular backend web frameworks, is wholly server-side.
Client-side has been historically dominated by JavaScript frameworks. This is not surprising since every client ships a powerful JavaScript engine and that is the best way to make a web page interactive.
On the server-side, things are more fragmented. This is also not surprising: backend services are just plain native processes that use their environment's network stack to respond to requests. And there is a world of different ways to write and run these: literally the history of computing.
As in many other scenarios in software engineering and computer science, this huge free space of options is also the cause of a lot of problems. To understand why, we need to talk about containers.
Containers are a solution and a problem
On its way to settling in its standards, the cloud - epitomized by AWS - has evolved massively over the past decade. My co-founder has written a post on this previously.
Today we, as software engineers, deal with it as it is: the result of incremental changes on top of a status quo. And it is not ideal.
What starts life as physical machines in a data center gets split up into tens, sometimes hundreds, of virtual machines in the AWS console. But VMs are heavy, slow to start and it's difficult to make a lot of them coexist without wasting resources like RAM and storage.
Then came along containers. Building on top of the Linux kernel's namespacing features, they made images smaller and runtimes more efficient than VMs. The genius of it is to move the virtualization layer from the hardware - where the kernel itself runs virtualized - to the software - where only processes run "virtualized". With containers, virtualized processes run natively in the host kernel, like any other. Except that their I/Os are carefully kept segregated from others in the host system. Any bit of compiled code that is executable on the host can be run in a container. And you can run processes in a container without a separate boot sequence and a full-fledged virtualized operating system with its own heavy machinery like a scheduler and dedicated virtualized hardware.
Containers are actually much older than a lot of people realise, going as far as 2008 with LXC in Linux’s case (even more in the case of FreeBSD). Their popularity, however, really took off with the arrival of Docker. The execution of Docker as a platform-as-a-service product was so good it took over software engineering practices for the following decade. And it is still the gold standard today in terms of usage.
Of course, companies were quick to build products on top of containers. They basically pass through the benefits of containers to their paying customers. Heroku is one of the most notable example. And while containers delivered most of us, directly or indirectly, from having to deal with VMs as a unit of deployment, they certainly have their issues. The biggest one being their size.
VMs have to run an entire operating system, containers don't. So they're quite a lot smaller. But container images still have to contain enough userspace to make the things you want to run actually runnable. For the way most people use them in deployments of web apps, this is generally still quite a lot!
The heavier your containers are, the more difficult everything else becomes. They take longer to build, they need more resources to run, they are more expensive to store, etc.
At shuttle we're convinced that a lot of the pains experienced by software engineers in the post-Docker world can be traced back to that very simple statement: containers are often too heavy for the job.
Replacing containers
You're probably thinking: it's nice and optimistic to say containers are too heavy, but what do you replace them with?
Well first, as an open-source company, you avoid making the same mistake Docker made. If you make the scope of virtualization too broad, you will end up with the same result as containers. The root cause behind the heavy weight of containers is that they have been built for too many usecases. They layer virtualization on top of all the I/Os of a native Linux process: their usecase is just about anything that runs.
We’re concerned with the backend services most people write. These are HTTP request/response handlers, with or without state. And for that specific usecase, most projects just end up worse off by handing over backend services as container images to their deployment platform of choice.
So we need to restrict the scope of virtualization to something more specific to web app backends. This is a trade-off of course, like most things in software engineering. By restricting the scope of a tool, you lose the ability to do certain things. But like most of these trade-offs, you usually are better served by erring on the side of simplicity unless you have specific needs that require extra complexity. In other words: use heavy machinery when you actually have a need for it, not before.
Where does that leave us then? We need a new take on virtualization. One that has, perhaps, simplified I/Os and is engineered for backend services. Thankfully, we don't have to invent most of that wheel: let's talk about WASI.
WASM and WASI
If WASM+WASI existed in 2008, we wouldn't have needed to created Docker. That's how important it is. Webassembly on the server is the future of computing. A standardized system interface was the missing link. Let's hope WASI is up to the task! https://t.co/wnXQg4kwa4
— Solomon Hykes (@solomonstre) March 27, 2019
WebAssembly (abbreviated WASM) is an instruction set for extremely lightweight virtual machines. Its most common use is to speed up client-side interactivity. This is made possible as popular browsers have rolled out WASM runtimes a few years back.
WASM is made for fast sandboxing. However, without any extension, it is unable to perform even simple I/O operations like reading data from a file descriptor. This is not a big deal if WASM is used in the browser - we definitely don't want to let browsers freely provide file system access to web apps. But it is a serious limitation if WASM is to be used server-side - how else are you going to serve endpoints without that?
Therefore, the introduction of WASM was followed, a short while later, by WASI - the WebAssembly System Interface. WASI is a standard API to give WASM code the ability to do system-level I/O. This allows WASM code running in a WASI-compliant runtime to do a lot of what a native process can do through syscalls.
The really powerful thing about WASM is that it is a very common compilation target. Major languages (and commonly associated frameworks) now support building WASM as a target, just the same way you build for amd64 or arm. And a lot of standard libraries have added support for WASI-based I/Os.
This is what Docker's founder had to say about WASI, back in 2019. And we agree with them. At the end of the day containers are, really, just I/O-level virtualization. Now, a few years after its initial introduction, WASM runtimes have stabilised their support of WASI. This creates a prime environment to engineer, on top of WASI, a solution to containers' biggest drawbacks.
Changing virtualization for backends

When we launched shuttle for its early alpha, back in March 2022, our purpose was to address the issues people face when building and deploying web app backends. So we created an open-source infrastructure-from-code platform with which you don’t need to write Containerfiles and orchestrate images, starting with support for Rust.
Since then, more than 1.2k people starred the shuttle repo and hundreds joined our discord community. And we've seen more than 2000 deployments and hundreds of users! From which we received a ton of feedback.
What we quickly realized is that while we simplified the process of getting started implementing your own backend and setting up its infrastructure, we completely failed to solve two core problems: long build and deploy times.
Rust has notoriously long build times (this probably has to do with static linking and heavy reliance on compile-time code generation). And while it supports incremental compilation out of the box, in a containerized environment, missing the cache for an image layer means having to rebuild from scratch.
We've found that no matter how much we tweaked our internal caching, too often users had to wait too long for their projects to build and deploy - something that can take minutes in the simplest projects, and closer to half an hour in complex ones. The reason was simple: our execution of our idea for shuttle is built on top of containers. And no matter how much we try to distance containers from our users, their limitations always surface back.
It was time for a complete rethink, so we took a radical view: let's start from the services people are writing, distilling what they need done quickly and easily. And let's make it our mission to optimize the hell out of the entire stack. We thought that if the execution of that idea is done right, it'd let us trim the dependency tree of services our users deploy and slim the runtime that every service ships with.
What we quickly realized is that while we trimmed down the process of getting started implementing your own backend and setting up its infrastructure, we completely failed to solve two core problems: long build and deploy times.
After all, a major culprit of these long build and deploy times in the real world is the large number of heavy dependencies of even simple projects. There's not much you can do about this: most services have a pretty big runtime that includes heavy machinery like an asynchronous executor (e.g. tokio), a web server (e.g. hyper), database drivers (e.g. sqlx) and more. And on every deploy you need to re-build them and hope artifact caches are hit in order to get an incremental build. And it's not just building either, the running time of tests is also impacted by this. The closure of the codebase you're engaging in those tests is very large indeed as it follows that of your dependencies.
This stuff materializes itself everywhere. Just try taking this hello world snippet:
use axum::{Router, routing::get};
async fn get_hello() -> &'static str {
"You're slow, Heroku!"
}
#[tokio::main]
async fn main() {
let port = std::env::var("PORT").unwrap();
let router = Router::new()
.route("/", get(get_hello))
.into_make_service();
hyper::Server::bind(&format!("127.0.0.1:{port}").parse().unwrap())
.serve(router)
.await
.unwrap();
}
and deploy it to Heroku:

To try to address this, we wanted to move all these heavy dependencies to a common runtime across services. So your tokio, hyper, sqlx and co (in the case of Rust), now all belong to a long-lived containerized process running persistently in the cloud. Whereas all your service logic, database and endpoint code build into lightweight WASM modules that are dynamically loaded in-place by this global persistent process. That way "building" means compiling a very lightweight codebase with a small dependency footprint. And "deploying" means calling upon the control plane of that long-lived process to replace service components without rolling out new images, containers or VMs.
This leaves us with a trimmed down user-facing API that still uses familiar objects like PgClients and axum-style routes with guards:
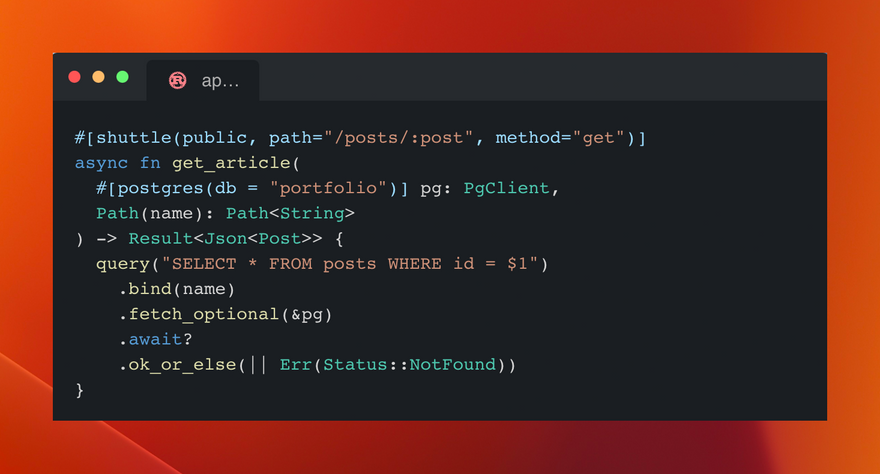
Except that now the virtualization platform in which your services are run is responsible for instantiating these objects and calling these functions.
With this approach, the component of virtualization that you end up deploying on a daily basis is much smaller than traditional VMs and containers. In a way we can say this makes the virtualization layer more adapted to the specific needs of backend services running in the cloud. It's an optimized I/O surface between backend service components that change a lot (e.g. endpoint implementations) and their environing long-lived runtimes that don't (e.g. tokio/hyper/sqlx).
This results in "images" that are effectively up to 100x smaller because of the switch from container images to WASM binaries. And super fast to deploy too, from tens of minutes sometimes to less than a second all the time. All because when things are really incremental, you don't have to build and test a large codebase with its large userspace dependencies on every push. You just need to build and test the code you're writing and the changes you've made.

Our vision for this new way of doing backend development is shuttle-next: a next-generation backend framework with the fastest build, test and deployment times ever.
We believe that scoping down virtualization to the level of service components will eventually become the norm for backend development. In the same way we all think it's often not best to setup and start a VM only to run a single process, we will eventually all think it's misguided to build and start a container only to run a single service.
We are launching shuttle-next as part of our closed beta for shuttle later this month, with the public release coming soon after. If you’re keen to give it a try early, sign up for the beta! We'd love to know what you think!
In the meantime, check out shuttle's GitHub repo and Twitter for updates. If you’d like to support us, please star the repo and/or join the shuttle Discord community!

Top comments (1)
Virtualization is changing the way we build and run servers. It helps save space and makes systems more flexible. It's time to rethink how we use it for better, faster performance.