The event-driven architecture pattern is a popular asynchronous architecture pattern which pushes information as events happen. It is a way of building systems that enable information flow between chained services in a real-time manner as events occur.
Event-driven architecture as the name implies, is a way to load balance and filter data from a large number of events from which insights or actions are then derived. A good example is the deluge of events that are received from every single platform all the time–whether it’s social media or just your average run of the mill dev tool–many times you’ll see these alerts batched together into ‘X people liked your post’. This post will describe why and how this is done.
A Typical Event Load Story
Let’s take another, more technical example of IP filtering. A common scenario is when, for security purposes, a company’s CISO will request that you start monitoring and filtering traffic based on the reliability and safety of IP addresses. You usually start by creating filtering logic such as IsDangerousIP on all incoming traffic. This quickly begins failing when running this heavy and resource intensive process on each packet that comes through the router doesn’t scale, particularly when you have enormous amounts of traffic coming through all the time. This breaks down because It is impossible to run this logic on this packet mass.
What quickly becomes obvious though, is that many of the IP addresses are actually the same, oftentimes due to ongoing sessions between entities, and this is actually a huge waste of resources––running the same complicated heavy logic over and over again.
This is when a load balancing solution needs to be implemented.
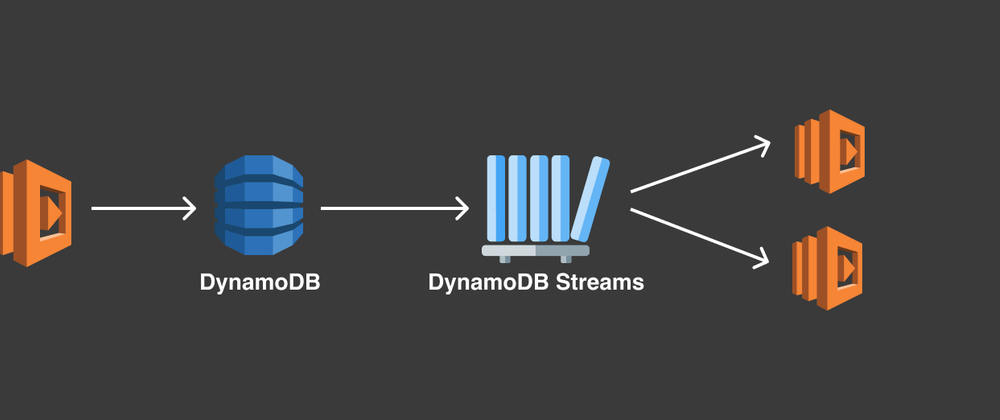
We encountered a similar breakdown in our event filtering due to a huge amount of data streaming in, and also needed to find a solution to handle the load. As our serverless architecture is built upon DynamoDB as our primary data store, we decided to research whether there could possibly be a cloud service that could do the heavy lifting for us, and learned about DynamoDB Streams. In this post, we’ll describe how it works, and provide a real code example for you to do it yourselves. (You can try this at home!)
Event-Driven Architecture in Cloud Operations
In order for Firefly to be able to analyze user behavior and provide insights to clients regarding anomalies in their cloud systems such as drift & unmanaged resources, many similar events need to be parsed so that relevant insights can then be extracted based upon this data. Therefore, it was quickly understood that similar events would need to be aggregated into batch notifications to ensure our users aren’t overwhelmed by too much information.
Similar to the IP filtering example, with Firefly, many of these alerts are not unique or important to consume individually, and we understood we would need to aggregate similar events together, for both cost effectiveness and resource utilization.
We understood that if we were to build such a transactional microservices event aggregation mechanism ourselves, these are the elements we would need to design and implement ourselves:
- Deduplication of events in the same scope. Duplicate events on the same time slot can cause throttling of services and ultimately will be very costly
- Managing and holding the state. The state of the component that defines the notification order would require multiple writers, meaning it would also need to be safe for multiple writers
- Filtering. Of records that represent an event scope and not as standalone repetitive events - requires the filtering/deduplication of events in the timeslot With DynamoDB Streams this is built-in out of the box, and it’s just a matter of writing the lambda functions to handle the logic. This is what it looks like in action.
Dynamo Streams for Event-Driven Lambda
DynamoDB Streams are basically a time-ordered flow of information about item-level modifications in a DynamoDB table. This means, whenever items are created, updated or deleted in a table, DynamoDB Streams write a stream record with the primary key attributes of the modified items. So if we take the example of the incoming traffic filtering, DynamoDB Streams is an excellent candidate for this task.
Below we’ll walk you through how to build a solution for IP filtering, based on specific logic, without bogging down your system resources.
To get started you need to be able to quickly aggregate and analyze the incoming packet IP addresses. We do this by upserting each as an item into a DynamoDB table, in order to collect all unique IP addresses coming from packets in a specific period of time. That’s the easy part, this is basically using DynamoDB in its typical fashion.
This is where it gets fun. Next, in order to get all of the distinct IPs in a fixed period of time, we can now, through DynamoDB Streams, easily forward these to a designated lambda function that will run our IsDangerousIP logic and alert upon any anomalous IPs, as needed. With DynamoDB streams it is possible to quickly build a transactional microservices event aggregation mechanism where every IP address is processed once, efficiently, and durably.
In order to implement the IP filtering solution described above, we’ll need to create a stream that essentially comprises a Change Data Capture of every create action being performed on the DynamoDB table items, although the same logic can be applied to any action such as delete or update, as well. This means that with each action taken, a record that describes the data modification is written to the stream. The stream is highly configurable, filtering the event data or adding information such as the "before" and "after" images of modified items is also possible and can be useful when you want to implement a smart update based on different attributes.
This stream enables us to build applications that consume these events and take action based on the contents.
Build the IaC with Terraform!
When it comes to IP filtering, we first need to start with properly configuring the infrastructure, This code example, will save all the events waiting to be checked in the next stream to the DynamoDB Table:
resource "aws_dynamodb_table" "accumulator_table" {
name = "EventsAccumulator”
billing_mode = "PROVISIONED"
read_capacity = 200
write_capacity = 20
hash_key = "IPAddress"
range_key = "IPAddress"
stream_enabled = true
stream_view_type = "NEW_IMAGE"
attribute {
name = "IPAddress"
type = "S"
}
}
Now we will build the lambda function that is responsible for detecting every dangerous IP address:
resource "aws_lambda_function" "detector" {
function_name = "dangerous-ips-detector"
role = aws_iam_role.iam_for_lambda.arn
handler = "main"
filename = "lambda_function.zip"
source_code_hash = filebase64sha256("lambda_function_payload.zip")
runtime = "go1.x"
}
IMPORTANT: The most critical piece when configuring the lambda event source mapping, is to limit the function to only extract from the DynamoDB table the INSERT event, and not other events that may come in, such as UPDATE events. This will ensure the function only retrieves the distinct list of IP with events that occurred in the fixed period of time:
resource "aws_lambda_event_source_mapping" "aws_event_streamer_trigger" {
event_source_arn = aws_dynamodb_table.accumulator_table.stream_arn
function_name = aws_lambda_function.detector.arn
batch_size = var.batch_size
maximum_batching_window_in_seconds = var.batching_window_in_seconds
starting_position = "LATEST"
filter_criteria {
filter {
pattern = jsonencode({
"eventName": [ "INSERT" ]
})
}
}
}
Now, let’s take a minute to look at some of the interesting arguments we can create within these:
batch_size - Enables us to define the largest number of records the Lambda will retrieve from the event source at the time of invocation.
- This protects your systems from throttling the lambda function at peak times.
Maximum_batching_window_in_seconds - This defines, in seconds, the maximum window of time to gather records before invoking the function. Records will continue streaming in until either the maximum_batching_window_in_seconds expires or the batch_size has been met.
- This allows you to dynamically configure the period of time to accumulate IP addresses until handling them.
Filter_criteria - This defines the criteria to use upon the event filtering event sources. If an event satisfies at least one filter, the lambda will send the event to the function or add it to the next batch. This is a powerful tool that supports creating complex pattern rules and customized streams for every use case. Learn more about this cool functionality here: DynamoDB Streams Filter Criteria.
Show me the Code
For every incoming packet we upsert the IP address into the DynamoDB table:
key := map[string]*dynamodb.AttributeValue{
"IPAddress": {
S: aws.String(CURRENT_IP_ADDRESS),
},
}
output, err := dynamoService.UpdateItem(&dynamodb.UpdateItemInput{
Key: key,
TableName: aws.String("EventsAccumulator"),
})
The detector lambda consumes events from the DynamoDB stream. Every item is deleted after processing, in order for it to be retrieved in the next batch as an INSERT event:
func main() {
lambda.Start(handler)
}
func handler(ctx context.Context, e events.DynamoDBEvent) {
for output, record := range e.Records {
IPAddress := record.Change.NewImage["IPAddress"].String()
ISDangerous = IsDangerousIP(item)
if ISDangerous != nil {
alert(IPAddress)
}
key := map[string]*dynamodb.AttributeValue{
"IPAddress": {
S: aws.String(IPAddress),
},
}
_, err := dynamoService.DeleteItem(&dynamodb.DeleteItemInput{
Key: key,
TableName: aws.String(tableName),
})
}
}
DynamoDB Streams makes it extremely easy to build transactional microservices with serverless architecture, something that was formerly a complex undertaking with a lot of backend logic to fulfill.
Transactional Microservices & Reducing Alert Fatigue
When building an event-driven platform that requires big data in order to provide precise information, but still has the requirement of remaining useful and not overwhelming, event aggregation is a good practice to reduce alert fatigue, not consume too many resources, and be cost effective. By providing users aggregated data, they can still benefit from near real-time data, without the downside of having to filter and sift through too much information to understand what is actually happening in their system.
With the growing scale of cloud operations today, our tools need to work for us, and not the other way around. We also understood in the same vein, that cloud services have evolved immensely, and many big data companies suffer from the same pains - and perhaps we don’t have to reinvent the wheel. By leveraging an existing cloud service we were able to automate much of the heavy lifting and focus only on the business logic and customer experience. We hope you found this example useful if you have a similar tech stack.

Top comments (1)
Welcome to The Ops Community, @galco and the Firefly team! Thanks for kicking things off with such a detailed post.
It's so great to see you've already set up your organization page and started posting to it! Let me know if there's anything I can help y'all with as you start to share more of this content 😊