
So, we have an AWS Elastic Kubernetes Service cluster with Authentication mode EKS API and ConfigMap, which we enabled during upgrade of the EKS Terraform module from version 19.21 to 20.0.
Before switching EKS Authentication mode completely to the API, we need to transfer all users and roles to Access Entries of the EKS cluster from aws-auth ConfigMap.
And the idea now is to create a separate Terraform project, let’s call it_”atlas-iam”_, in which we will manage all IAM accesses for the project — both for EKS with Access Entries and Pod Identities, for RDS with IAM database authentication, and perhaps later we will move user management in general here.
I already described the new AWS authentication mechanisms in more detail:
- AWS: EKS Pod Identities — a replacement for IRSA? Simplifying IAM access management
- AWS: Kubernetes and Access Management API, the new authentication in EKS
- AWS: RDS IAM database authentication, EKS Pod Identities, and Terraform
I don’t know how far the scheme described below will work for us in future Production, but in general, I like the idea so far — except for the problem with dynamic names for EKS Pod Identities.
So, let’s see how we can automate access control for IAM Users and IAM Roles to EKS Cluster with EKS Access Entries with Terraform, and how Terraform can create EKS Pod Identities for ServiceAccounts. We won’t talk about adding RDS today, but we will keep it in mind when planning.
Everything described below is rather a draft of how it could be, and most likely some updates will be made in the course of implementation.
EKS Authentication та IAM: the current state
We now have an aws-auth ConfigMap in our EKS cluster with all permissions for AWS:
- IAM Users: common Kubernetes users
- IAM Roles: roles for access to the cluster from GitHub Actions
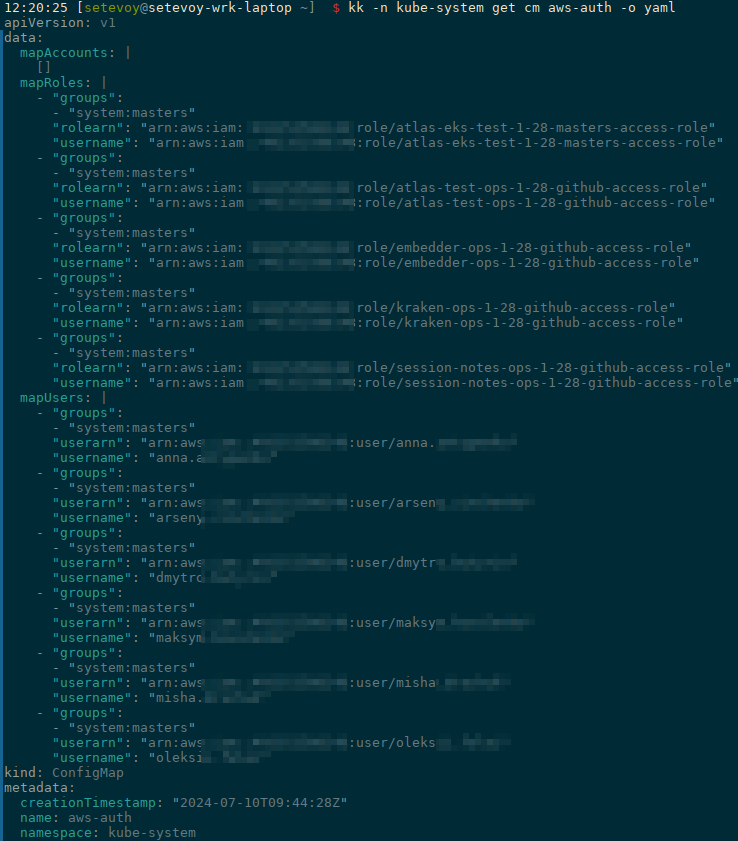
And everybody here is with the system:master privileges, so during the planned upgrade we'll think about how to set more correct permissions here.
Also, now in projects (separate repositories for Backend APIs, monitoring, etc.), IAM Roles and Kubernetes ServiceAccounts are created for the corresponding Kubernetes Pods, and I also want to move from there to this new project and manage from one place with EKS Pod Identity associations.
So now we have two tasks for EKS:
- create EKS Authentication API Access Entries for users and GitHub roles
- create Pod Identity associations for ServiceAccounts
Project planning
The main question here is — at what level will we manage access? At the level of AWS accounts, or at the level of EKS/RDS clusters? And this will determine the code structure and variables.
Option 1: Multiple AWS accounts with one EKS and RDS connections
If we have several AWS accounts, we can manage access at the account level: for each account we can create a variable with a list of EKS clusters, a variable with a list of users/roles, and then create the corresponding resources in cycles.
Then the structure of Terraform files can be as follows:
-
providers.tf: describe the AWS provider with assume_role for the AWS Dev/Staging/Prod account (or use some Terragrunt) -
variables.tf: our variables with default values -
envs/: a catalog with the AWS accounts -
aws-env-dev: AWS account-specific catalog -
dev.tfvars: values for variables with the names of EKS clusters and the list of users in this AWS account -
eks_access_entires.tf: resources for EKS - …
And then in the code, we loop through all the clusters and all the users that are specified in the envs/aws-env-dev/dev.tfvars.
But the question here is how to create users on clusters:
- or have the same users and permissions on all clusters in the account, which is OK if we have an AWS multi-account, and in each AWS-Dev we have only EKS-Dev
- or create several
access_entriesresources - for each cluster separately, and inaccess_entriesin a loop go through the groups of users for a specific cluster - if in AWS-Dev we have some additional EKS clusters in addition to EKS-Dev, where we need to have a separate set of users
In my case, we still have one AWS account with one Kubernetes cluster, but later we will most likely split them and create separate accounts for Ops/Dev/Staging/Prod. Then we will simply add a new environment to the envs/ directory and describe the new EKS cluster(s) there.
Option 2: Multiple EKS and RDS clusters in one AWS account
If you have only one AWS account for all EKS environments, you can manage everything at the cluster level, and then the files structure can be as follows:
-
providers.tf: describe the AWS provider with assume_role for the Main AWS account -
variables.tf: our variables with some default values -
envs/: directory with the names of EKS clusters -
dev/: catalog for EKS Dev -
dev-eks-cluster.tfvars- with a list of EKS Dev users -
dev-rds-backend.tfvars- with a list of RDS Dev users prod/-
prod-eks-cluster.tfvars- with a list of EKS Prod users -
prod-rds-backend.tfvars- with a list of RDS Prod users -
eks_access_entires.tf: resources for EKS - …
You can “wrap” everything in Terraform modules, and then call the modules in loops.
User permissions
In addition, let’s also think about permissions users might need. This is necessary for further planning the structure of variables and for_each loops in resources:
-
devopsgroup: will be cluster admins -
backendgroup: -
editpermissions in all Namespaces containing the "backend" in their names -
read-onlypermissions to some selected naming conventions -
qagroup: -
editpermissions in all Namespaces containing_"qa"_ in their names -
read-onlypermissions to some selected naming conventions
Now that we have an idea of what we need, we can start creating Terraform files and creating variables.
Terraform files structure
We have already developed the same files scheme for Terraform for all our projects, and the new one will look like this — to avoid complications, I decided to go without modules for now, but we’ll see:
$ tree terraform/
terraform/
|-- Makefile
|-- backend.tf
|-- envs
| `-- ops
| `-- atlas-iam.tfvars
|-- iam_eks_access_entires.tf
|-- iam_eks_pod_identities.tf
|-- providers.tf
|-- variables.tf
`-- versions.tf
Here:
- in the Makefile:
terraform init/plan/applycommands - both for calling locally and for CI/CD -
backend.tf: S3 for state files, DynamoDB for state-lock -
envs/ops:tfvarsfiles with lists of clusters and users in this AWS account -
providers.tf: here is theprovider "aws"with default tags and necessary parameters - in my case, the
provider "aws"takes a value of theAWS_PROFILEenvironment variable to determine which account it should connect to, and theAWS_PFOFILEsets the region and the required IAM Role -
variables.tf: variables with default values -
versions.tf: versions of Terraform itself and AWS Provider
And then we can add a file like iam_rds_auth.tf here.
Terraform and EKS Access Management API
Let’s start with the main thing — user access.
To do this, we need:
- there is a user who can belong to one of the groups —
devops,backend,qa - the user needs to have the type of access permissions —
admin,edit,read-only - and grant these permissions either to the entire cluster — for the DevOps team, or to a specific namespace(s) — for
backendandqa
So, there will be two types of resources — aws_eks_access_entry and eks_access_policy_association:
- in
aws_eks_access_entry: describe the EKS Access Entity - IAM User for which we are setting up access and the name of the cluster to which access will be added; the parameters here : cluster nameprincipal-arn- in
eks_access_policy_association: describe the type of access - admin/edit/etc and scope - cluster-wide, or a specific naming space; the parameters here will be: cluster-nameprincipal-arnpolicy-arnaccess-scope
Creating variables
See Terraform: introduction to data types — primitives and complex.
So what variables do we need?
- a list of clusters — here we can simply use the
list()type: - atlas-eks-ops-1–28-cluster
- atlas-eks-test-1–28-cluster
- lists with users, different lists for different groups — can be made with one variable of the
map()type: -
devops: - arn:aws:iam::111222333:user/user-1
- arn:aws:iam::111222333:user/user-2
-
backend: - arn:aws:iam::111222333:user/user-3
- arn:aws:iam::111222333:user/user-4
- a list with EKS Cluster Access Policies — although they are default and are unlikely to be changed, but for the sake of the general template, let’s also make them a separate variable
-
access-scopeforaws_eks_access_policy_association- I tried different options, but eventually, I did it without over-engineering - we can make a variable of themap(object)type: - the
devopsgroup: -
aws_eks_access_policy_associationwill be set with theaccess_scope = cluster - the
backendgroup: - a list of Namespaces where all members of the group will have
editpermissions - a list of Namespaces where all members of the group will have
read-onlypermissions - a
qagroup: - a list of Namespaces where all members of the group will have
editpermissions - a list of Namespaces where all members of the group will have
read-onlypermissions
And then we will create aws_eks_access_policy_association with several resources for each group separately. Will see how to do that bit later.
Let’s go — in the variables.tf file, describe the variables. For now, we'll write all the values in defaults, then put them in tfvars for each environment.
An eks_clusters variable
First, a variable with clusters — for now, there will be one, a test one:
variable "eks_clusters" {
description = "List of EKS clusters to create records"
type = set(string)
default = [
"atlas-eks-test-1-28-cluster"
]
}
An eks_users variable
Add a list of users in three groups:
variable "eks_users" {
description = "IAM Users to be added to EKS with aws_eks_access_entry, one item in the set() per each IAM User"
type = map(list(string))
default = {
devops = [
"arn:aws:iam::492***148:user/arseny"
],
backend = [
"arn:aws:iam::492***148:user/oleksii",
"arn:aws:iam::492***148:user/test-eks-acess-TO-DEL"
],
qa = [
"arn:aws:iam::492***148:user/yehor"
],
}
}
An eks_access_scope variable
A list for aws_eks_access_policy_association and access-scope, it might look like:
- a team name
- a list of namespaces for which
adminpermissions will be granted - a list of namespaces for which
editpermissions will be granted - a list of namespaces for which
read-onlypermissions will be granted
So we can do something like this:
variable "eks_access_scope" {
description = "EKS Namespaces for teams to grant access with aws_eks_access_policy_association"
type = map(object({
namespaces_admin = optional(set(string)),
namespaces_edit = optional(set(string)),
namespaces_read_only = optional(set(string))
}))
default = {
backend = {
namespaces_edit = ["*backend*", "*session-notes*"],
namespaces_read_only = ["*ops*"]
},
qa = {
namespaces_edit = ["*qa*"],
namespaces_read_only = ["*backend*"]
}
}
}
Here:
- the
backendhaseditpermissions to all Namespaces containing_"backend"_ and_"session-notes", andread-onlypermissions to namespaces with _"ops"- for example, access to the "ops-monitoring-ns" namespace, where our Backend team sometimes lists resources - the
qahaseditpermissions on all Namespaces named_"qa"_, and read-only permissions on Backend API Namespaces
And then we will be able to add permissions for each user group in a flexible way.
Please note that we specify optional(set()) in the type, because a user group may not have any group of Namespaces.
An eks_access_policies variable
Lastly, add a list with default policies:
variable "eks_access_policies" {
description = "List of EKS clusters to create records"
type = map(string)
default = {
cluster_admin = "arn:aws:eks::aws:cluster-access-policy/AmazonEKSClusterAdminPolicy",
namespace_admin = "arn:aws:eks::aws:cluster-access-policy/AmazonEKSAdminPolicy",
namespace_edit = "arn:aws:eks::aws:cluster-access-policy/AmazonEKSEditPolicy",
namespace_read_only = "arn:aws:eks::aws:cluster-access-policy/AmazonEKSViewPolicy",
}
}
Creating aws_eks_access_entry
Add the first resource — aws_eks_access_entry.
In order to create an aws_eks_access_entry for each cluster from the eks_clusters list and for each user from each group in one loop, we will create three variables in the locals:
locals {
eks_access_entries_devops = flatten([
for cluster in var.eks_clusters : [
for user_arn in var.eks_users.devops : {
cluster_name = cluster
principal_arn = user_arn
}
]
])
eks_access_entries_backend = flatten([
for cluster in var.eks_clusters : [
for user_arn in var.eks_users.backend : {
cluster_name = cluster
principal_arn = user_arn
}
]
])
eks_access_entries_qa = flatten([
for cluster in var.eks_clusters : [
for user_arn in var.eks_users.qa : {
cluster_name = cluster
principal_arn = user_arn
}
]
])
}
And then we will use them in the resource "aws_eks_access_entry" with for_each, which will form a map() with key=idx and value=entry:
resource "aws_eks_access_entry" "devops" {
for_each = { for idx, entry in local.eks_access_entries_devops : idx => entry }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
}
Here, a list type will be generated in the for_each:
[
{ cluster_name = "atlas-eks-test-1-28-cluster", principal_arn = "arn:aws:iam::492***148:user/arseny" },
{ cluster_name = "atlas-eks-test-1-28-cluster", principal_arn = "arn:aws:iam::492***148:user/another.user" }
]
And similarly, create aws_eks_access_entry resources for the backend group from the local.eks_access_entries_backend and for the qa from the local.eks_access_entries_qa:
...
resource "aws_eks_access_entry" "backend" {
for_each = { for cluser, user in local.eks_access_entries_backend : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
}
resource "aws_eks_access_entry" "qa" {
for_each = { for cluser, user in local.eks_access_entries_qa : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
}
Creating eks_access_policy_association
The next step is to give these users necessary permissions.
For the devops group, it will be cluster-admin, and for the backend, it will be edit in some namespaces and read-only in others - according to the lists of namespaces in namespaces_edit and namespaces_read_only in the eks_access_scope variable.
Just like with the aws_eks_access_entry, we'll make the eks_access_policy_association resources for each user group three separate entities.
I decided not to complicate the code and make it more readable, although I could have added some more locals with flatten() and then do everything in one or two aws_eks_access_policy_association resources with loops.
Here we again use the existing locals - eks_access_entries_devops, eks_access_entries_backend and eks_access_entries_qa from which we take clusters and users, and then set the permissions for each, similarly to how we did for the aws_eks_access_entry.
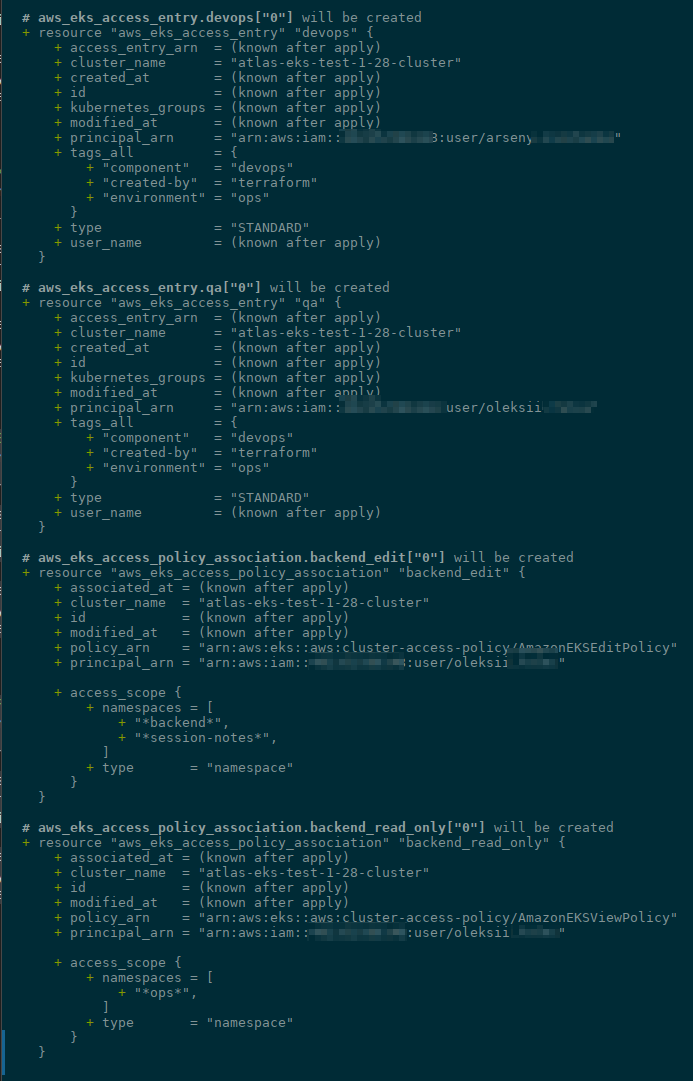
Add the first eks_access_policy_association - for devops, with Policy var.eks_access_policies.cluster_admin and access_scope = cluster:
# DEVOPS CLUSTER ADMIN
resource "aws_eks_access_policy_association" "devops" {
for_each = { for cluser, user in local.eks_access_entries_devops : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
policy_arn = var.eks_access_policies.cluster_admin
access_scope {
type = "cluster"
}
}
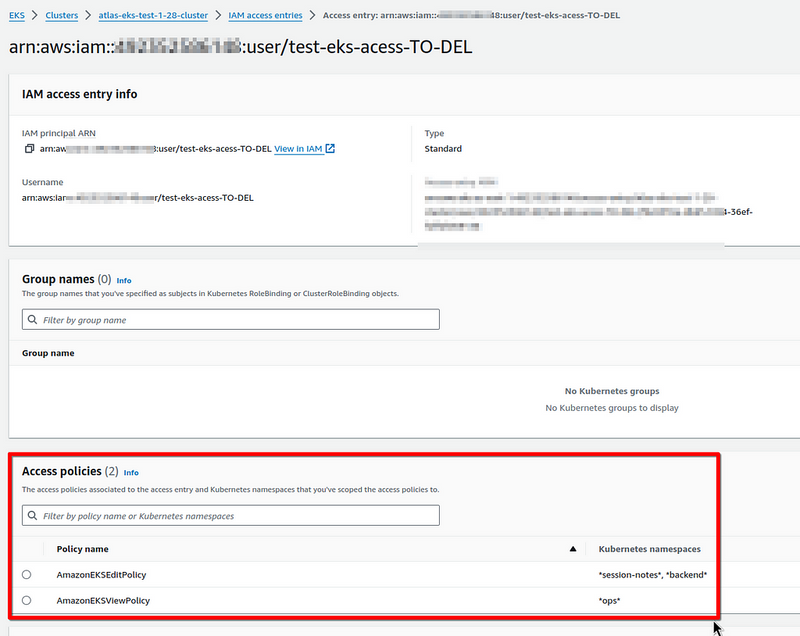
The backend group and edit permissions to namespaces are set in the namespaces_edit list of the eks_access_scope variable for the "backend" group:
# BACKEND EDIT
resource "aws_eks_access_policy_association" "backend_edit" {
for_each = { for cluser, user in local.eks_access_entries_backend : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
policy_arn = var.eks_access_policies.namespace_edit
access_scope {
type = "namespace"
namespaces = var.eks_access_scope["backend"].namespaces_edit
}
}
Similarly for the backend, but with read-only permissions to a group of namespaces from the namespaces_read_only list:
# BACKEND READ ONLY
resource "aws_eks_access_policy_association" "backend_read_only" {
for_each = { for cluser, user in local.eks_access_entries_backend : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
policy_arn = var.eks_access_policies.namespace_read_only
access_scope {
type = "namespace"
namespaces = var.eks_access_scope["backend"].namespaces_read_only
}
}
And the same for the QA:
# QA EDIT
resource "aws_eks_access_policy_association" "qa_edit" {
for_each = { for cluser, user in local.eks_access_entries_qa : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
policy_arn = var.eks_access_policies.namespace_edit
access_scope {
type = "namespace"
namespaces = var.eks_access_scope["qa"].namespaces_edit
}
}
# QA READ ONLY
resource "aws_eks_access_policy_association" "qa_read_only" {
for_each = { for cluser, user in local.eks_access_entries_qa : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
policy_arn = var.eks_access_policies.namespace_read_only
access_scope {
type = "namespace"
namespaces = var.eks_access_scope["qa"].namespaces_read_only
}
}
Run terraform plan - and we'll have our users:
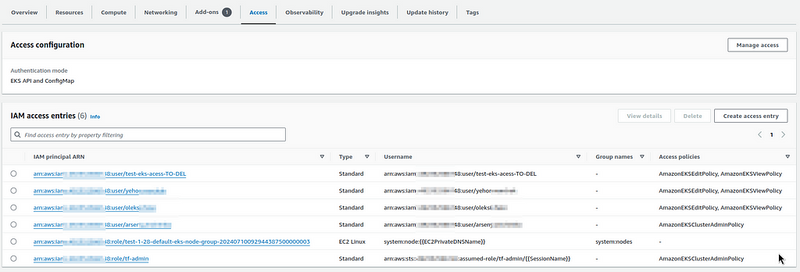
Run terraform apply, and check EKS Access Entries:
And permissions for the backend group:
Let’s check how everything works.
Create a kubectl context for the test user (--profile test-eks):
$ aws --profile test-eks eks update-kubeconfig --name atlas-eks-test-1-28-cluster --alias test-cluster-test-profile
Updated context test-cluster-test-profile in /home/setevoy/.kube/config
Check with kubectl auth can-i.
We can’t do anything in the default Namespace:
$ kk -n default auth can-i list pods
no
And a Namespace with the “backend” name — here we can create Pods:
$ kk -n dev-backend-api-ns auth can-i create pods
yes
A Namespace with “ops” — we can execute a list:
$ kk -n ops-monitoring-ns auth can-i list pods
yes
But we can’t create anything:
$ kk -n ops-monitoring-ns auth can-i create pods
no
Okay, everything seems to be ready here.
The AIM Roles for GitHub Actions are not different from regular users, so we can add them in the same way.
Terraform and EKS Pod Identities
The second thing we need to do is create Pod Identity associations to replace the old scheme with EKS ServiceAccounts and OIDC.
Note : don’t forget to add eks-pod-identity-agent Add-On, example for terraform-aws-modules/eks can be found [_here>>>](https://github.com/terraform-aws-modules/terraform-aws-eks/blob/d7aea4ca6b7d5fa08c70bf67fa5e9e5c514d26d2/examples/eks-managed-node-group/eks-al2023.tf#L11)._
For example, on the current cluster, we have a ServiceAccount for Yet Another CloudWatch Exporter (YACE):
$ kk -n ops-monitoring-ns get sa yace-serviceaccount -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::492***148:role/atlas-monitoring-ops-1-28-yace-exporter-access-role
...
What we need to do is to create Pod Identity associations with the following parameters:
cluster_namenamespaceservice_accountrole_arn
Currently, an IAM Role for the YACE is created in the Terraform code in our Monitoring project repository, and we have two options how to create it now:
- move the creation of all IAM Roles for all projects to this new one, and then create
aws_eks_pod_identity_associationhere - but this will require changing a lot of code — removing the creation of IAM Roles in other projects and adding them to this new one, plus developers (if we talk about the Backend API) are already somehow used to doing this in their projects — you will need to write documentation on how to do it in another project
- or leave the creation of IAM Roles in each project separately — and in the new one just have a variable with lists of other projects and their roles (or use
terraform_remote_stateandterraform outputsfrom each project) - but here we will have a little bit of complexity with the launch of new projects, especially if roles will be created with some dynamic names — because you will have to first perform terraform apply in a new project, get the ARN of the roles there, then add them to the variables of the "atlas-iam" project, do
terraform applyhere to connect these roles to EKS, and only then do a somehelm installwith the creation of a ServiceAccount for the new project
But in both cases, we will need to set the following parameters for Pod Identity associations:
-
cluster_name: the variable already exists - ServiceAccount names: they will be the same on all clusters
-
role_arn: depends on how we create IAM Roles -
namespace: and here's the tricky part: - we have the same Namespace for monitoring on all clusters -”ops-monitoring-ns”, where Ops is an AWS or EKS environment
- but for the backend, we have Dev, Staging, and Production on the same cluster — each in its own Namespace
But in the Namespace for a Pod Identity association, we can no longer use "*" form as we did with Access Entries for users, meaning that we have to create a separate Pod Identity association for each specific Namespace.
Let’s first look at how we can create the necessary resources in general — and then think about the variables and decide how to implement it.
Option 1: Using resource "aws_eks_pod_identity_association"
We can use the “vanilla” aws_eks_pod_identity_association with Terraform AWS Provider.
To create a Pod Identity association for our conditional YACE exporter, we need to specify:
-
assume_role_policy: who can perform the IAM Role Assume -
aws_iam_role: IAM Role with the necessary access to the AWS API -
aws_eks_pod_identity_association: connect this Role to the EKS cluster and ServiceAccount in it
Let’s make a separate file for the roles — eks_pod_iam_roles.tf.
Define an aws_iam_policy_document - no OIDCs now, just pods.eks.amazonaws.com:
# Trust Policy to be used by all IAM Roles
data "aws_iam_policy_document" "assume_role" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["pods.eks.amazonaws.com"]
}
actions = [
"sts:AssumeRole",
"sts:TagSession"
]
}
}
Next is the IAM Role itself.
Roles will need to be created for each cluster, so we’ll take our variable "eks_clusters" again, and then create roles with names for each cluster in a loop:
# Create an IAM Role to be assumed by Yet Another CloudWatch Exporter
resource "aws_iam_role" "yace_exporter_access" {
for_each = var.eks_clusters
name = "${each.key}-yace-exporter-role"
assume_role_policy = data.aws_iam_policy_document.assume_role.json
inline_policy {
name = "${each.key}-yace-exporter-policy"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = [
"cloudwatch:ListMetrics",
"cloudwatch:GetMetricStatistics",
"cloudwatch:GetMetricData",
"tag:GetResources",
"apigateway:GET"
]
Effect = "Allow"
Resource = ["*"]
},
]
})
}
tags = {
Name = "${each.key}-yace-exporter-role"
}
}
And now we can add an association to eks_pod_identities.tf:
resource "aws_eks_pod_identity_association" "yace" {
for_each = var.eks_clusters
cluster_name = each.key
namespace = "example"
service_account = "example-sa"
role_arn = aws_iam_role.yace_exporter_access["${each.key}"].arn
}
Where in the "aws_iam_role.yace_exporter_access["${each.key}"].arn" we refer to an IAM Role with the specific name of each cluster:
...
# aws_eks_pod_identity_association.yace["atlas-eks-test-1-28-cluster"] will be created
+ resource "aws_eks_pod_identity_association" "yace" {
+ association_arn = (known after apply)
+ association_id = (known after apply)
+ cluster_name = "atlas-eks-test-1-28-cluster"
+ id = (known after apply)
+ namespace = "example"
+ role_arn = (known after apply)
+ service_account = "example-sa"
+ tags_all = {
+ "component" = "devops"
+ "created-by" = "terraform"
+ "environment" = "ops"
}
}
...
Option 2: Using the terraform-aws-eks-pod-identity
Another option is to use terraform-aws-eks-pod-identity. Then we don't need to describe an IAM Role separately - we can set the IAM Policy directly in the module, and it will create everything for us. In addition, it allows you to create multiple associations for different clusters in one module.
For example:
module "yace_pod_identity" {
source = "terraform-aws-modules/eks-pod-identity/aws"
version = "~> 1.2"
for_each = var.eks_clusters
name = "${each.key}-yace"
attach_custom_policy = true
source_policy_documents = [jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = [
"cloudwatch:ListMetrics",
"cloudwatch:GetMetricStatistics",
"cloudwatch:GetMetricData",
"tag:GetResources",
"apigateway:GET"
]
Effect = "Allow"
Resource = ["*"]
},
]
})]
associations = {
ex-one = {
cluster_name = each.key
namespace = "custom"
service_account = "custom"
}
}
}
Both a role and an association will be created for each cluster:
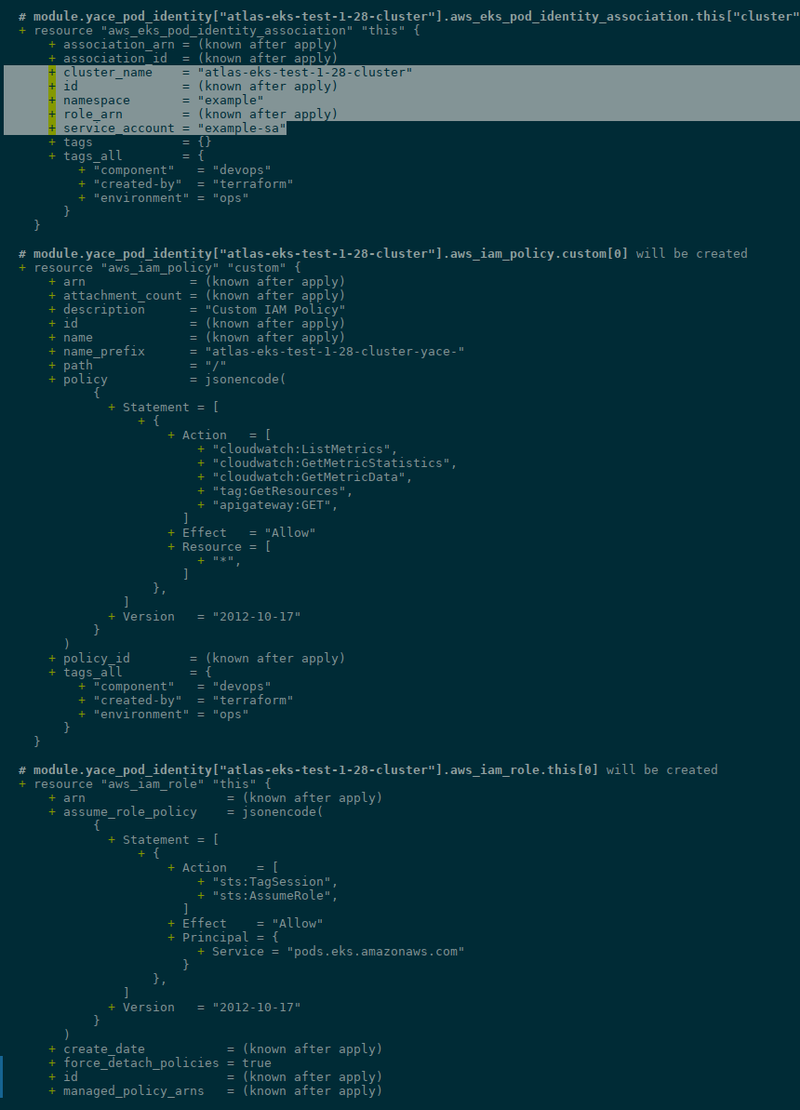
Also, terraform-aws-eks-pod-identity can create all kinds of default IAM Roles - for ALB Ingress Controller, External DNS, etc.
But in my case, these services in EKS are created from aws-ia/eks-blueprints-addons/aws, which creates roles itself, and I don't see any changes regarding the Pod Identity association there (although the GitHub issue with the discussion is open back in November 2023 - see Switch to IRSAv2/pod identity).
Okay.
So how do we do this whole scheme?
- we will have IAM Roles — created either in other projects, or in our_”atlas-iam_”
- we will know which ServiceAccounts we need to connect to which Namespaces
What variable can we come up with for all this?
We can set a project name -”backend-api”, “monitoring”, etc., and in each project have lists with namespaces, ServiceAccount, and IAM Roles.
And then, for each project, have a separate resource aws_eks_pod_identity_association, which will loop through all EKS clusters in the AWS account.
The problem: Pod Identity association and dynamic Namespaces
But! For the Backend API in GitHub Actions, we create dynamic environments, and for them — Kubernetes Namespaces with names like_”pr-1212-backend-api-ns_”. That is, there are static namespaces -”dev-backend-api-ns”,”staging-backend-api-ns”, and_”prod-backend-api-ns”_- that we know, but there will be names that we cannot find out in advance.
There is a GitHub issue on a similar topic that was opened in December 2023 — [EKS]: allow EKS Pod Identity association to accept a glob for the service account name (my-sa-*), but it is still unchanged.
Therefore, we can either leave the old IRSA for the backend, and use Pod Identity only for those projects that have static naming conventions, or instead of dynamic Namespaces — have one predefined name like “test-backend-api-ns”, and deploy to it with Helm releases containing names with PR ID.
Pod Identity association for the Monitoring project
So, let’s make one association, and then we will see how we can improve the process.
In the monitoring project, I have 5 custom IAM Roles — for Grafana Loki with S3 access, one for the common CloudWatch Exporter, one for Yet Another CloudWatch Exporter, one for our own Redshift Exporter, and one for the X-Ray Daemon.
IAM Roles creation is still probably best to be done in this project,”atlas-iam”. Then, when creating a new project, we first describe its Role in this project and its Association in the necessary Namespaces with the desired ServiceAccount, and then in the project itself, we specify the name of the ServiceAccount in the Helm chart.
As for the terraform-aws-modules/eks-pod-identity/aws, I think it's more tailored to all kinds of default roles, although you can create your own.
But now it will be easier to do this:
- create IAM Roles for each service with the usual
aws_iam_roleresource - and connect these roles to clusters with the resource
aws_eks_pod_identity_association
So, let’s create a new variable with projects, their namespaces, and ServiceAccounts:
variable "eks_pod_identities" {
description = "EKS ServiceAccounts for Pods to grant access with eks-pod-identity"
type = map(object({
namespace = string,
projects = map(object({
serviceaccount_name = string
}))
}))
default = {
monitoring = {
namespace = "ops-monitoring-ns"
projects = {
loki = {
serviceaccount_name = "loki-sa"
},
yace = {
serviceaccount_name = "yace-sa"
}
}
}
}
}
Next, in the eks_pod_iam_roles.tf file, we'll create a Role - as we did above, but without loops, because we have one Role for the entire AWS account that will connect to different Kubernetes clusters:
# Trust Policy to be used by all IAM Roles
data "aws_iam_policy_document" "assume_role" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["pods.eks.amazonaws.com"]
}
actions = [
"sts:AssumeRole",
"sts:TagSession"
]
}
}
# Create an IAM Role to be assumed by Yet Another CloudWatch Exporter
resource "aws_iam_role" "yace_exporter_access" {
name = "monitoring-yace-exporter-role"
assume_role_policy = data.aws_iam_policy_document.assume_role.json
inline_policy {
name = "monitoring-yace-exporter-policy"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = [
"cloudwatch:ListMetrics",
"cloudwatch:GetMetricStatistics",
"cloudwatch:GetMetricData",
"tag:GetResources",
"apigateway:GET"
]
Effect = "Allow"
Resource = ["*"]
},
]
})
}
tags = {
Name = "monitoring-yace-exporter-role"
}
}
We will have one data object "aws_iam_policy_document" "assume_role" here - and then we will use it in all IAM Roles.
Next, in the file eks_pod_identities.tf we describe the actual aws_eks_pod_identity_association using the namespace and service_account from the variable described above, and the role_arn is obtained from the resource "aws_iam_role" "yace_exporter_access", and the names of the clusters are taken in a loop from the variable var.eks_clusters:
resource "aws_eks_pod_identity_association" "yace" {
for_each = var.eks_clusters
cluster_name = each.key
namespace = var.eks_pod_identities.monitoring.namespace
service_account = var.eks_pod_identities.monitoring.projects["yace"].serviceaccount_name
role_arn = aws_iam_role.yace_exporter_access.arn
}
Run terraform plan:
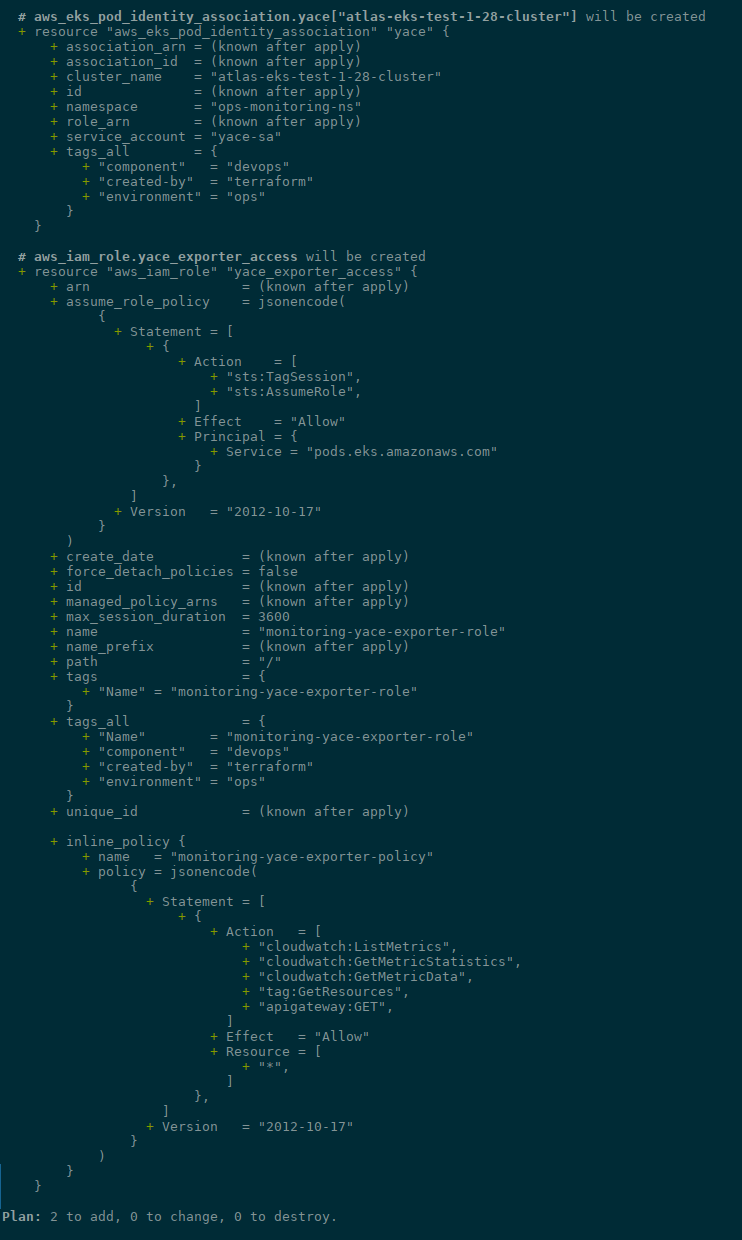
Run terraform apply, and check Pod Identity associations in EKS:

Testing EKS Pod Identities
Let’s see if it works.
Describe a Kubernetes Pod with the AWS CLI container and a ServiceAccount named "yace-sa":
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: yace-sa
namespace: ops-monitoring-ns
---
apiVersion: v1
kind: Pod
metadata:
name: pod-identity-test
namespace: ops-monitoring-ns
spec:
containers:
- name: aws-cli
image: amazon/aws-cli:latest
command: ['sleep', '36000']
restartPolicy: Never
serviceAccountName: yace-sa
Create them:
$ kk apply -f irsa-sa.yaml
serviceaccount/yace-sa created
pod/pod-identity-test created
Connect to the Pod:
$ kk -n ops-monitoring-ns exec -ti pod-identity-test -- bash
And try to execute an AWS CLI command to CloudWatch — for example, "cloudwatch:ListMetrics" to which we gave permissions in the IAM Role:
bash-4.2# aws cloudwatch list-metrics --namespace "AWS/SNS" | head
{
"Metrics": [
{
"Namespace": "AWS/SNS",
"MetricName": "NumberOfMessagesPublished",
"Dimensions": [
{
"Name": "TopicName",
"Value": "dev-stable-diffusion-running-opsgenie"
But if we’ll try to run a command for S3, we’ll fail because we don’t have permissions for it:
bash-4.2# aws s3 ls
An error occurred (AccessDenied) when calling the ListBuckets operation: Access Denied
Conclusions
So, what we have in the end.
Everything is pretty clear with EKS Access Entries , and the solution looks good: we can manage users for different EKS clusters and even different AWS accounts from one Terraform code.
The code described in eks_access_entires.tf allows us to flexibly create new EKS Authentication API Access Entries for different users with different permissions, although I did not touch on the Kubernetes RBAC yet - creating separate groups with their own RoleBindings. But in my case, this is still a bit overhead for now.
But with EKS Pod Identities , the automation “failed” — because currently there is no way to use "*" in the names of Namespaces and/or ServiceAccounts, and therefore we have to be quite strictly tied to some permanent names. So, the described solution can be applied when you have pre-known object names in Kubernetes - but for some dynamic solutions, you will still have to use the old scheme with IRSA and OIDC.
However, I hope that this point will be fixed, and then we will be able to manage all our projects from the same code.
Originally published at RTFM: Linux, DevOps, and system administration.

Top comments (0)