
I had a very interesting use case lately: being able to upload a file to S3 without being signed in to AWS and taking advantage of multipart uploads (large files) in Python. This made me dig deeper into AWS presigned URLs, and multipart uploads. And the fun part is, the final solution doesn't use any of it! Curious? Read on!
🔖 I created this Table of Contents using BitDownToc. If you are curious, read my article: Finally a clean and easy way to add Table of Contents to dev.to articles 🤩
The use case
I have an API with its own authentication mechanism that uses AWS S3 as a file storage and provides a CLI to simplify the user experience. Through the CLI, users can do cool stuff such as uploading files (used later to do other cool stuff, but the details do not matter). In the current implementation, the CLI sends the files (that can be multiple GBs!) to the API (using a POST 😬), which subsequently handles the upload to S3.
To make it more efficient, I want the CLI to upload files directly to S3 and leverage AWS multipart uploads. Multipart upload means splitting a large file into chunks that can be uploaded in parallel (faster) and retried separately (more reliable).
In summary, I need the ability to:
upload a file to S3 without "real" AWS credentials (or at least with limited temporary permissions provided by the API), and
use the S3 multipart upload mechanism.
Attempt 1: REST + presigned URLs 😕
From the AWS documentation:
You can use presigned URLs to grant time-limited access to objects in Amazon S3 without updating your bucket policy. [...] The credentials used by the presigned URL are those of the AWS user who generated the URL.
You can use presigned URLs to allow someone to upload a specific object to your Amazon S3 bucket. This allows an upload without requiring another party to have AWS security credentials or permissions.
Presigned URLs for upload contain a bucket, a path, and an expiration date. You can use the link multiple times (it will replace the object) until the expiration.
A simple PUT with a presigned URL
To generate a presigned URL for upload with the boto3 s3 client, I can use either generate_presigned_post or generate_presigned_url. I prefer the latter, as it returns a single URL ready for use instead of an URL plus some fields that need to be passed with the PUT.
Given the required environment variables (AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_DEFAULT_REGION) are present, here is the API side:
import boto3
def gen_presigned_url_for_post(
bucket_name, object_name, expiration=3600
):
# boto3 will read credentials from the environment
s3_client = boto3.client("s3")
return s3_client.generate_presigned_url(
ClientMethod="put_object",
Params={"Bucket": bucket_name, "Key": object_name},
ExpiresIn=expiration,
HttpMethod="PUT",
)
And the user (CLI) side:
import requests
from pathlib import Path
def use_presigned_url(url, local_file):
# Same as curl -X PUT --upload-file <local-file> <url>
files = {"file": Path.open(local_file, "rb")}
# Important: clear headers!
requests.put(url, files=files, headers={"Content-Type": ""})
Putting them together:
url = gen_presigned_url_for_post("my-bucket", "foo/data.dump")
use_presigned_url(url, "local.dump")
This works, but a single PUT is limited to 5 GB! For large files, AWS recommends using multipart uploads, which have many advantages, including improved throughput (parallel upload) and quick recovery from network issues (retry only the failed part).
Multipart uploads with presigned URLs
Multipart upload is a 3-steps process:
Initialization - you tell AWS your intent to upload a file in parts. It returns a unique id (
UploadId) that you need to upload parts and finish/cancel the upload.-
Part upload - with each upload, you pass the
UploadIdplus a uniquePartNumberof your choice; AWS returns anETag.Part numbers can be any number from 1 to 10,000, inclusive. A part number uniquely identifies a part and also defines its position within the object being created. If you upload a new part using the same part number, the previously uploaded part is overwritten. The part size should be between 5 MiB to 5 GiB. There is no minimum size limit on the last part of your multipart upload (see Multipart upload limit).
Completion - you finish the upload by sending to AWS both the
UploadIdand the list of (PartNumber+Etag) for each part. AWS assembles the parts into a single file (following thePartNumbers order) and deletes the individual parts.
(Note that parts stay around in S3 until you finish/cancel the upload - that incurs charges! Don't forget to set some cleanup policy for dangling parts if you use this solution.)
So far, so good. Now, what about presigned URLs? Well, the unauthenticated client only performs part uploads (step 2). However, each part upload has different parameters (thanks to the PartId), hence requiring a different presigned URL. In other words, you need as many presigned URLs as the client will have parts to upload!
This process is discussed in the boto3 issue entitled How to use Pre-signed URLs for multipart upload. To make it clearer:
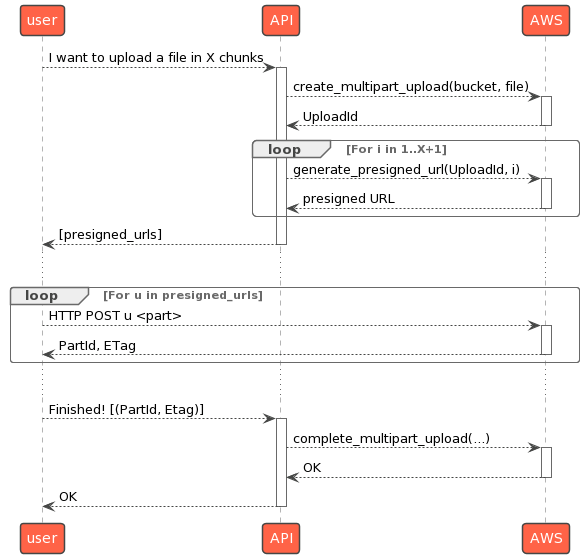
The implementation
How does this translate in Python code? First, the API side:
import logging
import boto3
logging.basicConfig(level=logging.INFO)
class SomeAPIWithAWSAccess:
def __init__(self, bucket: str):
# ↓ AWS client. Requires environment variables!
self.s3 = boto3.client("s3")
self.bucket = bucket
self.logger = logging.getLogger("API")
def upload_multipart_request(self, key: str, num_parts: int):
self.logger.info(f"API: starting multipart for {num_parts} URLs.")
# Initialize the multipart upload
res = self.s3.create_multipart_upload(
Bucket=self.bucket,
Key=key,
)
upload_id = res["UploadId"]
# Generate the presigned URL for each part
urls = []
for part_number in range(1, num_parts + 1): # parts start at 1
url = self.s3.generate_presigned_url(
# The s3 operation is "upload_part"
ClientMethod="upload_part",
Params={
"Bucket": self.bucket,
"Key": key,
"UploadId": upload_id,
"PartNumber": part_number,
},
)
urls.append((part_number, url))
# Create a callback that can be called when
# the upload is finished on the user side
def finish_callback(parts):
self.logger.info("API: finishing multipart upload.")
self.s3.complete_multipart_upload(
Bucket=self.bucket,
Key=key,
MultipartUpload={"Parts": parts},
UploadId=upload_id,
)
# Return the URLs and the callback
return urls, finish_callback
And now the user (CLI) side:
from math import ceil
from pathlib import Path
import requests
logger = logging.getLogger("user")
bucket = "my-bucket" # CHANGE_ME: bucket name
remote_location = "foo/data.dump" # CHANGE_ME: path in the bucket
local_file = "data.dump" # CHANGE_ME: file to upload
chunk_size = 5 * 1024 * 1024 # 5 MB (minimal part size)
def get_num_parts(file_path):
# TODO: make part sizes even
filesize = Path.stat(file_path).st_size
return ceil(filesize / chunk_size)
num_parts = get_num_parts(local_file)
# Start a multipart upload
logger.info("asking for presigned URLs.")
api = SomeAPIWithAWSAccess(bucket)
urls, i_am_done = api.upload_multipart_request(
remote_location,
num_parts,
)
# Upload each part
parts = []
with Path.open(local_file, "rb") as f:
for part_number, url in urls:
logger.info(f"uploading part {part_number}.")
chunk = f.read(chunk_size)
res = requests.put(url, data=chunk)
if res.status_code != 200:
print(f"{res.status_code} {res.reason} {res.text}")
exit(1)
# we have to append etag and partnumber of each parts
parts.append({"ETag": res.headers["ETag"], "PartNumber": part_number})
logger.info("calling finish.")
i_am_done(parts)
To test it, create a random large file of 12MB, export the AWS credentials, and call the program. Don't forget to change the bucket name in the code above!
# AWS
export AWS_ACCESS_KEY_ID=...
export AWS_SECRET_ACCESS_KEY=...
export AWS_DEFAULT_REGION=us-east-1
# Create a "large" file to upload
dd if=/dev/urandom of=data.dump bs=12m count=1
# Call the program
python aws-multipart-upload.py
The problems
I am now able to do multipart uploads with presigned URLs! However:
the user needs to know in advance the number of parts and understand how multipart uploads work (at least
EtagandPartNumber),the user receives URLs... That can't be used with the boto3 client! It is thus his responsibility to implement parallel uploads, retries, etc. The work is huge!
using multipart uploads is very inefficient for small files (< 5MB).
In other words, using multipart uploads with presigned URLs doesn't bring any advantages, except if you are willing to spend days implementing your own upload logic on the user side...
Attempt 2: temporary credentials 😃
What I would like is to be able to use boto3 features on the user side (to get parallel uploads and retries for free) without giving him any permission other than uploading a specific file to a specific s3 bucket location.
How can I do that? Enter federation tokens!
About federation tokens
As explained at length in the docs Comparing the AWS STS API operations, AWS Security Token Service (STS) provides multiple ways of creating temporary credentials: assuming roles, session tokens, and federation tokens. For my use case, federation tokens are perfect, as they support:
- credentials lifetime (i.e. expiry), and
- custom inline policies.
Custom inline policies mean I can create a throw-away policy on the fly and attach it to the federation token upon creation. Here is an example that only allows file uploads to path {PATH} in bucket {BUCKET}:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowFileUpload",
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::{FILE}/{BUCKET}"
}
]
}
Note that "AllowFileUpload" encompasses both regular and multipart uploads.
(Multipart) uploads with federation tokens
Using federation tokens is so easy I don't even need a UML diagram this time 😉. From the API point of view, I just have to call STS' get_federation_token endpoint with the right parameters:
from uuid import uuid1
import boto3
EXPIRE_SECONDS = 3600 # 1h validity
class SomeAPIWithAWSAccess:
def __init__(self, bucket: str):
self.sts = boto3.client("sts")
self.bucket = bucket
def generate_federated_token(self, key: str):
name = f"upload-{uuid1()}"[:32]
bucket = "services-api-local-testing"
# The magic is here: the policy only allows file
# uploads to bucket/key.
policy = """{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowFileUpload",
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::{}/{}"
}
]
}""".format(
bucket,
key,
)
# Get the federation token
res = self.sts.get_federation_token(
Name=name,
Policy=policy,
DurationSeconds=EXPIRE_SECONDS,
)
# Return only the relevant information
return {
"access_key_id": res["Credentials"]["AccessKeyId"],
"access_key_secret": res["Credentials"]["SecretAccessKey"],
"session_token": res["Credentials"]["SessionToken"],
"expiration": res["Credentials"]["Expiration"].isoformat(),
"bucket": bucket,
"key": key,
}
The user (CLI) side can thus use boto3 to upload files:
import boto3
bucket = "my-bucket" # CHANGE_ME: bucket name
remote_location = "foo/data.dump" # CHANGE_ME: path in the bucket
local_file = "data.dump" # CHANGE_ME: file to upload
api = SomeAPIWithAWSAccess(bucket)
creds = api.generate_federated_token(remote_location)
boto3.client(
"s3",
# Use the creds to login to AWS
aws_access_key_id=creds["access_key_id"],
aws_secret_access_key=creds["access_key_secret"],
aws_session_token=creds["session_token"],
).upload_file(
# Upload the file
local_file,
creds["bucket"],
creds["key"],
)
Way easier. But what about multipart uploads? The beauty of this solution is that the boto3 s3 client takes care of everything. We can see this by looking at the upload_file TransferConfig options:
# Default options used by upload_file
TransferConfig(
# Automatically use multipart uploads for files >= 8M
multipart_threshold=8388608,
# Do uploads in parallel
use_threads=True,
# Use at most 10 threads
max_concurrency=10,
# Other transfer options
multipart_chunksize=8388608,
num_download_attempts=5,
max_io_queue=100,
io_chunksize=262144,
max_bandwidth=None,
)
And of course, AWS clients exist for other programming languages, so a user that does not use the CLI is not stuck with Python 😊.
Are federation tokens safe?
Contrary to a presigned URL, a user can log in to the AWS console with an access + secret key. However, since I attached a very restrictive policy to the federation token, it won't let him do or see anything (except menus). In other words, as long as the policy is sane, there is no security risk involved in returning a federation token to an untrusted user.
Conclusion
In this article, we looked at AWS presigned URLs, and how to make them work with multipart uploads. This is however complex and fails to deliver the desired advantages: parallel uploads and separate retries need to be coded on the client side.
We then looked at federation tokens, and how they make the whole process easier: the user can upload files to S3 using the AWS client, which takes care of all the heavy lifting. Moreover, the federation token has very limited permissions and expires after a while, making it as secure as presigned URLs.
With love, @derlin

Top comments (0)