
Data growth was a direct result of the popularity of the world wide web. Increased traffic on websites and web-based applications were also some of the factors. Web data collection began as an instrument for debugging web applications by analyzing log files and erroneous outputs. However, it was not limited to this as people started submitting information online by filling out sign-up forms or through simple web interactions.
During the 1990s, organizations started realizing this data’s potential, exploring other touchpoints, and using it to drive business decisions. This was when the era of data began. The era in which we are living today. But none of it has been that simple. Data and its processes have undergone significant transformations over the years, each of which came as a modernization requirement.
In this article, we will discuss conventional database systems, big data infrastructures, and the importance of ETL pipelines. We will also talk about the current state of data generation and the need for real-time processing and analytics. Finally, we will touch on the importance of data security and ETL pipelines in advanced applications such as Machine Learning.
Let’s start by discussing the idea behind the relational database, which has been the primary storage infrastructure for many years.
ETL: What and Why?
ETL stands for Extraction, Transformation, and Load.
These three terms describe the entire data life cycle from its generation to when it is finally stored in a secure infrastructure.
A data point starts its journey from the source from where it’s loaded. This data is then placed in a staging database where it goes under necessary transformations. These transformations include metadata correction and duplicate removals. Finally, it is moved to the central server, where multiple users can access it and use it in different locations.
Organizations have increasingly relied on data for insights and essential business decisions in the past decade. The growing data sources and volume have caused the remodeling of the data storage infrastructure. To accommodate the increasing traffic, IT firms have gone from maintaining databases to data warehouses and now data lakes. Still, one thing that has remained constant amongst this is the ETL pattern.
ETL for RDBMS
A Relational Database Management System (RDBMS) is a collection of programs that help administer and maintain all organizational databases.
Similar to a simple DBMS, RDBMS stores data in the form of tables. The latter offers an additional benefit by allowing users to create relations between tables that contain data generated from similar modules.
This is particularly useful due to the sheer volume of data that is generated on a daily basis. Storing this data in a single table causes storage, duplication, and query performance problems. An RDBMS is a highly optimized infrastructure that can generate data by linking multiple tables, especially during Adhoc executions and scheduled jobs.
The advent of RDBMS solved performance and data structuring problems but came as a challenge to database engineers. Due to the added complexity of multiple tables and relations, constructing ETL pipelines was challenging. A traditional ETL pipeline follows the following steps.
Connect the database system to all available data sources.
Load data into a staging area.
Apply relevant transformations and processing to the data.
Transfer cleaned data to the central database.
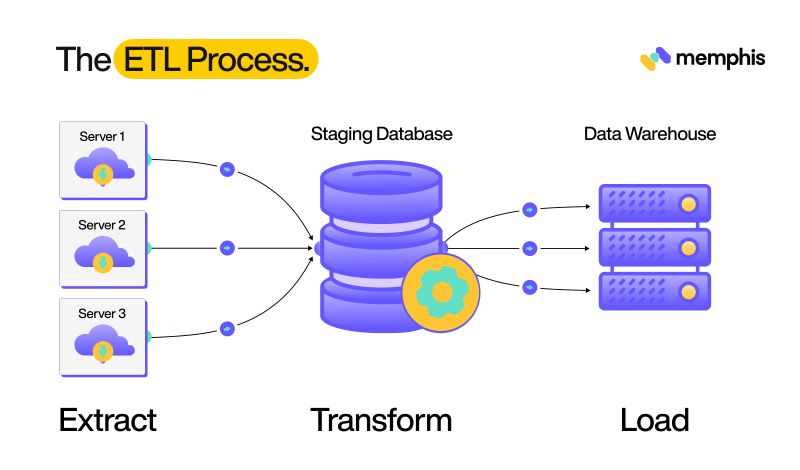
The challenge here is to carefully process data from each source. This is because different touch points require separate pipelines and unique processing methodologies. All tables should have a well-defined schema and be easily accessible to all authorized members. ETL processes also require constant testing to ensure data quality. These tests are mostly performed manually, which makes them very labor intensive and leaves room for human error.
So engineers did what they always do. Automation.
Let The Machine Do It
Many ETL automation tools are available today that handle the data life cycle. An ETL automation tool eliminates the need for manual coding. It provides a convenient way to design, execute, and monitor the performance of ETL integration workflows. Using such tools ensures smooth processes and consistent data quality and removes the burden from data engineers. Some standard ETL tools include:
Automation helps streamline processes, but another problem requires attention. You’ve got a good business going on, which means your data is still growing. With larger applications, information is usually scattered across multiple servers in multiple locations. Now, this isn’t useful! Connecting to various servers whenever you want a valuable dataset would be very inconvenient. So engineers thought, wouldn’t it be cool if all this data could come into one place–like a vast warehouse–and that’s exactly what they did.
Building Warehouses
A data warehouse contains all the data from within an organization and external sources. It acts as a single point of access for your data needs. It also improves speed and efficiency for accessing data sets and making it easier for corporate decision-makers to drive insights.
The ETL design pattern for a warehouse does not stray far from a regular database. Following the same pipeline, database management systems execute scheduled jobs across multiple servers. They load data in batches according to the defined rules and clauses.
All the data first makes its way to the staging database, which is normalized to ensure a consistent format throughout the warehouse. Once the standardization and quality checks are complete, data from multiple tables is joined according to business requirements and moved to the warehouse.
Building a data warehouse offers several benefits to an organization:
Data Consistency: It creates a standard for data format across the company. This makes it easier for employees to integrate it into their business use case.
Single Point Of View: It offers business managers a single view of the entire organization. They can query whatever data they like whenever they like for analysis or other purposes.
Brings Down Silos: Data silos within an organization act as a hindrance in business operation. Data warehouses unify all the data, making it easier for multiple teams to observe and analyze data from different parts of the organization.
So we have ETL automation and warehouses. Is that all? If only it were that simple. Until now, organizations only paid heed to relational data (in tables), but there were many other ventures to explore. This has brought new challenges such as volume and type of data. Data is generated in large quantities, and not all of this is structured.
Where RDBMS Fails…
Conventional database systems are designed to handle structured data only. Structured data refers to a group of information where each data point has a defined format. Here multiple data points can be linked to each other such as in tables.
However, data is generated through images, videos, audio clips, and text files. Such data is called unstructured data, and it contains essential information for businesses and needs a specialized database structured and ETL design pattern for ingestion. This is how the concept of Big Data was introduced.
Big Data: Go Big or Go Home
Enterprise giants such as Google or Microsoft generate data on numerous fronts. They deal with website user traffic and image and video uploads on cloud platforms. They also help stream audio and video feeds during live broadcasts.
All this information is a nightmare to manage for traditional databases, which is why engineers came up with the Big Data infrastructure. Big data allows users to dump all of their data into a central Data lake. This is done using various tools, different pipelines, and multi-node computing techniques, but more on these later.
Big data is a relatively newer concept defined by the following concepts:
Volume: Data is generated in Terabytes every day. Big data concepts specialize in dealing with such bulk quantities.
Velocity: The use of IoT devices is increasing exponentially. With more devices and hence more users, people interact online every second, which means data generates every second. Big data infrastructures utilize robust ETL pipelines that are purpose-built to handle such cases.
Variety: Data varies in types, including structured, semi-structured, and unstructured information.
Veracity: With multiple data sources and the volume and velocity of generation, it is vital to ensure the correctness of data and maintain its quality throughout the lifecycle. Big data requires special care for correctness and quality because if erroneous data enters the lake, it becomes challenging to debug.
Variability: Data can be used for several applications, such as user traffic analytics, churn rate prediction, or sentiment analysis.
The general rule is that if your business requirements and data state fulfill the above conditions, you need a different ETL pattern. Many cloud providers, including AWS and Azure, offer services for building data lakes.
These services provide a smooth setup and an easy-to-manage interface; however, Apache Hadoop remains the most common data lake-building tool.
Apache Hadoop is a Data lake architecture that comes bundled with many tools that help with Data Ingestion, Processing, Dashboarding, Analytics, and Machine Learning.
Some of its key components are:
HDFS
The Hadoop Distributed File System (HDFS) is a specialized storage system for Hadoop. HDFS stores data in a fault-tolerant manner by replicating it over multiple nodes. This allows protection against data loss in case one of the nodes fails. HDFS also offers easy integration with tools such as Spark for data processes.
Sqoop
HDFS is only a file system and requires an ETL pipeline to gather and store data. Apache Sqoop allows users to connect to an RDBM system and transfer relational tables into the distributed storage. With Sqoop, data engineers can configure several worker nodes for parallel processing and schedule jobs for timely ingestion.
Flume
While Sqoop connects structured data, Flume does the same for unstructured files. It uses distributed computing power of the Hadoop cluster to move extensive unstructured data into HDFS, such as images, videos, data logs, etc. Flume allows the processing of data in batches of streams in real-time. Recently real-time data streaming and analytics have gained much traction, and we’ll discuss those later in this article.
Spark
Apache spark is a data processing engine that supports multiple programming languages. It supports setup in mainstream languages like Java, Scala, Python, and R. It is a famous framework that uses distributed computing to perform tasks quickly. It can be used for data querying and analytics. Spark mainly utilizes advanced libraries for machine learning training, leveraging the power of distributed computation.
Piece Them Together
All these tools combined lay the groundwork for a successful data lake. Data within this lake can be accessed by multiple users across the organization, who can use it for their own individual goals.
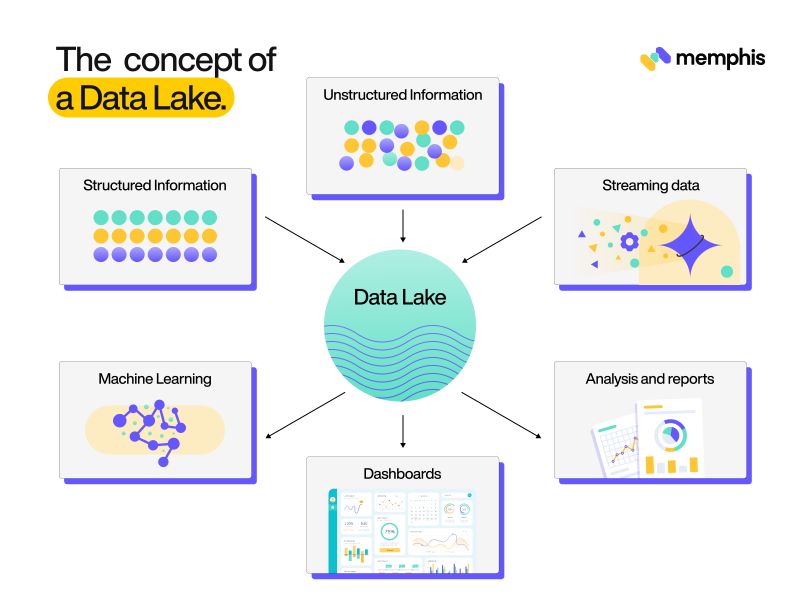
The concept of a Data Lake attracts many organizations. However, many fail to implement it or extract any benefits from it. This is because playing with tools like Hadoop requires expertise, and engineers need to be specifically trained for it.
Another important reason is that many organizations dive into construction without researching the use cases or realizing if they even need it or not.
Nevertheless, enterprises are still spending thousands of dollars every year to harness the power of their data because, let us face it, the struggle for data-driven processes started decades ago and will continue for many more. As time progresses, data only gets more extensive, and it only makes sense that organizations keep their ETL design patterns up-to-date.
From ETL to ELT
ETL has been the champion process for handling data, but there are specific concerns regarding its feasibility. In situations where you have enormous amounts to move, the step of data transformation (processing) can be costly. Applying schema standards, data correction, and data type conversions on millions of rows takes a toll on the server machine and take up a lot of time. Due to this, a few organizations have started experimenting with a new design pattern called ELT.
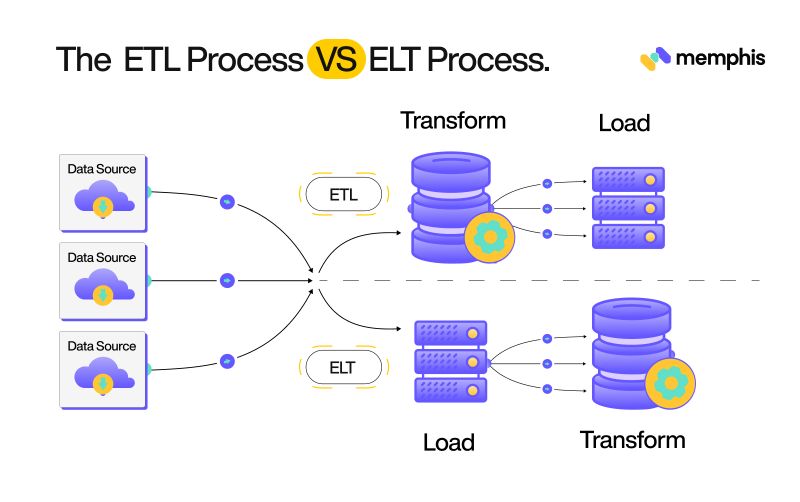
ELT stands for Extract, Load, and Transform. Sound familiar? This is precisely how ETL works. But, instead of transforming data before loading, data is ingested in its raw form and later transformed according to requirements. The use of the ELT design pattern is still under debate and experimentation as it trades blows with ETL. It is difficult to overlook some of the benefits the latter brings. Some of the benefits of ELT are:
Low-Cost Operations: Since data is loaded in raw form, no additional processing is required to cut the cost on servers.
Data Analysis Flexibility: Having raw data means users have higher flexibility regarding how they want to transform the data and what structure the final data should be in.
Integration With Data Lakes: Data lakes usually contain unprocessed raw data, making the ELT design pattern suitable for this use case.
Despite these benefits, many organizations still choose to stick with ETL because of its mature ecosystem and the assurance of data quality prior to ingestion.
On the topic of ETL patterns, there’s a new kid in town. Well, not exactly new per se but more on the lines of being a modern requirement. Earlier, we briefly touched on ETL designs for real-time data streams. Well, let us take a deeper look.
ETL Design Pattern for Real-Time Data Processing
The velocity of data generation made real-time data processing a necessity. While batch processing does the job on many occasions, there are specific applications where it makes sense to analyze real-time results.
Let us take the example of user logs from web applications.
These logs collect information regarding page visits, page loading times, and application crashes. If such data is processed in batches, developers can only analyze the results the following day.
This may seem alright initially but is damaging for business as many clients require instant fixes and restoration. Such acts can increase user churn and damage reputation.
Many organizations choose ETL patterns that accommodate real-time log streaming. These dashboards notify developers when a bug requires immediate attention. Real-time data processing also holds importance for machine-learning-based applications such as credit card fraud detection.
When an abnormal transaction occurs, the data from the transaction is instantly streamed to the processing servers. This happens so ML models can make their predictions and the authorities can take timely action. ETL pipelines for real-time processing usually run in parallel but are independent of standard data pipelines.
This is so as real-time processing requires reliable, uninterrupted computation power. We have already discussed how Apache flume can be used for streaming data. However, many organizations opt for cloud-based streaming platforms such as:
Services offered by these cloud platforms are all paid. Luckily the open-source community is not behind in the ETL space. Providers such as Memphis provide cloud-agnostic, real-time data streaming and processing with queued task management and analysis in a serverless environment.
Think Ahead: Future Proof Your Data Pipelines
By this point, we have already established the need and importance of robust and reliable ETL pipelines. However, there is one last important point to discuss. The IT industry has flourished over the past decades. If there’s one thing the pioneers will teach you, it is the importance of growing with the changing times.
Many industries have faltered simply because they have become outdated and cannot keep up with the competition.
The same rules apply to data and ETL pipelines. Your data infrastructure needs to be scalable, and the pipelines must be flexible enough to fit into changing business needs. Right now, you may only be dealing with structured data, and your channels will be designed accordingly. However, it would not be unwise to be ready for the possibility of exploring unstructured data touchpoints. It would be handy if the overall data infrastructure is flexible enough to accommodate this additional requirement.
Furthermore, data streaming and real-time processing are already a requirement yet many organizations are not utilizing them. With growing business and user traffic, batch processing will be unable to keep up, and implementing real-time processing pipelines or cloud services like Memphis will be the way forward
Although it is not impossible to upgrade the overall structure, later on, it comes at a huge monetary and business cost. The entire legacy system would need to be stripped down and built from the ground up. A more reasonable solution would be to build ETL pipelines on cloud infrastructures like those provided by Memphis.dev.
Build with Memphis
Memphis is an open-source real-time data processing platform that is purpose-built for data streaming applications. Memphis.dev started as a fork of the nats.io project (since 2011), written in GoLang, and creating its own stream on top. Instead of topics and queues, Memphis uses stations, which will become an entity with embedded logic in the future. Memphis leverages the power of containerization and natively runs on Kubernetes and Docker clusters.
Constructing your data pipelines with Memphis provides the following benefits:
Enhanced performance with cache usage.
Outstanding DevEx
A 99.9% uptime
Out-of-the-box observability for easy troubleshooting
Modularity, inline processing, schema management, gitops abilities
For the developers out there, you can visit our GitHub repository, with over 250 stars, for further analysis. Still not sure how to begin? Our documentation offers an easy setup guideline, and our discord community is always here to help.
Join 4500+ others and sign up for our data engineering newsletter
Follow Us to get the latest updates!
Github • Docs • Discord
Originally published at Memphis.dev by Sveta Gimpelson Co-founder and VP of Data & Research at Memphis.dev



Top comments (9)
Thanks for sharing my article :)
Hey @avital_trifsik!
@ellativity can show you how to manage posts for memphis.dev so that the original authors like @sveta_gimpelson get the byline credit.
You can also get new posts from your memphis.dev blog to automatically populate via RSS as drafts in your Dashboard.
I would love that!
Awesome, @avital_trifsik! I've created an FAQ document here that might help answer your questions.
In particular, I recommend reviewing the instructions under 3. I want to cross-post content, do you support Canonical URLs?
Just let me know if you run into any issues!
Thank you!
My aim was to buy a professional microscope for my son’s science projects. A string of bad luck on other sites was disheartening. I increased my stake on a simple 3-reel slot, and it landed three jackpot symbols. The microscope is now on his desk. That moment happened on spinmacho. The site navigation is intuitive, making it easy to find new games. For players from Germany, they have a dedicated VIP manager program for high rollers. It provided a fantastic solution to a specific goal.
Hey, after a long shift I was scrolling through a forum when I saw someone casually mention a new gaming platform, so I decided to check it out myself. I signed up, tried a few rounds, and immediately hit a series of small losses that drained my balance. While exploring spinogambino I noticed the welcome bonuses for all new players and used them to extend my session. I raised the stake slightly and triggered a feature round that covered everything. That turnaround made the night feel much better.
Thanks for the great article! I also wanted to share an interesting resource I came across about ETL & ELT.
Some comments may only be visible to logged-in visitors. Sign in to view all comments.