The architecture conundrum
As software engineers, most of us have gone through the phase where we decide on an architectural pattern for our codebase. The intention behind this is not only to avoid making any obvious mistake – like ending up with a big ball of mud, but also to sleep better at nights by ensuring that we still remember what our code does after a month. Additionally, having an architectural pattern for the code provides guidelines by implicitly dictating what goes where, thereby making knowledge transitions easier.
Pick a winner
We were in a similar situation when we had to choose a pattern for our application. Deciding on it was especially challenging for us as our architecture did not follow the norm of being REST driven. With REST, the craft of pick-and-choose becomes a tad bit easier as most of the systems unintentionally fall under the layered-architecture bucket.
In our case, we have an event-driven system where we use GraphQl for data interaction and Kafka to move, transform and enrich data across our microservices. The tech stack consists of Avro Schema files, Spring Kafka and Kotlin, AWS being our cloud provider.
Initially, we considered onion architecture, however the layers didn't seem to work for us. A couple of spikes later, we had a winner as we found that in terms of testability and isolation, hexagonal ticked all the checkboxes that we needed.
Give it a whirl
Now, after deciding that we did want to go with hexagonal, the task at hand was to transform our small ball of mud into the hexagon shown below. We had to figure out what conforms to a port or an adapter and what would reside in the hexagon in Kafka world.
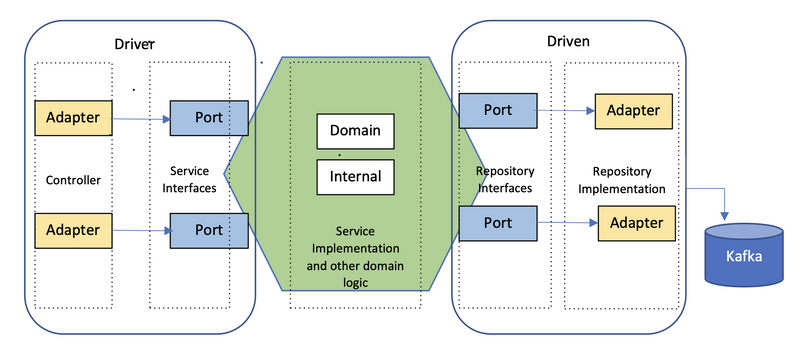
Based on these videos and a couple of other helpful articles, we segregated our code into the following folder structure:
Ports
These represented the blueprint of the domain features and consisted of all the interfaces needed to interact with the core application.
We had driven and a driver folder in here, where driver had interfaces of the services and driven had the interfaces of our repositories.
Adapters
These were used to connect to external components through ports. We again had driven and a driver folder in here.
Driver adapters initiated interactions with the hexagon using Service ports. These could be the controllers, application events or similar triggers.
Driven adapters responded to these interactions by processing logic needed for them and consisted of repository implementations. In our case, reads from the Statestore or inserts to the Kafka topics, streams and ktable creations, etc., contributed to such implementations.
Hexagon
This formed the heart of our architecture as all the domain logic went in here. We moved all our service implementations to this hexagon, together with any other domain-specific logic. This meant that all our data transformation logic needed for Kafka went in here.
Put to the test
Once we were happy with the redesign, it was time to test our new architecture. For this we used ArchUnit, as we wanted to test our packages, interface interactions and unintended dependencies. Few of such test-cases were:
- Check if repository implementations are in adapters
- Check no controllers in adapters can access domain classes
- Check domain classes in hexagon does not access adapters and ports directly
- Check there are no implementations and only interfaces in ports And many more.
Make peace
I felt that it can sometimes get difficult to modularise and segregate (into driven and driver, ports and adapters) all of the streaming logic, as a lot of processing can happen in one single function. So, it all comes down to compromises and conscious decisions that govern the risks of weakening the standard architectural boundaries.
Something that cannot be stressed enough is to always test the architecture, as it could help identify anti-patterns, for example, direct interaction between adapter and hexagon or implementations in port.
To conclude, adopting hexagonal requires extra love from developers as it is not a traditional approach and there will be instances where you will need to focus on tradeoffs. So, adopt it only when your system is complex enough and there is bandwidth available for the learning curve.

Top comments (2)
Včera večer jsem si chtěl jen tak odpočinout po práci a zkusit něco nového online. Náhodou jsem narazil na playjonny, kde mě zaujaly bonusy pro hráče z Česká republika. Rozjel jsem pár kol na ruletě, nejprve pár proher, ale pak přišla výhra, která mě fakt nadchla. Celý večer mě to bavilo a rozhodně se tam chci vrátit.
Some comments may only be visible to logged-in visitors. Sign in to view all comments.