What is service registration discovery?
For developers who work with microservices, the concepts of service discovery should be familiar.
For example, if service A depends on service B, we need to tell service A where to invoke service B. This is the problem that service discovery has to solve.
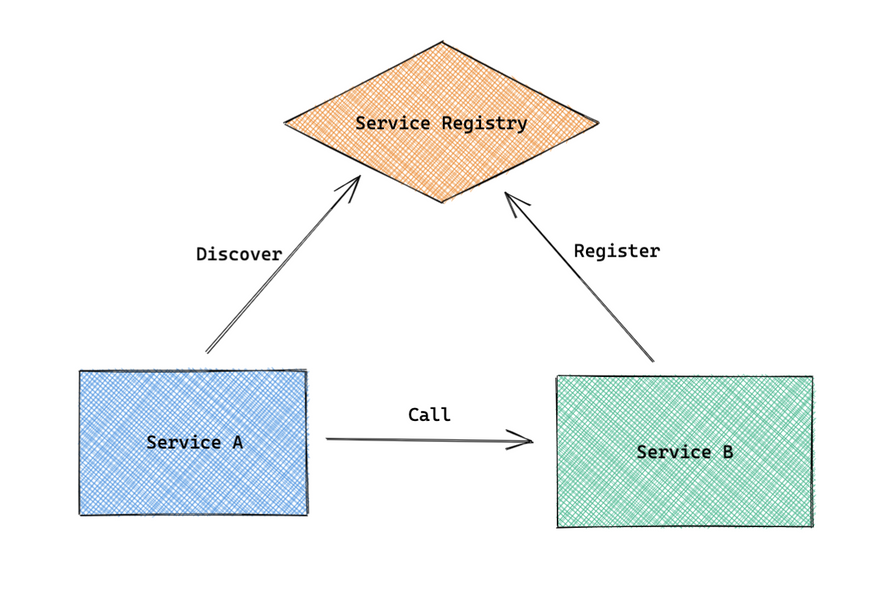
-
Service Bregisters itself to theService Registrycalled Service Registration -
Service Adiscovering node information ofService BfromService Registryis called Service Discovery
Service Registration
Service registration is for the server side and is required after the service is started and is divided into several parts.
- Startup registration
- Timed Renewal
- Withdrawal
Startup Registration
When a service node is up, it needs to register itself to the Service Registry so that other nodes can easily discover itself. The registration needs to be done when the service is up and ready to accept requests, and a validity period will be set to prevent the process from being accessed even after an abnormal exit.
Timed Renewal
The equivalent of keep alive is to periodically tell Service Registry that it is still alive and can continue to serve.
Withdrawal
When a process exits, we should actively revoke the registration information so that the caller can distribute the request to another node in time. At the same time, go-zero ensures that even if a node exits without active deregistration, the node can be taken off in time by adaptive load balancing.
Service Discovery
Service discovery is for the caller side and is generally divided into two types of problems.
- Inventory fetch
- Incremental watch
There is also a common engineering problem of
- Coping with service discovery failures
When a service discovery service (such as etcd, consul, nacos, etc.) goes down, we don't modify the list of endpoints we've already fetched, so we can better ensure that the services we depend on can still interact properly after etcd, etc. goes down.
Inventory fetch
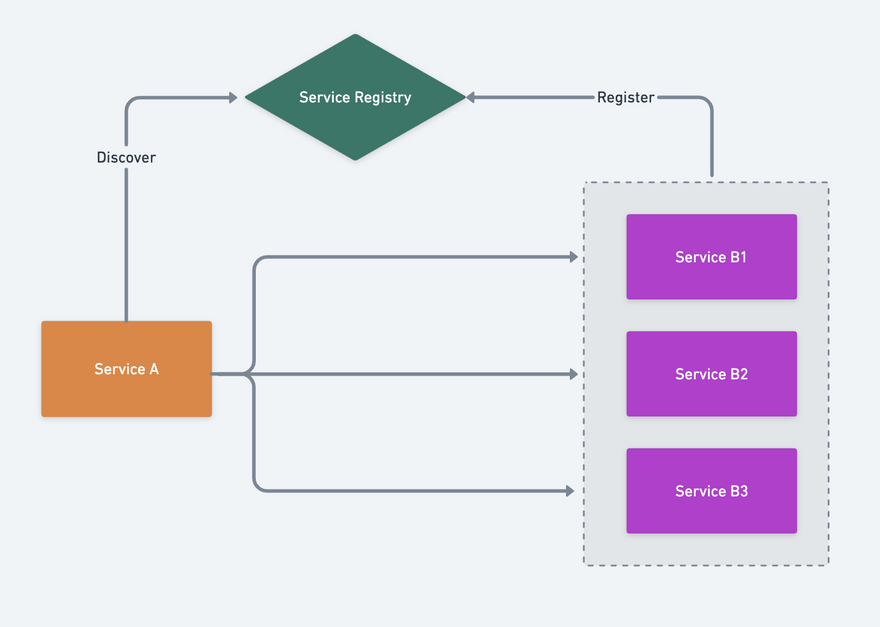
When Service A starts, it needs to get the list of existing nodes of Service B from Service Registry: Service B1, Service B2, Service B3, and then select the appropriate nodes to send requests based on its own load balancing algorithm.
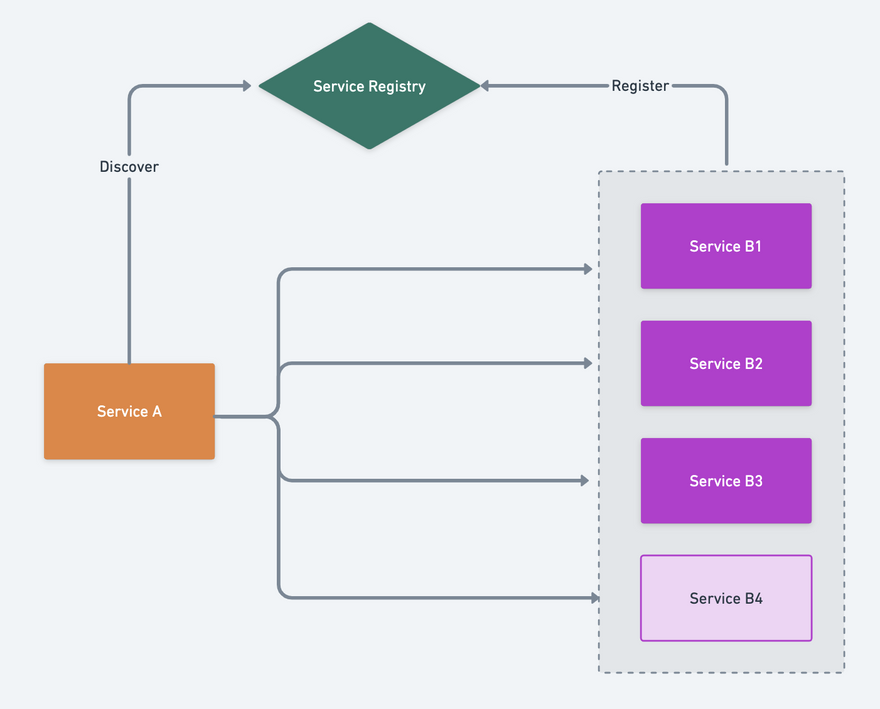
Incremental watch
The above diagram already has Service B1, Service B2, Service B3, if Service B4 is started, then we need to notify Service A that there is an additional node. As shown in the figure.
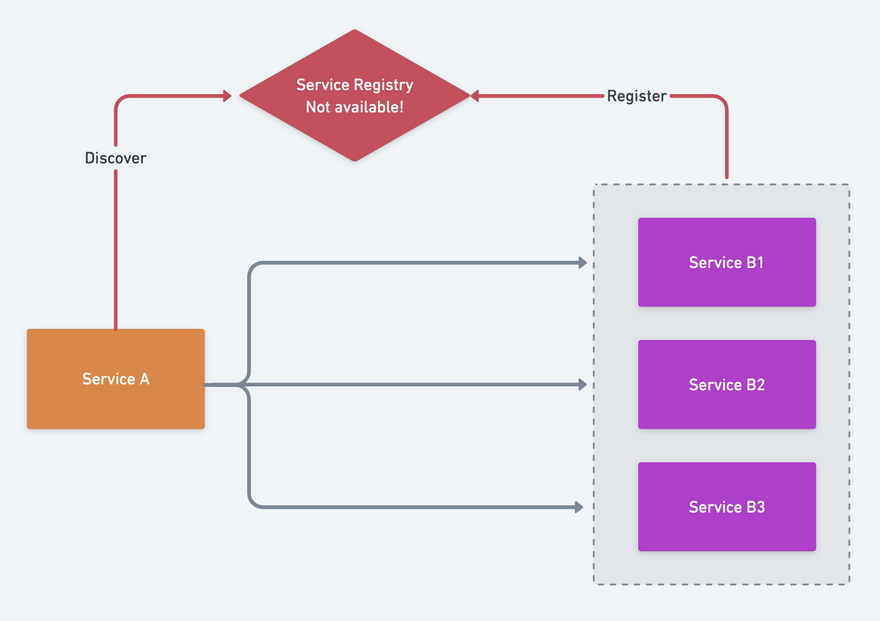
Service discovery failures
For service callers, we all cache a list of available nodes in memory. Whether we use etcd, consul or nacos, we may face a service discovery cluster failure, take etcd as an example, when we encounter etcd failure, we need to freeze the node information of Service B without changing it, we must not empty the node information at this time, once it is empty, we can't get it, while the nodes of Service B nodes are probably normal, and go-zero will automatically isolate and restore the failed node.
This is the basic principle of service registration and service discovery, but of course it is still complicated to implement, so let's take a look at what service discovery methods are supported in go-zero.
go-zero's built-in service discovery
go-zero supports three service discovery methods by default.
- direct connection
- direct connection * etcd-based service discovery
- kubernetes endpoints-based service discovery
Direct connection
Direct connection is the simplest way, when our service is simple enough, such as a single machine can host our business, we can just use this way.
Specify endpoints directly in the rpc configuration file, e.g.
Rpc:
Endpoints:
- 192.168.0.111:3456
- 192.168.0.112:3456
The zrpc caller will allocate the load to these two nodes, one of the nodes has a problem zrpc will automatically take off, and when the node is restored will again allocate the load.
The disadvantage of this approach is that the nodes cannot be added dynamically, and each new node requires a change in the caller's configuration and a restart.
etcd-based service discovery
Once our service has a certain size, because a service may be dependent on many services, we need to be able to dynamically add and remove nodes without having to modify many caller configurations and restarts.
Common service discovery solutions are etcd, consul, nacos, etc.
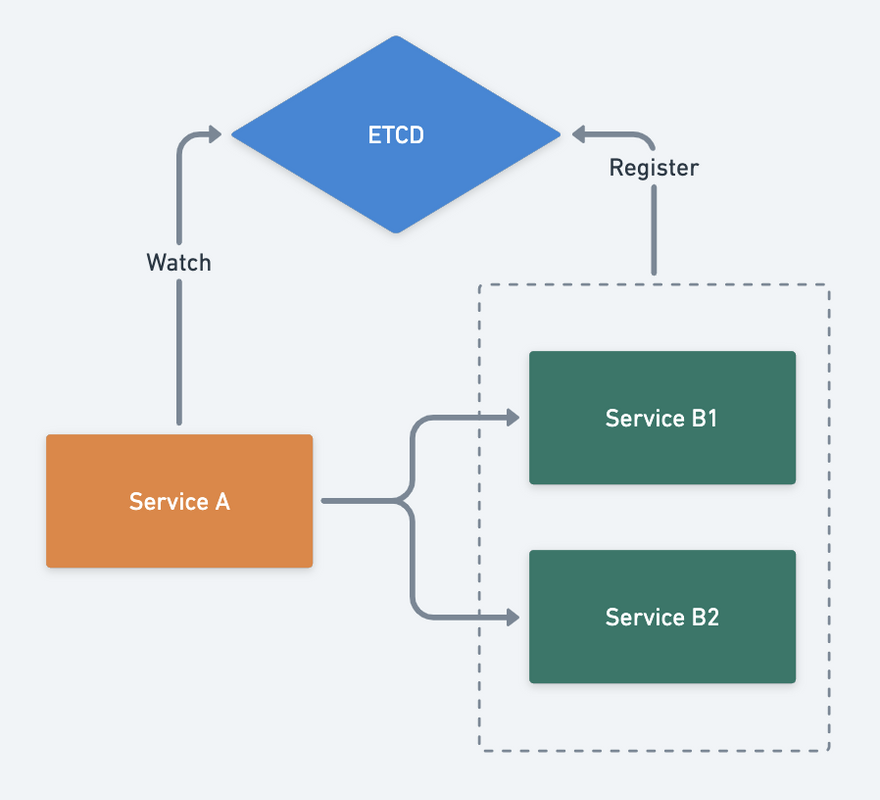
go-zero has a built-in etcd-based service discovery scheme, which is used as follows.
Rpc:
Etcd:
Hosts:
- 192.168.0.111:2379
- 192.168.0.112:2379
- 192.168.0.113:2379
Key: user.rpc
-
Hostsis theetcdcluster address -
Keyis thekeyon which the service is registered
Service discovery based on Kubernetes Endpoints
If our services are deployed on a Kubernetes cluster, Kubernetes itself manages the cluster state through its own etcd, and all services register their node information to Endpoints objects, so we can directly give deployment permissions to read the cluster's Endpoints object to get the node information.
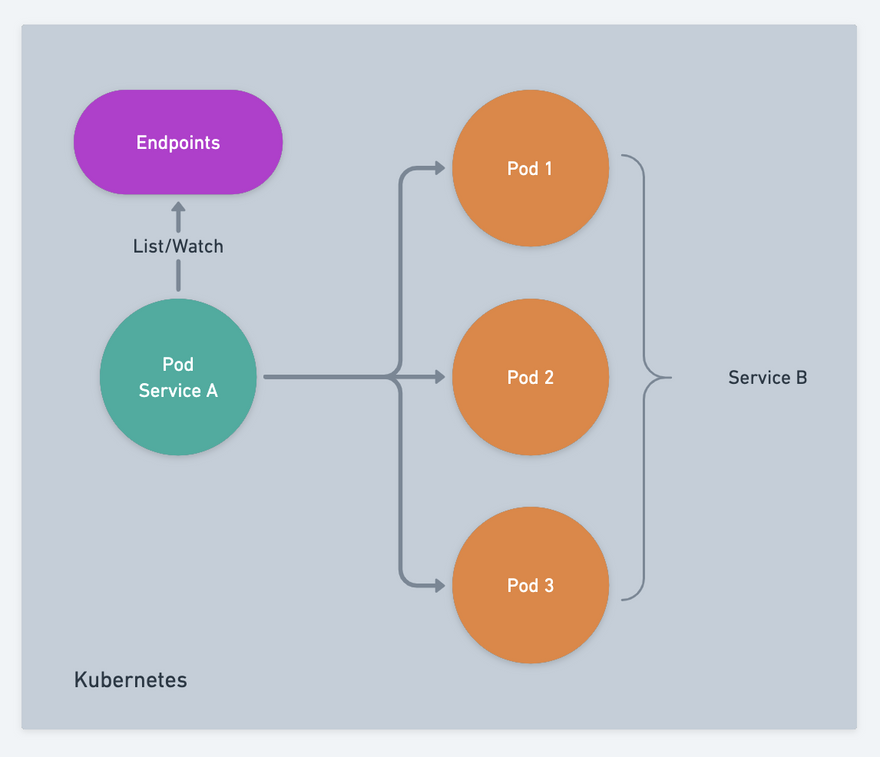
- Each
PodofService Bwill register itself to theEndpointsof the cluster when it starts - When each
PodofService Astarts, it can get the node information ofService Bfrom theEndpointsof the cluster - When the node of
Service Bchanges,Service Acan sense it throughEndpointsof thewatchcluster
Before this mechanism can work, we need to configure the pod in the current namespace to have access to the cluster Endpoints, where there are three concepts.
- ClusterRole
- ClusterRole defines a cluster-wide permission role that is not controlled by
namespace.
- ClusterRole defines a cluster-wide permission role that is not controlled by
- ServiceAccount
- Defines the
service accountwithin thenamespacescope
- Defines the
- ClusterRoleBinding
- Bind a defined
ClusterRoleto aServiceAccountin a differentnamespace
- Bind a defined
The specific Kubernetes configuration file can be found here, where namespace is modified as needed.
Note: Remember to check if these configurations are in place when you start up and don't have access to Endpoints :)
zrpc's Kubernetes Endpoints based service discovery is used as follows.
Rpc:
Target: k8s://mynamespace/myservice:3456
where.
-
mynamespace: thenamespacewhere the invokedrpcservice is located -
myservice: the name of the invokedrpcservice -
3456: the port of the calledrpcservice
Be sure to add serviceAccountName to specify which ServiceAccount to use when creating the deployment configuration file, for example
apiVersion: apps/v1
kind: Deployment
metadata:
name: alpine-deployment
labels:
app: alpine
spec:
replicas: 1
selector:
matchLabels:
app: alpine
template:
metadata:
labels:
app: alpine
spec:
serviceAccountName: endpoints-reader
containers:
- name: alpine
image: alpine
command:
- sleep
- infinity
Note that serviceAccountName specifies which ServiceAccount is used for the pod created by the deployment.
After both server and client are deployed to the Kubernetes cluster, you can restart all server nodes on a rolling basis with the following command
kubectl rollout restart deploy -n adhoc server-deployment
Check the client node log with the following command.
kubectl -n adhoc logs -f deploy/client-deployment --all-containers=true
You can see that our service discovery mechanism follows the changes to the server node perfectly, and there are no exception requests during service updates.
The full code example is available at https://github.com/zeromicro/zero-examples/tree/main/discovery/k8s
In the next article I will explain how to implement service registration discovery based on consul, nacos, etc. in go-zero, so stay tuned!
Project address
https://github.com/zeromicro/go-zero
Welcome to use go-zero and star to support us!

Top comments (0)