
Lots of folks ask us about pulling information from the PagerDuty API and making it accessible in their chat service of choice. One big piece of information is who is the current on-call engineer for a particular team.
PagerDuty has an open source project that runs in AWS Lambda to do this. It has a number of interesting features, is persistent to a DynamoDB, and is useful for accounts for lots of teams. But it’s pretty tied to Lambda, which is great if you’re using AWS, maybe not what you want if you’re not, or you’re not up for some Lambda experimentation. So we’ll walk through the components and calls you’d need to create something similar that works in a more general environment.
It’s also set up based on our requirements that teams configure schedules and those schedules are included in the escalation policies on the team’s services. We’ll look at an alternative to this setup, using the /oncalls endpoint, in Part 2.
You can also decide how often you’d want to run a script like this. On-call schedules can change at any time, really, as teams have preferences for how they want their schedules to run, plus overrides can be scheduled whenever. So while our script runs in our environment every few minutes, you may not need that kind of granularity.
This example will follow some of the same processes as my earlier post on maintenance windows.
You’ll find this code in GitHub at https://github.com/lnxchk/pdgarage-samples/blob/main/python/oncall_to_slack.py.
Prerequisites
- An API Key for PagerDuty REST API. (Different from the events API). If you’re only interested in the on-call for a single team, you could use a personal key. If you want to look across multiple teams in an account, you’ll want an account-wide key, and you’ll need admin permissions to do that.
- A webhook or target to send information to Slack. YMMV on how you’d like to integrate with Slack. You have a couple of different options - I’m following along with the instructions here as a prerequisite for this setup, and I’m using the same endpoint I used for my other post. ;)
In Python
I’m going to use Python 3.9 for this example. I’ve not tested all of the bits with earlier versions of Python, so there might be some things that don’t quite work.
The PagerDuty API library for Python is called pdpyras, and I’ll be using that to make requests to the API. You can also use the requests library, if that’s more to your liking. Some of the data structures will be different from what’s below, but aren’t too wild. The requests library is still necessary for sending information to the Slack webhook.
Other packages I’m using are json for reading and creating JSON objects, os for pulling keys out of the running shell environment (you can use a vault of some sort instead), and datetime, timedelta, and timezone from the datetime package, since we’ll be looking for overrides to the configured schedules.
What We’ll Get
This example will walk through all the configured schedules in an account. If you are working in a large PagerDuty account with a lot of schedules, the solution in the open source example might be more helpful - it will request only the schedules you tell it to request, rather than all possible schedules. You can set up a persistent data structure to keep track of which schedules you want to monitor.
I’m also only going to target a single channel in Slack, but you can set up your code to push information to multiple channels.
The API Objects
On-call assignments in PagerDuty are governed by schedules. Schedules might be related to teams, but they don’t have to be. This can cause some confusion for folks!
The Highlights
- Request all the schedules in the account using the
/schedulesendpoint - Get the current on-call for each schedule returned from the request using the
/schedules/ID/oncallsendpoint - Determine if the current on-call for the schedule is an override, and note that with the end time for the override. We’ll use the
/schedules/ID/overridesendpoint for that information - Then we’ll wrap it all up in a structure we can send to Slack!
The Code
Start an API Session
To set up the session with the PagerDuty API, I’ll initialize it with my API Key, which I’ve stored in the shell environment for ease of use:
api_token = os.environ['PD_API_KEY']
# initialize the session with the PagerDuty API
session = APISession(api_token)
I’ve also stored my Slack webhook URL in another environment variable:
slack_url = os.environ['SLACK_CHANNEL_URL']
Start the Slack Message Structure
I’m going to be sending data to slack as a plain Slack message. Slack uses Block Kit for formatting messages, and each piece of the message (in our case, each schedule line) will be its own block. So I’m going to build an array of blocks that we’ll turn into JSON later. This first block will serve as a header for my message.
blocks = []
header_block = {
"type": "header",
"text": {
"type": "plain_text",
"text": "Oncall Now:"
}
}
blocks.append(header_block)
Make Some Times
To get the overrides, we have to request the overrides that appear in a certain window (even if we only want the ones that are active NOW). So I’m going to set up some times and format them for the API:
# since_time for the overrides window
since = datetime.now(timezone.utc)
until = since + timedelta(minutes=1)
since_time = since.isoformat()
until_time = until.isoformat()
Make the Request for the List of All Schedules
Now let’s make the first request. This request will return all schedules configured in the account, whether there is someone currently on-call or not!
sched_response = session.rget("/schedules")
I’m using rget here so pdpyras will unwrap the JSON for me. You can use just session.get and it will behave more like a basic requests request.
Walk the Schedules Array
For each schedule that is returned into sched_response, I want to find some information, and then I’m going to make another API request to get the person currently listed as on-call for that schedule.
The second set of requests I’ll make - one for each schedule - will be to /oncalls with the specific schedule ID that I pulled from the data in the first query.
for sched in sched_response:
sched_id = sched['id']
sched_name = sched['summary']
# request individual schedule from the sched_id
get_the_oncall = session.rget("/oncalls?schedule_ids[]={}".format(sched_id))
try:
user = get_the_oncall[0]['user']['summary']
except IndexError:
user = "No One"
I’m using a try here in case a schedule has no one currently listed as on call. The structure of the objects returned from /oncalls is another array, so I’m checking for the 0th user, and if there isn’t one, I’ll get an IndexError on the array and I’ll name the user “No One”.
Looking for Overrides
You might be interested in whether or not the current on-call is on duty because of an override - a temporary change to the on-call schedule. The information about overrides is accessible from a different endpoint in the API. Here is where I’ll have to use those times I set up above. To use the /schedules/ID/overrides endpoint, I need to include a time window. I set our since_time and until_time a minute apart so I’m sure to get the overrides that are active now.
If overrides aren’t interesting to your team, you can skip this part!
# query PagerDuty for the overrides
querystring = {"since": since_time, "until": until_time}
override_endpoint = "/schedules/{}/overrides".format(sched_id)
overrides = session.rget(override_endpoint, params=querystring)
if overrides:
# if there are overrides, figure them out here
# otherwise, default to the main on-call
e_time = datetime.strptime(overrides[0]['end'], "%Y-%m-%dT%H:%M:%S%z")
e_readable = e_time.strftime("%H:%M %Z")
user = user + " (Override until {})".format(e_readable)
You can see that I’m appending to the user object here to note that there is an override in place, and a note for when it will end.
Build the Block for this On-call User
Each active schedule will have a line in the output, and each line of output is a block in a Slack message, so build the message block in the loop and add it to the larger blocks array we started earlier:
oncall_string = "{} is oncall for {}".format(user, sched_name)
# user for the current schedule
oncall_block = {
"type": "section",
"text": {
"type": "mrkdwn",
"text": oncall_string
}
}
blocks.append(oncall_block)
Send it to Slack
The last bit is to take our blocks array and turn it into JSON so Slack can parse it. Then we’ll make a webhook request to Slack:
# build the json payload
payload = {
"blocks": blocks
}
j_payload = json.dumps(payload)
# create and send the request to the slack webhook url
slack_headers = {"Content-Type": "application/json"}
sent_msg = requests.post(slack_url, headers=slack_headers, data=j_payload)
sent_msg.raise_for_status()
print(sent_msg.text)
If there is a problem with the request, the last two lines will print it to the screen. You can take these lines out to prevent any output being shown to the console when you’re running this from a scheduled job.
Sample Output
No Overrides, A Schedule with No One On-Call
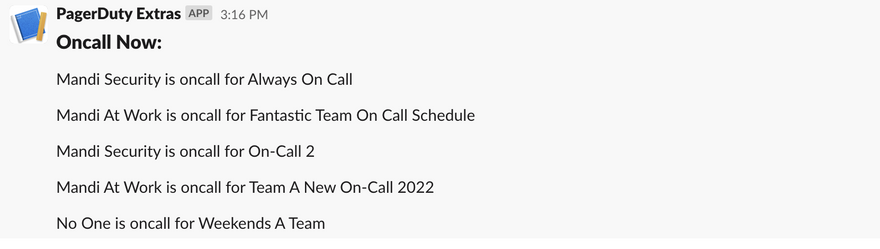
One Schedule with a Current Override

Next Steps
Depending on how your organization manages schedules, and how they relate to the structure of your teams, you can configure your update script to send information to different channels based on team, like our open source example does, or just to one channel where folks can find all the current on-calls.
You could also add more information to the messages in Slack, like adding links to the objects in the UI so you can notify folks or find other information about what services they are responsible for.
In the next part of this series, we’ll look at the /oncalls endpoint by itself, which has a different set of behaviors from what we’ve looked at here.

Top comments (1)
Goedemiddag! Ik zocht naar een plek waar ik rustig een potje poker kon spelen in Nederland. Via een online review kwam ik bij instasino terecht en de sfeer aan de tafels is daar erg sportief. De software werkt zonder problemen en de lobby is heel duidelijk ingedeeld. Gisteravond had ik een geweldige sessie waarin ik na een paar spannende handen een mooie winst boekte. Het is een betrouwbare plek waar ik me echt gewaardeerd voel.