
Introduction
Hi, I am Akshay Rao.
While working with Kubernetes, i had a question how does the deployment make a pod, even in the yaml file, the kind we don't mention the as pod then also the pod is created, i researched and understood how it actually it works.
Let's Start
For this flow to understand we need to understand the controllers in the k8s.
every controller has a 2 component:-
- Informers keep an eye on the desired state of resources in a scalable and sustainable manner. They also have a resync mechanism, which enforces periodic reconciliation and is frequently used to ensure that the cluster state and the assumed state cached in memory do not drift (due to faults or network issues.
- Work queue is essentially a component that may be utilized by the event handler to handle the queuing of state changes and aid in the implementation of retries. This feature is accessible in client-go via the work queue package. Resources can be requeued if there are mistakes when updating the world or publishing the status, or if we need to evaluate the resource after a period of time for various reasons. we have understood the controller components, now we will see the pods creation flow.
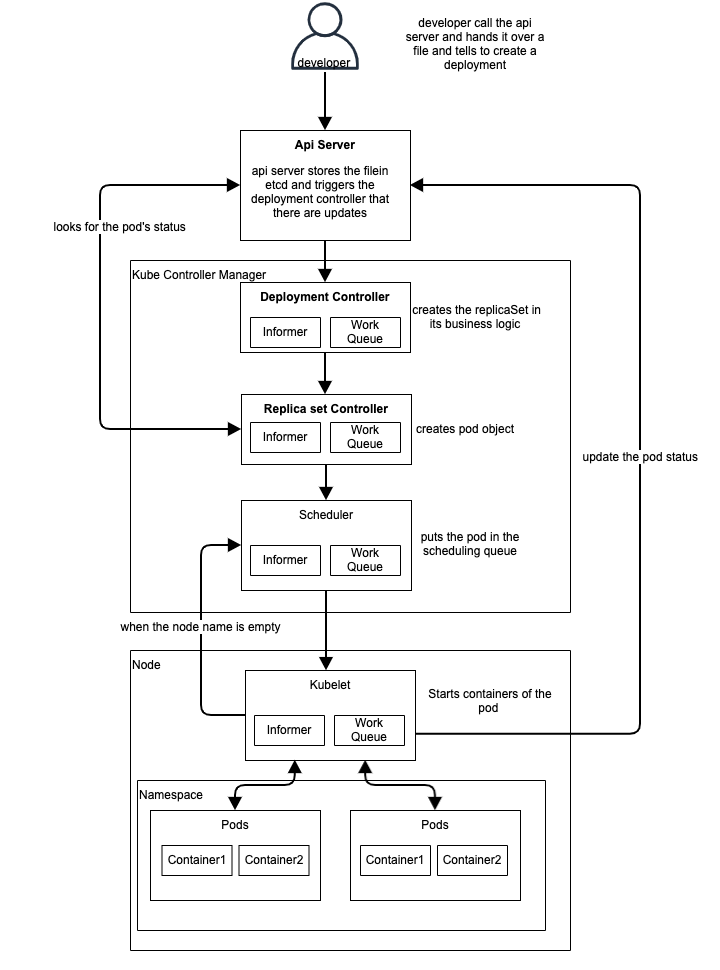
- The deployment controller (located within kube-controller-manager) detects (through a deployment informer) that the user has created a deployment. In its business logic, it generates a replica set.
- The replica set controller (again, inside kube-controllermanager) observes the new replica set (through a replica set informer) and executes its business logic, which generates a pod object.
- The scheduler (within the kube-scheduler binary), which is also a controller, observes the pod with an empty spec.nodeName field (through a pod informer). Its business logic queues the pod for scheduling.
- Meanwhile, another controller, the kubelet, observes the new pod (via its pod informer). However, the new pod's spec.nodeName field is empty, therefore it does not match the kubelet's node name. It ignores the pod and returns to sleep until next event is triggered.
- The scheduler removes the pod from the work queue and assigns it to a node with appropriate spare resources by modifying the pod's spec.nodeName field and writing it to the API server.
- The kubelet re-wakes as a result of the pod update event. It compares the spec.nodeName to its own node name once again. Because the names match, the kubelet launches the pod's containers and informs back to the API server that the containers have been launched by writing this information into the pod status.
- The replica set controller observes the modified pod but is powerless to intervene.
- The pod eventually comes to an end. The kubelet will detect this, retrieve the pod object from the API server, set the "terminated" condition in the pod's status, and return it to the API server.
- When the replica set controller observes the terminated pod, he determines that it must be replaced. It removes the terminated pod from the API server and replaces it with a fresh one.
- And so on.
Thus this ishow the pods are created via deployments.
I hope this has brough some clarity.
Thank you

Top comments (0)